





The above video is the recorded session of the webinar on the topic “Hadoop for Data Warehouse Professionals”, which was conducted on 31st May’14.
Why should a Data Warehouse professional move to Big Data & Hadoop?
All Data Warehousing folks out there, are you aware of Hadoop and the Data warehousing paradigm? Do you realize how important it is to know about the Big Data Hadoop Certification, as Data Warehouse professionals? If the answer is ‘Yes’, then you can read this post to endorse your awareness. If ‘No’, then read ahead:
Let us quickly look at the paradigm shift of Data Warehouse and Hadoop.
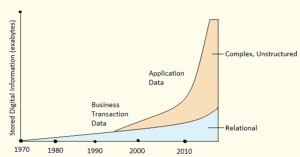
Organizations across all industries are growing extremely fast, resulting in high volume, complex and unstructured data. The huge data generated is limiting the traditional Data Warehouse system, making it tougher for IT and data management professionals to handle the growing scale of data and analytical workload. The flow of data is so much more than what the existing Data Warehousing platforms can absorb and analyze. Looking at the expenses, the cost to scale traditional Data Warehousing technologies are high and insufficient to accommodate today’s huge variety and volume of data. Therefore, the main reason behind organizations adopting Hadoop is that, it is a complete open-source data management system. Not only does it organize, store and process data (whether structured, semi-structured or unstructured), it is cost effective as well.
Watch our Presentation on Hadoop’s role in Data Warehousing:
Hadoop’s role in Data Warehousing:
Hadoop’s role in Data Warehousing is evolving rapidly. Initially, Hadoop was used as a transitory platform for extract, transform, and load (ETL) processing. In this role, Hadoop is used to offload processing and transformations performed in the data warehouse. This replaces an ELT (extract, load, and transform) process that required loading data into the data warehouse as a means to perform complex and large-scale transformations. With Hadoop, data is extracted and loaded into the Hadoop cluster where it can then be transformed, potentially in near-real time, with the results loaded into the data warehouse for further analysis.
Offloading transformation processing to Hadoop frees up considerable capacity in the data warehouse, thereby postponing or avoiding an expensive expansion or upgrade to accommodate the relentless data deluge.
Hadoop has a role to play in the “front end” of performing transformation processing as well as in the “back end” of offloading data from a data warehouse. With virtually unlimited scalability at a per-terabyte cost that is more than 50 times less than traditional data warehouses, Hadoop is quite well-suited for data archiving. Because Hadoop can perform analytics on the archived data, it is necessary to move only the specific result sets to the data warehouse (and not the full, large set of raw data) for further analysis. The best way to become a Data Engineer is by getting the Data Engineering Training in Singapore.
Appfluent, a data usage analytics provider calls this the “Active Archive” — an oxymoron that accurately reflects the value-added potential of using Hadoop in today’s data warehousing environment. They have found that for many companies, about 85 percent of their tables go unused, and that in the active tables, up to 50 percent of the columns go unused. The combination of eliminating “dead data” at the ETL stage and relocating “dormant data” to a low-cost Hadoop Active Archive can be considerable, resulting in truly extraordinary savings.
Hadoop’s original MapReduce framework — purpose-built for large-scale parallel processing — is also eminently suitable for data analytics in a data warehouse.
Hadoop effectively makes ETL integral to, and seamless with, data analytics and archival processing. It is this beginning-to-end role in Data Warehousing that has given impetus to what is Hadoop’s ultimate role as an enterprise data management hub in a multi-platform data analytics environment
Now that we have understood the Hadoop and Data Warehousing paradigm, let us get to know why Data Warehouse professionals should move to Big Data and Hadoop.
With the numerous benefits offered by Hadoop, all leading organizations are moving their data management system from the traditional Data Warehousing to Big Data and Hadoop. When considering Data Warehousing as a career, it is better to be updated with the latest trends and products of database management. Hadoop will not replace relational databases or traditional Data Warehouse platforms at the moment, but its superior price/performance ratio will give organizations an option to lower costs while maintaining their existing applications and reporting infrastructure. Saying this, it leaves loads of possibility for Hadoop to take over the duties of a traditional Data Warehouse in the near future. You can even check out the details of Big Data with the Data Engineering Courses online
How will Hadoop help you as a Data Warehousing professional?
- Hadoop simplifies your job as a Data Warehousing professional. With Hadoop, you can manage any volume, variety and velocity of data, flawlessly and comparably in less time.
- As a Data Warehousing professional, you will undoubtedly have troubleshooting and data processing skills. These skills are sufficient for you to be a Hadoop-er.
Learn more about Big Data, Hadoop and its concepts from the Big Data Course in Ahmedabad.
The other reasons are:
- Hadoop technology is certainly a mega trend in the IT industry. As a techie, I am sure you will find Hadoop interesting to learn.
- If your company has not currently implemented Hadoop, it does not mean it never will. If you manage to learn Hadoop beforehand, you can be an internal Hadoop and Big Data expert.
- Hadoop and Big Data have BIG opportunities and real potential to enhance your career in the data management sector.
- Hadoop codes are short and simple, so you can learn them very easily.
So, why not make it Big with Big Data and Hadoop?
Got a question for us? Please mention them in the comments section and we will get back to you.
If you also want to learn Big data and make your career in it then I would suggest you must take up the following Big Data Architect Course.
 Related Posts:
Related Posts:
10 Reasons Why Big Data Analytics is the Best Career Move






































Your video and presentations clearly explain the connectivity between hadoop and data warehouses, this has been ignored by most of the industries.
Thank you for checking out our blog. We’re glad you liked it. Do subscribe to stay posted on upcoming blogs. Cheers!
is java that necessary in learning hadoop and can i learn now simultaneously.please advise
Hey Aditya, thanks for checking out our blog. Knowledge of Java and SQL is beneficial for learning Hadoop, but not mandatory. In fact, we provide a complementary self-paced course on Java essentials for Hadoop when you enroll for our Hadoop course. That should help you. Cheers!
i am an etl-datawarehousing professional working in DATASTAGE , i am very much interested in learning hadoop , can i go ahead and i want to know the part of java in this as i am familiar with only basic java.