
Spark uses a master/slave architecture. As you can see in the figure, it has one central coordinator (Driver) that communicates with many distributed workers (executors). The driver and each of the executors run in their own Java processes.
DRIVER
The driver is the process where the Main method runs. First, it converts the user program into tasks and after that, it schedules the tasks on the executors.
EXECUTORS
Executors are worker nodes' processes in charge of running individual tasks in a given Spark job. They are launched at the beginning of a Spark application and typically run for the entire lifetime of an application. Once they have run the task they send the results to the driver. They also provide in-memory storage for RDDs that are cached by user programs through Block Manager.
APPLICATION EXECUTION FLOW
With this in mind, when you submit an application to the cluster with spark-submit this is what happens internally:
=> A standalone application starts and instantiates a SparkContext instance (and it is only then when you can call the application a driver).
=> The driver program ask for resources to the cluster manager to launch executors.
=> The cluster manager launches executors.
=> The driver process runs through the user application. Depending on the actions and transformations over RDDs tasks are sent to executors.
=> Executors run the tasks and save the results.
=> If any worker crashes, its tasks will be sent to different executors to be processed again.
=> With SparkContext.stop() from the driver or if the main method exits/crashes all the executors will be terminated and the cluster resources will be released by the cluster manager.
In case of failures,
Spark automatically deals with failed or slow machines by re-executing failed or slow tasks. For example, if the node running a partition of a map() operation crashes, Spark will rerun it on another node; and even if the node does not crash but is simply much slower than other nodes, Spark can preemptively launch a “speculative” copy of the task on another node, and take its result if that finishes.
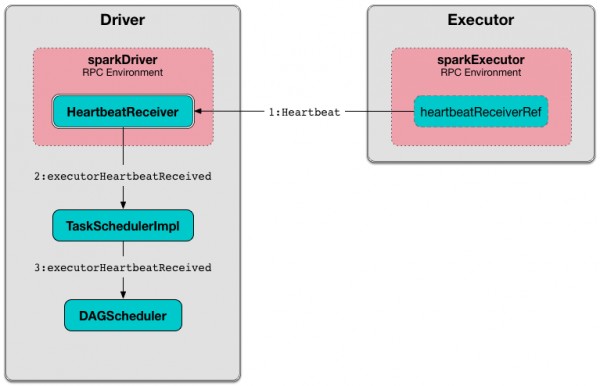
Executors report heartbeat and partial metrics for active tasks to HeartbeatReceiver on the driver. By default, Interval after which an executor reports heartbeat and metrics for active tasks to the driver. is 10 seconds.
I hope this helps. Jimmy


























