Let me explain to you about Apache Kafka in brief.
Apache Kafka is a distributed publish-subscribe messaging system which was originally developed at LinkedIn and later on became a part of the Apache project. Kafka is fast, agile, scalable and distributed by design which has the following components.
- Zookeeper
- Producer
- Consumer
- Broker
Apache ZooKeeper is a software project of the Apache Software Foundation. It is essentially a centralized service for distributed systems to a hierarchical key-value store, which is used to provide a distributed configuration service, synchronization service, and naming registry for large distributed systems.
Producer:
A producer can be any application that can publish messages to a topic.
Consumer:
A consumer can be any application that subscribes to topics and consumes the messages.
Broker:
Kafka cluster is a set of servers, each of which is called a broker.
What’s the role of ZooKeeper?
Each Kafka broker coordinates with other Kafka brokers using ZooKeeper. Producers and Consumers are notified by the ZooKeeper service about the presence of new brokers or failure of the broker in the Kafka system.
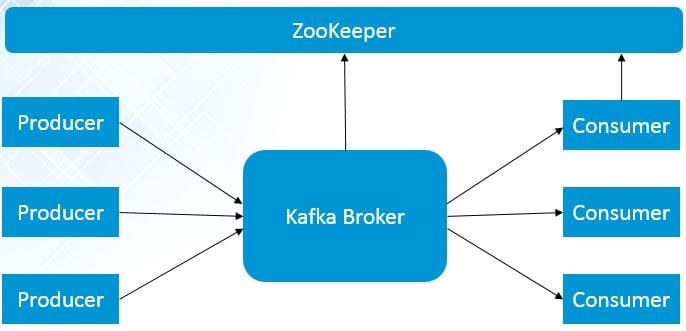
Single Node Single Broker
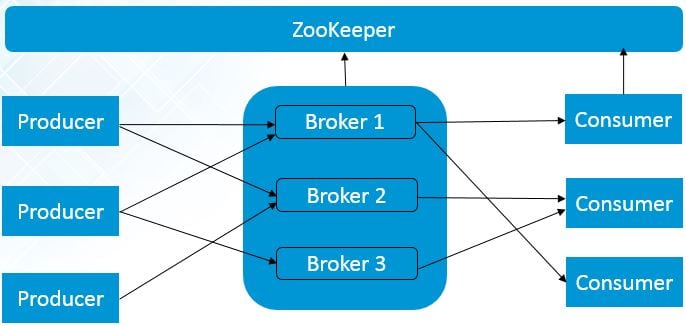
Single Node Multiple Brokers
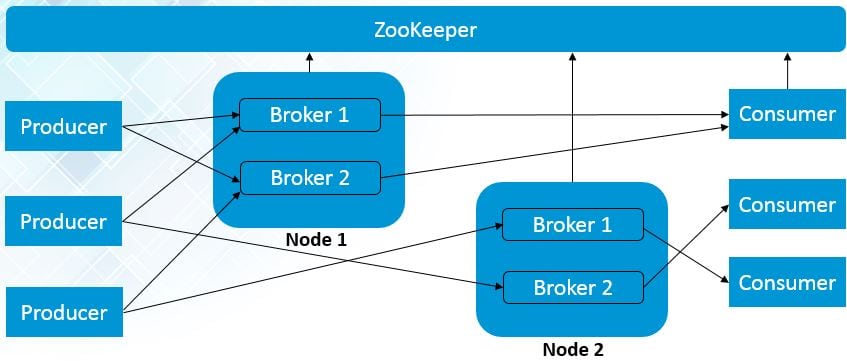 Multiple Nodes Multiple Brokers
Multiple Nodes Multiple Brokers


























