In my previous blog, I explained Splunk Events, Event types and Tags that help in simplifying your searches. In this blog, I am going to explain the following concept – Splunk lookup, fields and field extraction.
I will discuss why lookups are important and how you can associate data from an external source by matching the unique key value. On the other hand, Splunk fields help in enriching your data by providing a specific value to an event. I have also explained how these fields can be extracted in different ways.
So, let’s get started with Splunk Lookup.
Splunk Lookup
You might be familiar with lookups in Excel. Splunk lookup work in a similar fashion. For example, you have a product_id value which matches its definition in a different file, say a CSV file. Lookup can help you to map the details of the product in a new field. Suppose you have product_id=2 and the name of the product is present in a different file, then Splunk lookup will create a new field – ‘product_name’ which has the ‘product_id’ associated with it.
- A lookup table is a mapping of keys and values.
- Splunk Lookup helps you in adding a field from an external source based on the value that matches your field in the event data.
- It enriches the data while comparing different event fields.
- Splunk lookup command can accept multiple event fields and destfields.
- It can translate fields into more meaningful information at search time.
If you see the image below, these are the different types of Splunk lookup which I will be explaining in detail below.
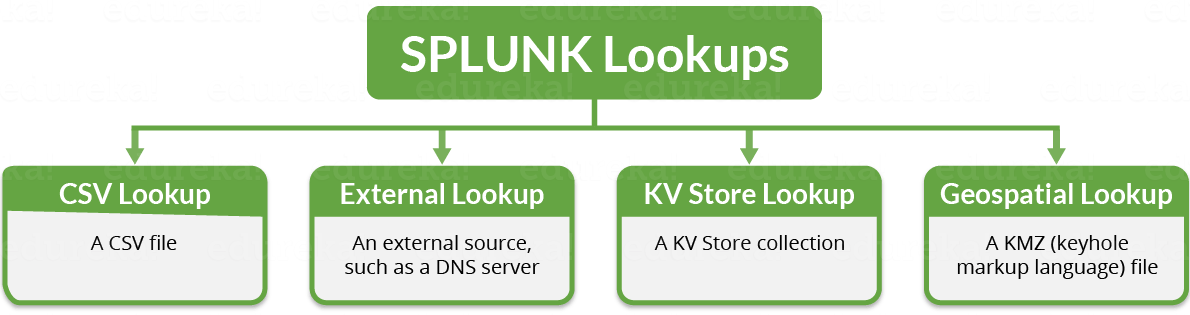
- CSV Lookup: As the name itself says, a CSV lookup pulls data from CSV files. It populates the event data with fields and represents it in the static table of data. Therefore, it is also called as a “static lookup”. There must be at least two columns representing field with a set of values. They can have multiple instances of the same value.
- External Lookup: In this type of lookup, it populates your event data from an external source, say a DNS server. It can use Python scripts or binary executable to get field values from an external source. Therefore, it is also called as “Scripted lookup”.
- KV Store Lookup: In this type of lookup, it populates your event data with fields pulled from your App Key Value Store (KV Store) collections. This lookup matches the fields in your event to fields in a KV store.
- Geospatial Lookup: In this type of lookup, the data source is a KMZ (compressed keyhole markup language) file which is used to define boundaries of mapped regions such as US states and US counties. It matches your events in a KMZ file and outputs fields to your event encoded in a KMZ, like country, state or county names.

You can configure Splunk lookups by:
Settings -> Lookups
Once you click on ‘Lookups’, a new page will be displayed saying ‘Create and configure lookups’.
You can create new lookups or edit the existing lookups.
Refer to the screenshot on the left to get a better understanding on how to create Splunk lookup.
There are 3 ways to create and configure Splunk lookups:
- Lookup table files
- Lookup definitions
- Automatic lookups
Let us get into more details and understand these different ways:
1. Lookup table files: In lookup table files, you can simply upload a new file.
When you click on ‘Add new’ view, you can upload CSV files to use in your field lookups.
To create a lookup table file, you need to follow the below steps:
» Go to Lookups page
» Open Lookups table files
» Click Add new
» Upload a lookup file, browse for the CSV file (product.csv) to upload.
» Under Destination filename, name the file product.csv
Refer to the below screenshot to get a better understanding.

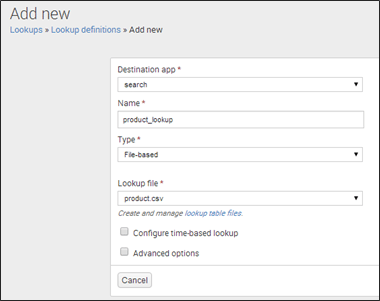
2. Lookup definitions: Lookup definitions help to edit existing lookup definitions or define a new file-based lookup. While defining a lookup, you can reuse the same file, and later make that lookup run automatically.
To create a lookup definition, you need to follow the below steps:
» Go to Lookups page
» Open Lookups definitions
» Click ‘Add new’
» A new box will open to add field definition
» Provide the name of the lookup
» Set the Type as ‘File-based’
» Select the name of the lookup file (product.csv)
Refer to the below screenshot to get a better understanding.
3. Automatic lookups: Automatic lookup helps to configure a new lookup to run automatically or edit an existing one.
To create an automatic lookup, you can go through the below steps:
» Go to Lookups page
» Open Automatic Lookups
» Click Add new
» A new box will open to add Automatic lookup
» Provide the name for the Automatic Lookup
» Under Lookup tables, select product_lookup
» Select lookup input and output fields.
Refer to the below screenshot to get a better understanding.

There are two important search commands to create a Splunk Lookup – Input and Output lookup. These are explained below.
Input Lookup: Inputlookup command loads the search results from a specified static lookup table. It scans the lookup table as specified by a filename or a table name. If “append’ is set to true, the data from the lookup file will be appended to the current set of results. For example: Read the product.csv lookup file.
| inputlookup product.csv
Outputlookup: Outputlookup command writes the search results to the specified static lookup table. It saves the result to a lookup table as specified by a filename or a table name. If “createinapp” option is set to false or if there is no current application, then Splunk creates the file in the system lookups directory. For example: Write to product.csv lookup file.
| outputlookup product.csv
By now, you would have understood how Splunk lookups are created. Next, I will explain Splunk fields and how these fields can be extracted to enrich your data.
Splunk Fields
Suppose you have a large amount of data for a company and you need an easy way to access information in key=value pair. Let’s say you want to identify the name of a particular employee or want to find the employee ID. For this, we can declare a Splunk field such as Emp_name or Emp_ID and associate a value to it.
For example: Emp_name= “Jack” or Emp_ID= ‘00124’
- Fields are the searchable names in the event data.
- Fields filter the event data by providing a specific value to a field.
- Fields are the building blocks of Splunk searches, reports, and data models.
- A field can have multiple values. It can appear more than once having different values each time.
- Field names are case-sensitive.
Let us now understand how fields can be extracted.
Splunk Field Extraction: The process of extracting fields from the events is Splunk field extraction. There are some fields which are extracted by default such as: host, source, sourcetype and timestamps.
I will explain with an easy example to understand this process properly.

As you can see in the above example, it displays the event data. In this case, I have taken any sample event and kept the source type as ‘splunk_web_access’. Now Splunk Enterprise will extract fields based on the data collected by the sourcetype.
In the above example, I have opted regular expression which helps to match the highlighted value in the sample events. Now, I have extracted value ‘537.36’ and given the field name as ‘test’. This will display the set of values and extracted values.
Let’s look at how these extracted values are displayed.

Now, there are two types of field extractions depending on when Splunk extracts fields:
- Index Time Field Extraction (in case of default fields)
- Search Time Field Extraction (in case of search fields)
Let us go into more detail to understand it properly:
| Index Time Field Extraction | Search Time Field Extraction |
| 1. Index time field extraction happens at the index time when Splunk indexes data. | 1. Search time field extraction happens at the search time when we search through data. |
| 2. You can define custom source types and host before indexing, so that it can tag events with them. | 2. You cannot change the host or source type assignments. |
| 3. Splunk extracts a set of default fields for each event like host, source and sourcetype. It also includes static or dynamic host assignment, structured data field extraction, custom-index time field extraction, event timestamping etc. | 3. Splunk can extract additional fields other than default fields depending on its search settings. It includes event type matching, search-time field extraction, addition of fields from lookup, event segmentation, field aliasing, tagging etc. |
Next, there are 3 ways in Splunk to achieve field extraction.
- Using Field Extractor Utility
- Using Field Extractions Page in Splunk Web
- Using Field extractions directly in .conf files
These three are explained in detail below:
1. Using Field Extractor Utility: You can use the field extractor utility to create new fields Also, it is used to create custom fields dynamically in your Splunk instance.
- The field extractor enables you to define field extraction by selecting a sample event and highlighting fields to extract from that event.
- It provides two methods to extract a field – regular expression and delimiters. The regular expression method works best with unstructured event data, whereas delimiters are designed for structured event data.
- The field extractor utility is useful if you are not familiar with regular expression syntax and usage, because it generates field-extracting regular expressions and allows you to test them.
Refer to the below screenshot to get a better understanding.
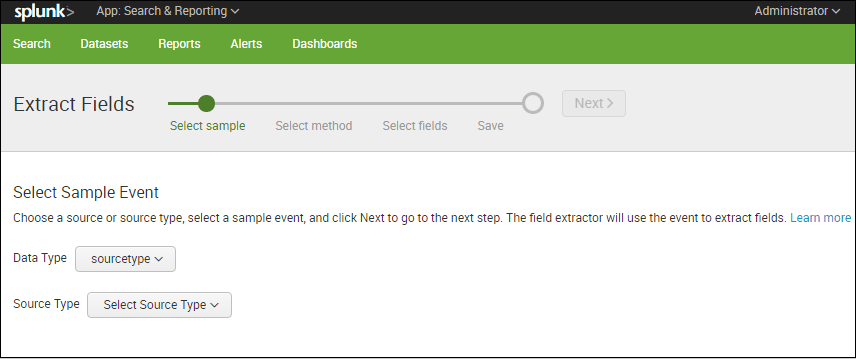
2. Using Field Extractions Page in Splunk Web: We can use the ‘Field Extractions Page’ to manage search-time field extractions.
The Field Extractions page enables us to:
- Review the overall set of search-time extractions.
- Create new search-time field extractions.
- Update permissions for field extractions.
- Delete field extractions
Let’s see how we can access Field extraction page in Splunk Web:
Go to Settings -> Fields -> Field Extractions
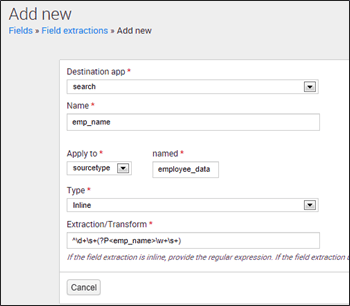
In the above screenshot, I have explained how the employee name field is extracted from employee_data sourcetype. You can use the following regular expression to extract emp_name field:
^d+s+(?P<emp_name>w+s+)
Also, you can generate this regular expression from field extractor utility if you don’t know how to create regular expressions.
3. Using Field extractions directly in .conf files: You can also extract fields by directly editing props.conf and transforms.conf files.You can find them in: $SPLUNK_HOME/etc/system/local/
NOTE: Do not edit files in $SPLUNK_HOME/etc/system/default/ as it includes System settings, Authentication and authorization information,Index mappings and various other important settings.
So, this was all about Splunk Knowledge Objects. I hope these blogs helped you learn different knowledge objects and the role it plays in bringing operational efficiency to your business. Check out the next tutorial blog which explains the three concepts that every Splunk administrator must know at his fingertips – Licensing, Data ageing and Configuration files.
Do you wish to learn Splunk and implement it in your business? Check out our Splunk certification training here, that comes with instructor-led live training and real-life project experience.