





Python provides a huge number of libraries to work on Big Data. You can also work – in terms of developing code – using Python for Big Data much faster than any other programming language. These two aspects are enabling developers worldwide to embrace Python as the language of choice for Big Data projects. To get in-depth knowledge on Python along with its various applications, you can enroll for live Python online training with 24/7 support and lifetime access.
🐍 Ready to Unleash the Power of Python? Sign Up for Edureka’s Comprehensive Python Online Certificate Course with access to hundreds of Python learning Modules and 24/7 technical support.
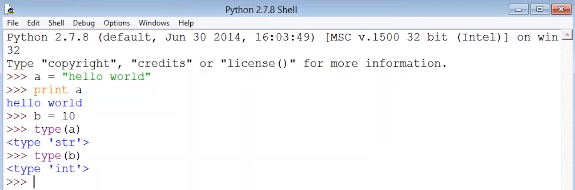
It is extremely easy to handle any data type in python. Let us establish this with a simple example. You can see from the snapshot below that the data type of ‘a’ is string and the datatype of ‘b’ is integer. The good news is that you need not worry about handling the data type. Python has already taken care of it.
Now the million-dollar question is; Python with Big Data or Java with Big Data? You can learn all about Big Data from the Hadoop Certification.
I would prefer Python any day, with big data, because in java if you write 200 lines of code, I can do the same thing in just 20 lines of code with Python. Some developers say that the performance of Java is better than Python, but I have observed that when you are working with huge amount of data (in GBs, TBs and more), the performance is almost the same, while the development time is lesser when working with Python on Big Data.
The best thing about Python is that there is no limitation to data. You can process data even with a simple machine such as a commodity hardware, your laptop, desktop and others.
Python can be used to write Hadoop MapReduce programs and applications to access HDFS API for Hadoop using the PyDoop package
One of the biggest advantage of PyDoop is the HDFS API. This allows you to connect to an HDFS installation, read and write files, and get information on files, directories and global file system properties seamlessly. You can get a better understanding with the Microsoft Azure Data Engineering Certification Course (DP-203)
The MapReduce API of PyDoop allows you to solve many complex problems with minimal programming efforts. Advance MapReduce concepts such as ‘Counters’ and ‘Record Readers’ can be implemented in Python using PyDoop.
In the example below, I will run a simple MapReduce word-count program written in Python which counts the frequency of occurrence of a word in the input file. So we have two files below – ‘mapper.py’ and ‘reducer.py’, both written in python.
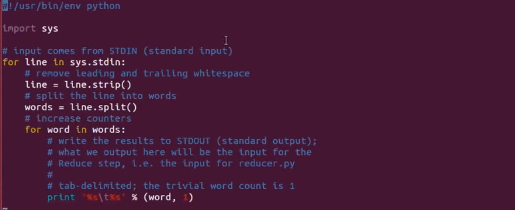
Fig: mapper.py
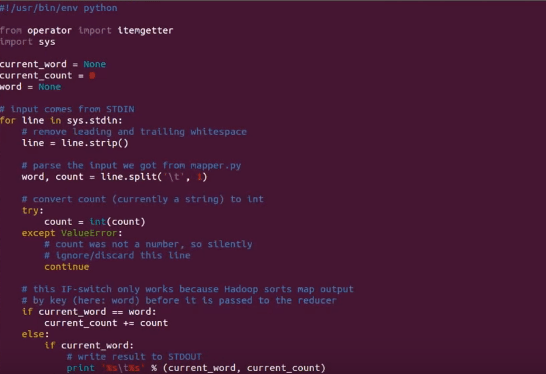

Fig: reducer.py

Fig: running the MapReduce job

Fig: output
This is a very basic example, but when you are writing a complex MapReduce program, Python will reduce the number lines of code by 10 times as compared to the same MapReduce program written in Java. You can even check out the details of Big Data with the Azure Data Engineering Training in London.
Why Python makes sense for Data Scientists
The day-to-day tasks of a data scientist involves many interrelated but different activities such as accessing and manipulating data, computing statistics and creating visual reports around that data. The tasks also include building predictive and explanatory models, evaluating these models on additional data, integrating models into production systems, among others. Python has a diverse range of open source libraries for just about everything that a Data Scientist does on an average day.
SciPy (pronounced “Sigh Pie”) is a Python-based ecosystem of open-source software for mathematics, science, and engineering. There are many other libraries which can be used.

The verdict is, Python is the best choice to use with Big Data. Learn more about Big Data from the Hadoop training in Bangalore.
Got a question for us? Please mention them in the comments section and we will get back to you.







































Good article
Hi White Ninja,
Thank you for your positive feedback. We hope that you will find our blog useful in future as well.
Keep visiting the Edureka Blog page for latest posts on this link: https://www.edureka.co/blog/