








Amazon S3 Cross Region Replication (CRR) is a powerful feature that automatically replicates objects from one AWS Region to another, ensuring higher data availability, improved durability, and compliance with data residency or disaster recovery requirements. It helps organizations maintain identical backups across geographically distant locations with minimal setup and effort.
In this blog, we’ll explore how CRR works, its features, setup steps, and common use cases.
What is S3 Cross Region Replication?
It is an S3 feature that automatically and asynchronously copies objects from a source bucket in one AWS Region to one or more destination buckets in different Regions. When enabled, every new object written to the source bucket is replicated to the target bucket(s) in the other Region. It’s not only copies the object data but also retains all object metadata and tags, ensuring the replica is identical to the source. This cross region copy improves data durability and availability.
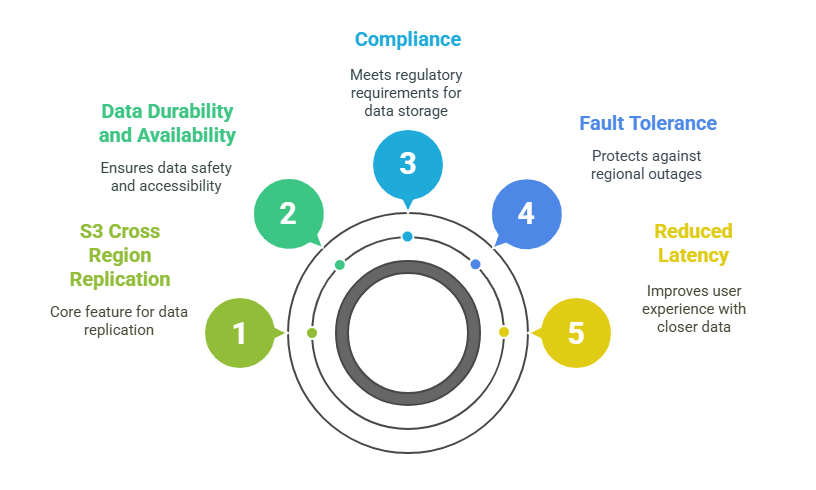

For example, you can use it to meet compliance requirements by storing data in geographically distant Regions, to increase fault tolerance so that an outage in one Region won’t affect critical data, and to minimize read latency by keeping a copy closer to users in another location.
In practice, it is configured on the source S3 bucket via replication rules; once set up, S3 manages all ongoing replication in the background.
How Does it Work?
Cross Region Replication is configured on the source bucket and occurs at the bucket level. When you enable CRR, you create one or more replication rules on the source bucket that specify which objects to replicate and where to send them. Each rule includes the following elements:
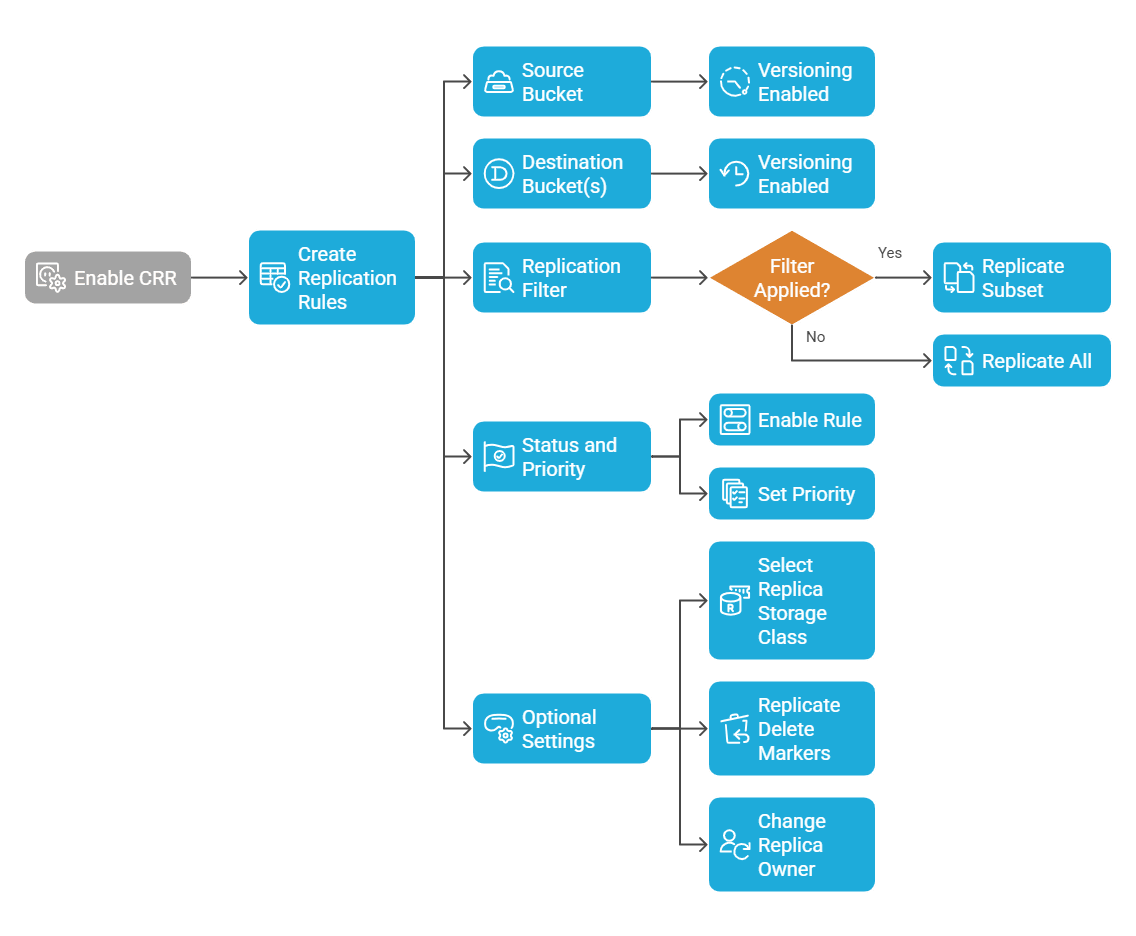

- Source bucket: The bucket where replication is configured. This bucket must have versioning enabled.
- Destination bucket(s): The target S3 bucket(s) in one or more AWS Regions where you want to replicate objects. The destination can be in the same AWS account or a different account, and it must also have versioning enabled.
- Replication filter: Rules can replicate all objects or a subset. You can restrict by prefix or by object tags. If no filter is set, the rule applies to the entire bucket.
- Status and priority: You give each rule a name and enable it. If multiple rules apply to the same object or destination, rules have priorities to determine which one takes effect.
- Optional settings: Additional options include selecting the replica storage class and determining whether to replicate delete markers or change the replica owner in cross-account scenarios.
Once a replication rule is active, Automatic Replication occurs for all new objects that meet the rule criteria. Amazon S3 immediately enqueues the object for replication when it is created or updated in the source bucket. Because CRR is asynchronous, there is a short delay before the object appears in the destination, but S3 handles all transfer and retry logic in the background.
Note that objects existing in the bucket before replication was configured are not copied by CRR; you must use S3 Batch Replication to replicate pre-existing data if needed. In normal operation, most objects replicate within minutes of upload, although the exact replication time can vary depending on object size and network conditions.
AWS S3 Tutorial For Beginners

S3 Bucket Level
Replication is managed at the bucket level on the source side. You add a replication configuration to the source bucket’s management settings. In practice, this means:
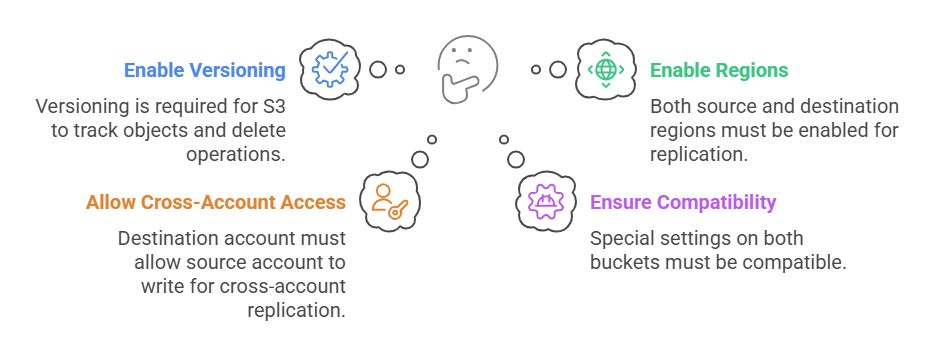

- You must enable versioning on both the source and destination buckets before setting up CRR. Versioning is required because S3 identifies objects by version IDs, and delete operations are tracked via delete markers. Without versioning, replication cannot occur.
- The AWS account that owns the source bucket must have the AWS Regions enabled where the source and destination buckets reside. Similarly, the destination bucket owner must enable their Region.
- In a cross-account scenario, the destination bucket’s account must allow the source bucket’s account to write.
- If either bucket has special settings, both sides must be configured compatibly.
In short, CRR is turned on by modifying the source bucket’s replication configuration. This is done through the S3 console, CLI, SDK, or REST API. Once in place, the configuration directs S3 to replicate as objects arrive in the source bucket.
Automatic Replication
After the replication rule is in place, Amazon S3 performs replication automatically. Each time a new object is put into the source bucket (or an existing object version is overwritten), S3 logs the event and begins copying that object to the destination bucket(s) according to the rule. The process is fully managed and asynchronous – you don’t have to run any jobs yourself. Amazon S3 handles retries, permissions, and transport. The replicated object appears in the target bucket with the same key and metadata. This happens continuously as data is written, ensuring that all new content is mirrored to the secondary Region without manual intervention.
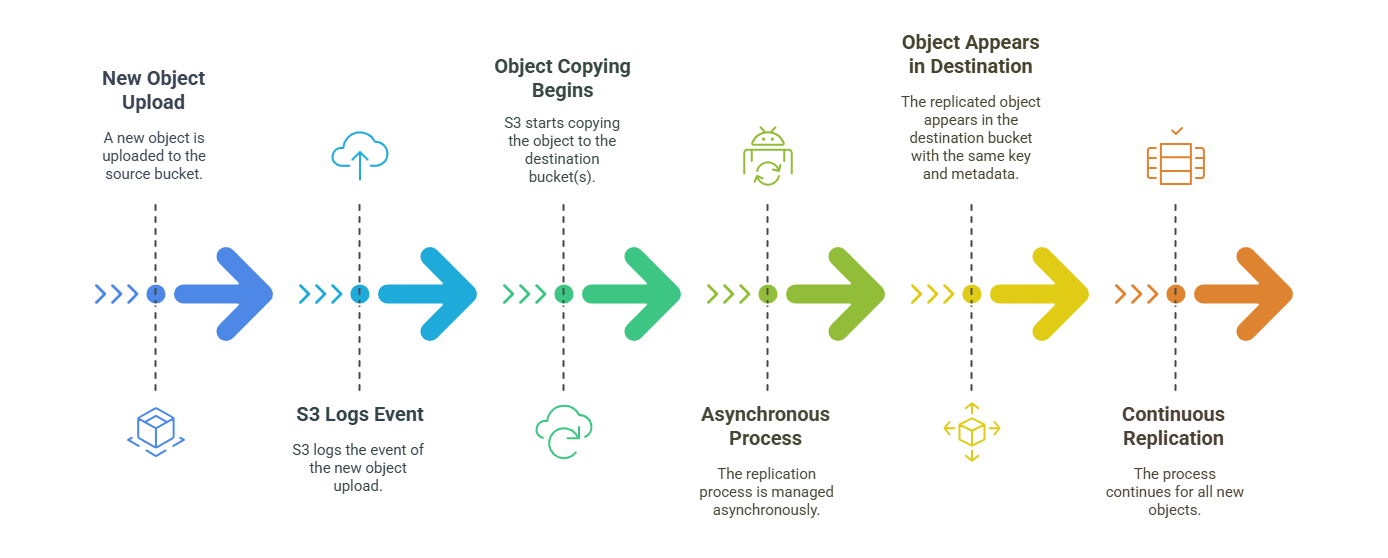

It is essential to note that CRR does not backfill existing objects that were already present in the bucket. Only objects written after the rule was created are automatically replicated. Additionally, because it is asynchronous, there may be a short delay before the replica appears in the destination. Replication time depends on object size, network, and whether Replication Time Control (RTC) is enabled.
Configurable Rules
Replication rules are highly flexible. Each rule on the source bucket lets you fine-tune what gets replicated and how:
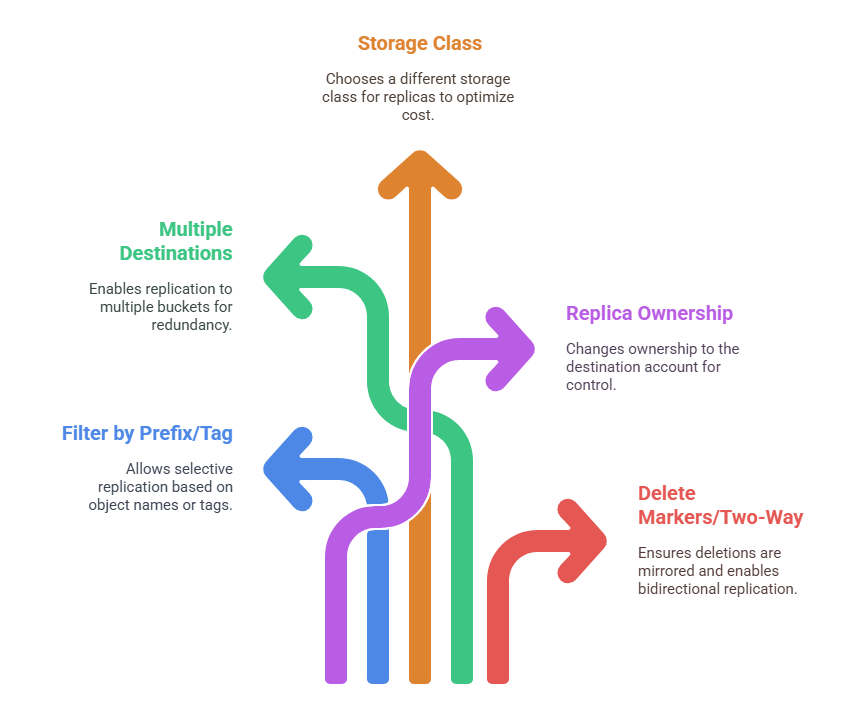

- Filter by prefix or tag: You can replicate all objects, or restrict the rule to objects whose key names start with a certain prefix, or to objects that carry specific tags. You can even combine prefixes and tags, in which case only objects matching both criteria are replicated. This allows for partial replication within a single bucket.
- Multiple destination buckets: A single source bucket can replicate to one or more destination buckets, even in different accounts. For example, a bucket could replicate critical data to two other Regions for extra redundancy.
- Storage class: By default, S3 uses the same storage class for the replica as the source object. However, you can choose a different storage class for the replica. For instance, you might replicate to a cheaper storage class, such as Glacier Instant Retrieval, in the target bucket if those copies are intended mostly for backup.
- Replica ownership: In cross-account replication, by default, the replicated object remains owned by the source account and its ACLs or S3 Object Ownership settings are preserved. Optionally, you can configure CRR to change the owner of the replica to the account of the destination bucket. This can prevent accidental deletion by the original owner and ensure the target account has full control over its replicas.
- Delete markers and two-way replication: By default, a deletion on the source bucket is represented by a delete marker and will also replicate that delete marker if you enable it. If you want a fully synchronous, two-way, or bidirectional replication setup, you would create replication rules in both directions and typically enable replication of delete markers, so that deletions are mirrored.
These configurable rules make CRR suitable for many use cases. For example, you could replicate only sensitive data (tagged accordingly) to another region for compliance, or replicate all objects under a logs/ prefix to consolidate logs in a central bucket for analysis. The rule-based design gives you control while Amazon S3 handles the underlying data movement.
IAM Role
Cross Region replication requires an AWS Identity and Access Management (IAM) role that allows Amazon S3 to perform the replication on your behalf. When configuring a replication rule, you must specify an IAM role that has permissions to read objects from the source bucket and write to the destination bucket. Essentially, S3 will assume this role when copying each object. The role typically needs at least the following permissions:
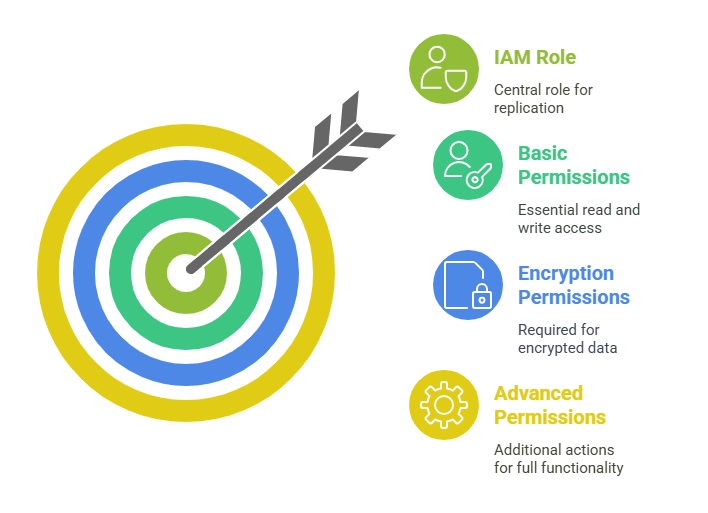

- s3:GetObject and s3:GetObjectVersion on the source bucket.
- s3:PutObject on the destination bucket.
- If you use AWS KMS encryption, the role also needs permission to decrypt with the source bucket’s KMS key and encrypt with the destination key.
- Additionally, the role usually requires s3:GetObjectVersionAcl and s3:ReplicateObject actions for full replication functionality.
You can use an existing role or create a new one in the console when setting up the rule. The AWS S3 console can even auto-generate a suitable role for you. If you’re replicating across accounts, you must also ensure that the destination bucket’s account trusts this role. The AWS documentation provides detailed instructions for setting up these permissions, but the console streamlines much of the process. In practice, once the role is in place, S3 uses it transparently to copy each object, so you only need to ensure the correct trust relationship exists.
Also Read AWS CloudFront vs S3 Cross-Region Replication
What are the Features of Amazon S3 Cross Region Replication?
Amazon S3’s Cross Region Replication offers a rich set of features for durability, performance, and compliance. Key features include:
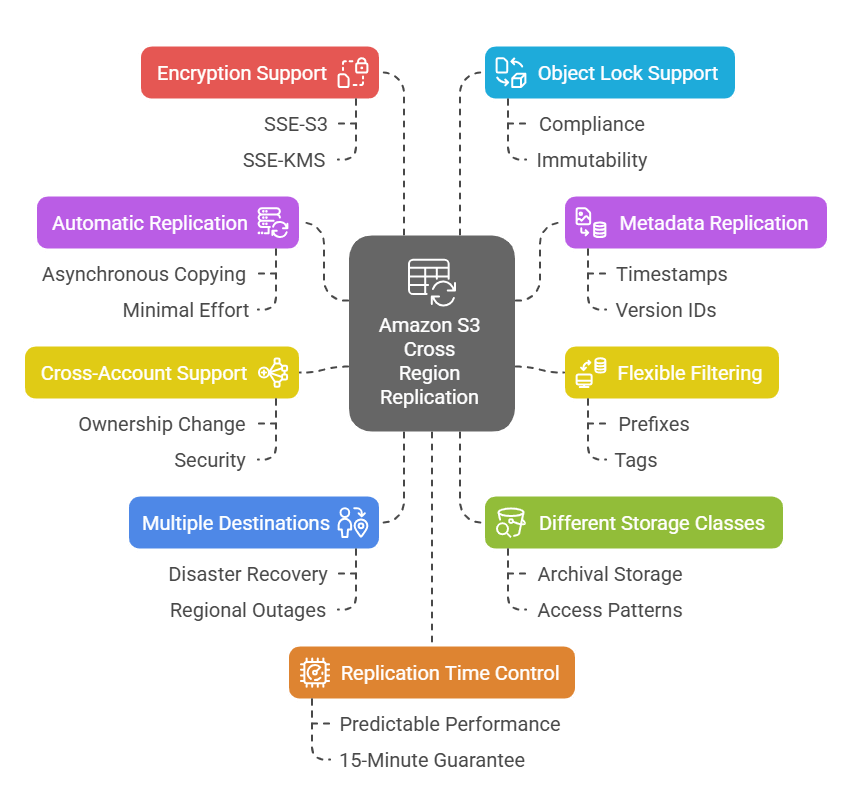

- Automatic, fully managed replication: Once configured, S3 handles all replication with minimal effort. New objects are copied asynchronously across the AWS network into the target bucket(s).
- Replication of metadata and tags: Replicas preserve all object metadata, including timestamps, version IDs, ACLs, and tags, ensuring that the copies are identical to the source in every way. This ensures consistency and traceability of data.
- Flexible filtering: You can replicate the whole bucket or set up rules to replicate only objects with certain prefixes or tags. This lets you target only the data that matters for each replication policy.
- Cross-account support: CRR works across AWS accounts. You can replicate to buckets owned by other accounts, and even change replica ownership to the destination account for additional security.
- Multiple destinations: A source bucket can replicate to various destinations, even in different Regions or accounts. This enables scenarios like sending copies to two disaster-recovery Regions simultaneously.
- Different storage classes: You can specify a different storage class for replicas to optimize costs or access patterns. For example, replicate some objects into an archival storage class in the destination.
- Encryption support: CRR works with encrypted objects. For SSE-S3 or SSE-KMS encryption, you can replicate encrypted objects as long as the IAM role has permission to use the KMS keys in both regions.
- Object Lock support: If Object Lock is enabled, CRR can replicate compliance (immutable) objects. Both source and destination must have Object Lock enabled for this.
- Replication Time Control (RTC): For workloads that need predictable performance, you can enable S3 Replication Time Control. With RTC, Amazon S3 guarantees that 99.99% of objects replicate to the destination within 15 minutes.
- Monitoring and notifications: S3 provides detailed metrics (via CloudWatch) on replication status, such as bytes pending or operations failed. You can also configure event notifications for replication failures or complete events, enabling proactive alerts and automation.
- Cost and durability: By replicating your data to another region, it becomes more durable, surviving even a full Regional outage. It also helps meet data residency or backup policy requirements by keeping data geographically separate.
Overall, these features make CRR a powerful tool for data resilience, compliance, and performance. You get an almost hands-off way to maintain up-to-date copies of critical data in additional Regions, with fine-grained control over what is copied and how. S3 handles the heavy lifting, while you benefit from reduced latency for global users and robust protection against Region-wide failures.
How to Enable Cross Region Replication in S3?
Enabling CRR involves a few key steps, mainly in the S3 console or via AWS APIs. Below is a concise walkthrough:
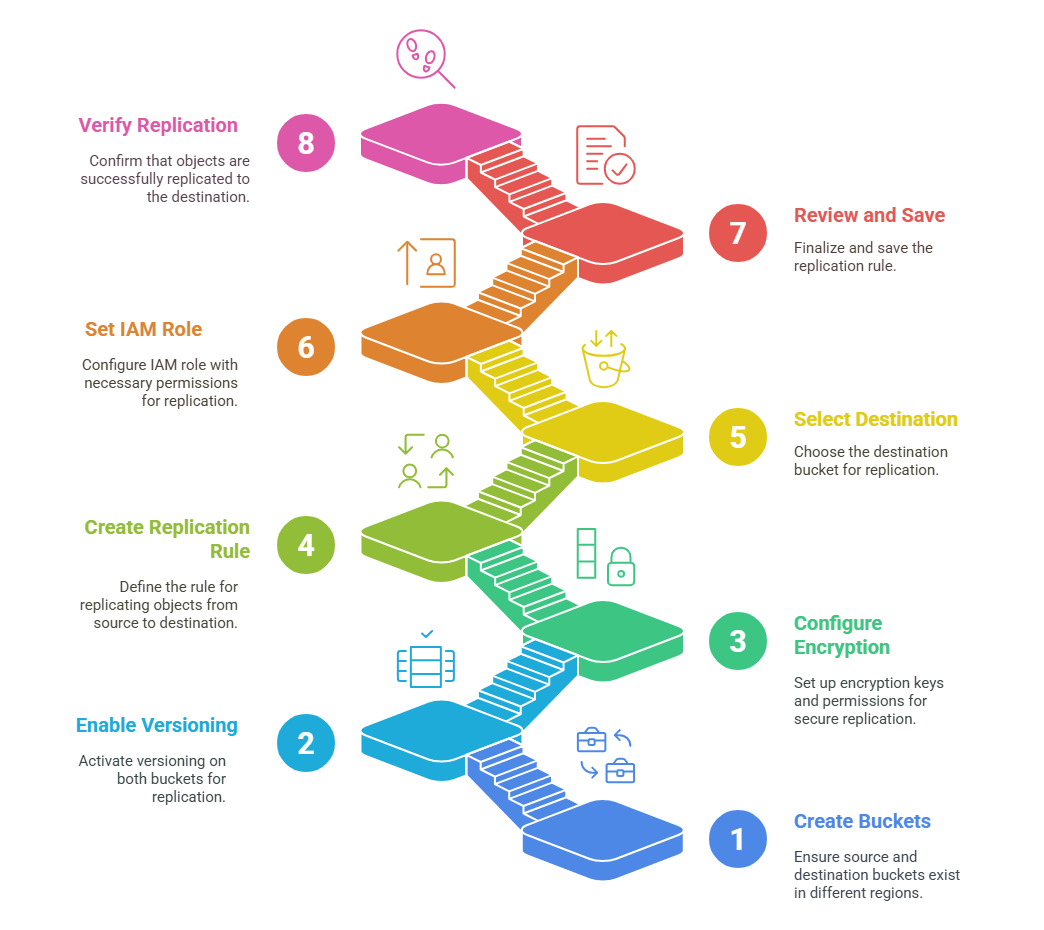

- Create or verify buckets: Make sure you have two buckets – one in the source Region and one in the destination Region. If needed, create them now via the S3 console or CLI.
- Enable versioning on both buckets: Go to the Properties tab of each bucket and enable versioning. Versioning is mandatory for replication to work.
- (Optional) Configure encryption and permissions: If your data is KMS-encrypted, ensure the destination bucket’s key allows decrypt/encrypt. Also, check your AWS account’s region activation settings. If the buckets are in different accounts, ensure the destination bucket’s policy trusts the source account for replication.
- Create a replication rule on the source bucket: In the source bucket, go to the Management tab and click Replication rules → Create replication rule.
- Give the rule a name and set its Status to Enabled.
- Specify the source scope.
- Select the destination bucket: In the rule configuration, choose your destination bucket. The console will typically let you browse or enter the destination. Confirm the Region is different. The interface reminds you that both buckets must have versioning enabled.
- Set up or select the IAM role: The console prompts to create a new IAM role for replication or use an existing one. If you create a new role here, AWS will pre-fill a role with the necessary trust and policies. If using an existing role, ensure it has at least s3:GetObject* on the source and s3:PutObject* on the destination.
- Optional settings: You can choose other options such as:
- Replica storage class.
- Change ownership.
- Replicate delete markers.
- S3 Replication Time Control.
- Review and save: Review the rule. When you save it, Amazon S3 creates the replication configuration. From now on, any new objects matching the rule will start replicating to the destination.
- Verify replication: Upload a test object to the source bucket and check that it appears in the destination. Remember that it may take a few moments. You can monitor replication status and metrics in the S3 console under the Replication section.
By following these steps, you activate cross region replication. The buckets will now stay in sync according to your rule. If you ever need to adjust the rule, you can edit the replication configuration on the source bucket’s Management tab.
Conclusion
Amazon S3 Cross Region Replication (CRR) automatically copies objects between AWS Regions to enhance data durability, compliance, disaster recovery, and performance by reducing latency for global users. Once configured with prerequisites like versioning and IAM roles, CRR requires minimal maintenance. It offers fully managed replication with features like metadata retention, cross-account support, and optional Replication Time Control, making it ideal for resilient, multi-region application architectures.
If you want to dive deeper into AWS and build your expertise, you can explore the AWS Solution Architect Associate Training to gain a comprehensive understanding of AWS services, infrastructure, and deployment strategies. For more detailed insights, check out our What is AWS and AWS Tutorial. If you are preparing for an interview, explore our AWS Interview Questions.
FAQs
1. How long does cross region replication take for S3?
Usually within minutes, depending on object size and network conditions.
2. What is the difference between CloudFront and S3 cross region replication?
CloudFront caches content for faster delivery; CRR copies data between regions for durability and compliance.
3. Which S3 bucket property must be enabled to allow cross region replication?
Versioning must be enabled on both source and destination buckets.
4. What is cross region in AWS?
It refers to operations or data spanning multiple AWS geographic regions.
5. Why use CloudFront in front of S3?
To deliver content faster to users by caching it at edge locations worldwide.