HI..
Netezza is one of the widely used MPP databases. You connect to it by using various methods and programming languages. Netezza supports ODBC, OLEDB, and JDBC drivers for connections. Connection to Netezza using a JDBC driver is easy and one of the widely used methods. In this article, we will check how to connect Netezza using JDBC driver and some working examples.
Netezza JDBC Driver
Netezza provides a JDBC driver, you can use that driver from any programming language that supports JDBC connections such as Java, Python, etc. You can download the JDBC driver from IBM to fix the central site. You should have a JDBC jar by the name nzjdbc.jar.
Alternatively, you will get software packages if you purchase Netezza or IBM PureData Systems for analytics.
Before going deep into using Netezza JDBC driver, you need to install jaydebeapi module into python. Though you can use any module that supports JDBC drivers, jaydebeapi is one of the easy module that I have been using.
Install Jaydebeapi
The JayDeBeApi module allows you to connect from Python code to databases using Java JDBC. It provides a Python DB-API v2.0 to that database.
You can install it using pip:
pip install Jaydebeapi
Set CLASSPATH to Driver Location
As we have no other dependent jar for this Netezza JDBC driver, you can directly refer to this driver in your jaydebeapi module. Alternatively, you can export jar location to the CLASSPATH shell variable and run your python program without needing to set jar location in your module.
How to Connect Netezza using JDBC Driver?
In this section, we will discuss how can we connect Netezza using JDBC driver. I will be using python and jaydebeapi to execute the Netezza JDBC driver.
Once you have Netezza jar in place and installed the required modules, you are ready to access Netezza from within your Python program using a JDBC driver.
Note that, Netezza JDBC driver class name is “org.netezza.Driver“
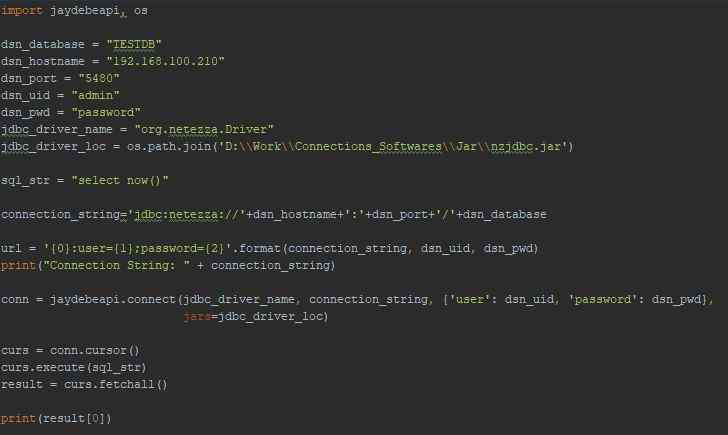
Here is the code that can help you:
import jaydebeapi, os
dsn_database = "TESTDB"
dsn_hostname = "192.168.100.210"
dsn_port = "5480"
dsn_uid = "admin"
dsn_pwd = "password"
jdbc_driver_name = "org.netezza.Driver"
jdbc_driver_loc = os.path.join('D:\\Work\\Connections_Softwares\\Jar\\nzjdbc.jar')
sql_str = "select now()"
connection_string='jdbc:netezza://'+dsn_hostname+':'+dsn_port+'/'+dsn_database
url = '{0}:user={1};password={2}'.format(connection_string, dsn_uid, dsn_pwd)
print("Connection String: " + connection_string)
conn = jaydebeapi.connect(jdbc_driver_name, connection_string, {'user': dsn_uid, 'password': dsn_pwd},
jars=jdbc_driver_loc)
curs = conn.cursor()
curs.execute(sql_str)
result = curs.fetchall()
print(result[0])
Here is the sample output:
URL: jdbc:netezza://192.168.100.210:5480/TESTDB:user=admin;password=password
Connection String: jdbc:netezza://192.168.100.210:5480/TESTDB
('2018-12-02 06:08:32',)


























