





In today’s IT world, a voluminous amount of data sizing approx 2.5 Quintillion bytes is generated every day. This data majorly comes from different sources, for example, social media sites, video sharing sites, and medium to large-scale organizations. This data is referred as data ocean or in more general terms called the Big Data. A considerable part of this data is insignificant, unstructured and scattered when it’s alone. To make sense out of it you need analytic tools. There are many analytics tools available in the market using which you can explore, record, access, analyze and process the unstructured data. Among all those tools, Elasticsearch stands out the most. Through this blog on what is Elasticsearch, I’ll explain all about it.
But before moving ahead in this what is Elasticsearch blog, let’s take a quick glance at the topics I will be explaining:
- What Is Elasticsearch?
- Elasticsearch Advantages
- Elasticsearch Installation
- Elasticsearch Basic Concepts
- API Conventions In Elasticsearch
The following part of this Elasticsearch tutorial blog will introduce you to the Elasticsearch in detail.
What Is Elasticsearch?
Elasticsearch is a search engine based on Lucene. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents.
– Wikipedia
In other words, Elasticsearch is an open source, standalone database server developed in Java. Basically, it is used for full-text-search and analysis. It takes in unstructured data from various sources and stores it in a sophisticated format that is highly optimized for language based searches. As mentioned above, Elasticsearch uses Apache Lucene at its core for indexing and searching. Since, Lucene is just a library, working with it is a really complex. But you don’t have to worry about it as Elasticsearch hides all the complexities by providing access to the API. The API comes in the form of an HTTP RESTful API that uses JSON as the data exchange format. Using Elasticsearch you can store, search, and analyze big volumes of data in a quick and efficient manner. It is especially useful while dealing with semi-structured data i.e natural language.
Now that you know what is Elasticsearch, let’s dig a little into its history.
Elasticsearch is a product of the company named Elastic, which was founded back in 2012. ElasticSearch is one of the major open source products along with Logstash, Kibana, and Beats. Elastic provides several other commercial products like Marvel, Shield, Watcher, Found, etc.
Shay Banon in 2004, created the forerunner to Elasticsearch, called Compass. Rest of its evolution is depicted in the following timeline:
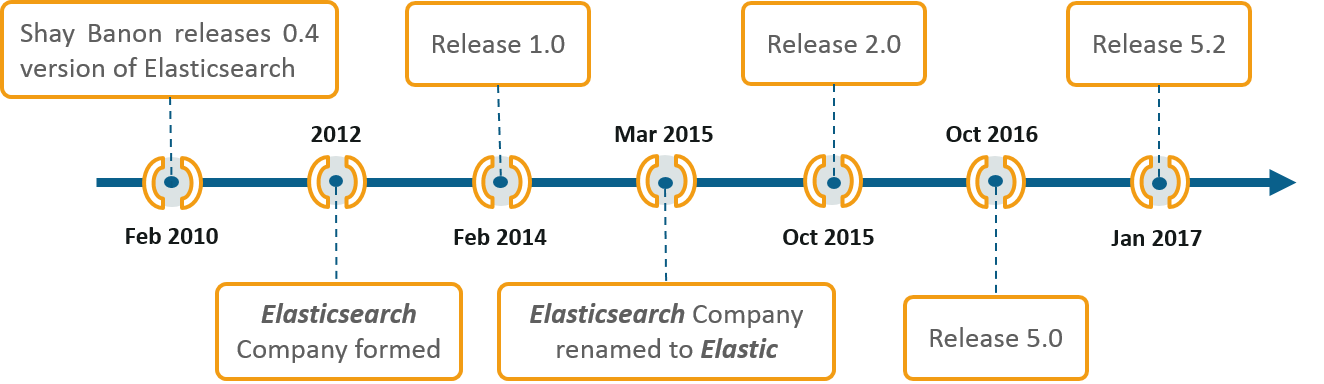
In the following section of this blog on what is Elasticsearch, you’ll find out what features of Elasticsearch made it stand out from the lot.
Advantages Of Elasticsearch
Following are few of its advantages:
- Scalability: Elasticsearch is very easy to scale and reliable as well. It is a very important feature which helps to simplify the complex architectures and save time during the implementation of projects.
- Speed: Elasticsearch uses distributed inverted indices to find the best matches for your full-text searches. This makes it really fast even when searching from very large data sets.
- Easy to use API: Elasticsearch provides simple RESTful APIs and uses schema-free JSON documents which makes indexing, searching, and querying the data really easy.
- Multilingual: One of the most distinct features Elasticsearch has is, it is multilingual. It supports a wide variety of documents written in different languages like Arabic, Brazilian, Chinese, English, French, Hindi, Korean etc.
- Document-Oriented: Elasticsearch stores real-world complex entities as structured JSON documents and indexes all fields by default to make the data searchable. Since there are no rows and columns of data, you can perform complex full-text search easily.
- Auto-completion: Elasticsearch also provides autocompletion functionality. By predicting the word using very few characters, autocompletion speeds up human-computer interaction.
- Schema-Free: Elasticsearch is schema-free as it accepts JSON documents. It tries to detect the data structure, index the data and thus makes the data searchable.
Let’s now proceed and see how to install Elasticsearch on windows in the following section of what is Elasticsearch blog.
Installation
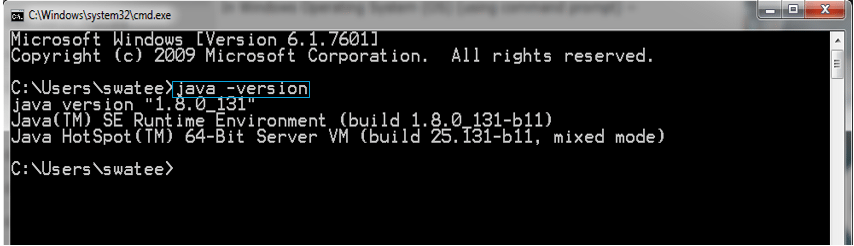
STEP I – Install the latest Java version or if you already have Java Installed then check for its version using java –version command in cmd.
NOTE: Java version must be 7 or more
STEP II – Go to https://www.elastic.co/downloads.
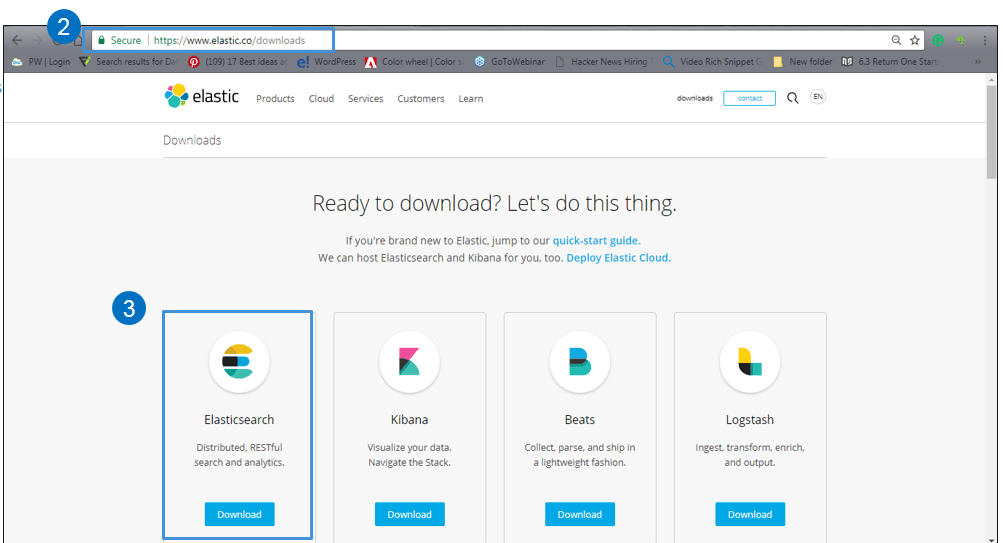 STEP III – Click on Download to get the zip file.
STEP III – Click on Download to get the zip file.
STEP IV – Once the file is downloaded, unzip it and extract the contents.
STEP V – Go to elasticsearch-x.y.z > bin.
 STEP VI – Inside bin folder, find elasticsearch.bat file and double-click on it to start the Elasticsearch server.
STEP VI – Inside bin folder, find elasticsearch.bat file and double-click on it to start the Elasticsearch server.
 STEP VII – Wait for the server to start.
STEP VII – Wait for the server to start.
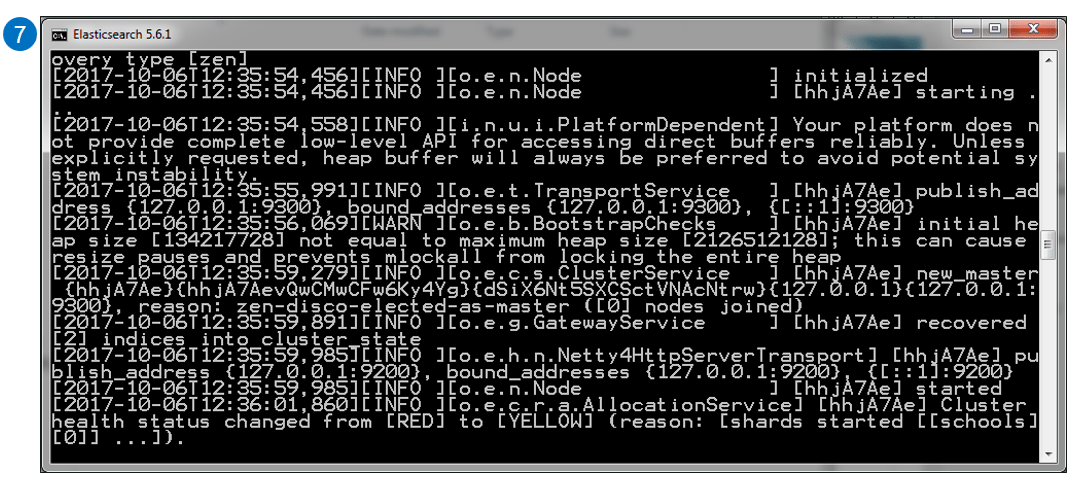 STEP VIII – Open browser and type localhost:9200 to check whether the server is running or not.
STEP VIII – Open browser and type localhost:9200 to check whether the server is running or not.
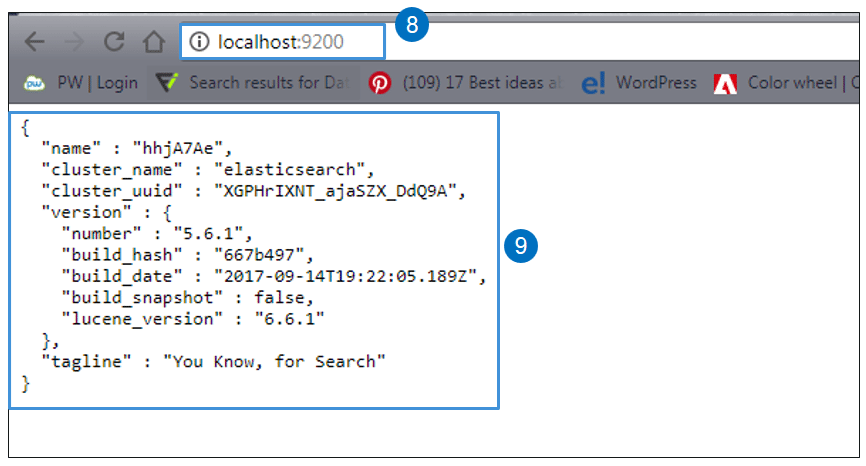 STEP IX – If you can see the above-shown message on the browser, it means everything is fine.
STEP IX – If you can see the above-shown message on the browser, it means everything is fine.
STEP X – Last thing you need to do is, to add the Sense(beta) plugin which will act as a developers interface to Elasticsearch.
Elasticsearch Basic Concepts
Before diving deeper into Elasticsearch there are few concepts that you must get familiar with.
Near Real-Time
 Elasticsearch is a near real-time search platform which means it can regularly schedule a fresh state of searchable documents. By default, it is one state per second. Thus, there is a slight latency until the time a document becomes searchable, from the time you index it.
Elasticsearch is a near real-time search platform which means it can regularly schedule a fresh state of searchable documents. By default, it is one state per second. Thus, there is a slight latency until the time a document becomes searchable, from the time you index it.Index

A n index is a collection of documents having similar characteristics. It stores the data in one or more indices using SQL analogies. It is used to store and read the documents from it. In Elasticsearch, an index is identified by a unique name and must be in all lowercase. This name is then used to refer to a particular index while performing various activities on the documents present in it. In a single cluster, there can be n number of indexes.
n index is a collection of documents having similar characteristics. It stores the data in one or more indices using SQL analogies. It is used to store and read the documents from it. In Elasticsearch, an index is identified by a unique name and must be in all lowercase. This name is then used to refer to a particular index while performing various activities on the documents present in it. In a single cluster, there can be n number of indexes.
Document

In Elasticsearch, a document is a basic unit of information which we can index. These documents consist of different fields and each of these fields is identified by its name and can contain one or more values. These documents are schema free and may have a different set of fields. This document is a JSON (JavaScript Object Notation). Within an index n number of documents can be stored.

Type
In Elasticsearch, a type is defined for documents which have a common set of fields. It is a logical category/ partition of an index whose semantics is completely up to the user. You can also define more than one type within an index.
Node
 A node is a single instance of the Elasticsearch server which stores the data. It participates in the cluster’s indexing and searching capabilities. A node is identified by a name. By default, a random Universally Unique IDentifier (UUID) is assigned to the node at the startup. This name is used for the administration purposes. You can identify which servers in your network correspond to which nodes in your Elasticsearch cluster using these names.
A node is a single instance of the Elasticsearch server which stores the data. It participates in the cluster’s indexing and searching capabilities. A node is identified by a name. By default, a random Universally Unique IDentifier (UUID) is assigned to the node at the startup. This name is used for the administration purposes. You can identify which servers in your network correspond to which nodes in your Elasticsearch cluster using these names.
Cluster
A cluster is a collection of one or more Elasticsearch nodes (servers) that works together. It holds the entire data and provides easy indexing and search capabilities across all the nodes. This distributed nature grant the easy handling of data that is too large for a single node to handle on its own. Like a node, a cluster is also identified by a unique name. By default, the name is “elasticsearch”. A node can only be part of a cluster if the node is set up to join the cluster by its name and that’s why the name of the cluster is very important.
Shards
 Using a cluster, you can store large volumes of information that can exceed abilities of a single server. To solve this problem, Elasticsearch allows you to subdivide your index into multiple pieces which are called shards. The number of shards needed can be defined while creating an index. Each shard is a fully-functional and independent “index” which can be hosted on any node within the cluster.
Using a cluster, you can store large volumes of information that can exceed abilities of a single server. To solve this problem, Elasticsearch allows you to subdivide your index into multiple pieces which are called shards. The number of shards needed can be defined while creating an index. Each shard is a fully-functional and independent “index” which can be hosted on any node within the cluster.
Replicas
To avoid any kind of accidental failures, such as a shard or node going offline for some reason, its always recommended having a failover mechanism. Thus as a solution, Elasticsearch provides replicas. Replicas are just an additional copy of a shard and can be used for queries just as the original shards.
reason, its always recommended having a failover mechanism. Thus as a solution, Elasticsearch provides replicas. Replicas are just an additional copy of a shard and can be used for queries just as the original shards.
API Conventions
The Elasticsearch REST APIs are accessed using JSON over HTTP. Elasticsearch uses following conventions throughout the REST API:-
- Multiple Indices: Generally, the operations in API’s are for multiple indices. This helps the user in performing various operations through the entire API by executing the related query once. Some of the notations used for these queries are:
- Comma-separated notations (demo1,demo2,demo3)
- Wildcard notations(demo*,de*o2,+demo3,-demo3)
- _all keyword for all indices
- URL Query String Parameters (ignore_unavailable, allow_no_indices, expand_wildcards)
- Date Math Support in Index Name: You can search a range of time-series indices by using the date math index name resolution. This type of search limits the number of indices that are being searched, thus reducing the load on the cluster and improving the execution performance. You need to specify date and time in a specific format like: <static_name{date_math_expr{date_format|time_zone}}>
- static_name: Represents the static text part of the name.
- date_math_expr: Represents a dynamic date math expression which computes the date dynamically.
- date_format: Represents the optional format in which the computed date should be rendered.
- time_zone: Represents the optional time zone.
- Common Options: Few of the common options are:
- Pretty Result
- Human Readable Output
- Date Math
- Response Filtering
- Flat Settings
- Parameter
- No Values
- Time Units
- Byte Size Units
- Unit-less quantities
- Distance Units
- Fuzziness
- Enabling Stack Traces
- Request Body In Query String
- URL based Access Control: Users can also use a proxy with URL-based access control to secure access to the Elasticsearch indices. Elasticsearch provides an option of specifying an index in the URL and on each individual request within the request body for some requests like:
- multi-search
- multi-get
- bulk
This brings us to the end of the blog on what is Elasticsearch. I hope through this blog on what is Elasticsearch I was able to clearly explain what is Elasticsearch and its basic components. For more advanced concepts and practical demonstrations, you can refer my next blog on Elasticsearch Tutorial.
If you want to get trained in Elasticsearch and wish to search and analyze large datasets with ease, then check out the ELK Stack Training by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe.
Got a question for us? Please mention it in the comments section and we will get back to you.







































