
Data Science with Python Certification Course
- 132k Enrolled Learners
- Weekend
- Live Class
(49300)





 Copy Link!
Copy Link!
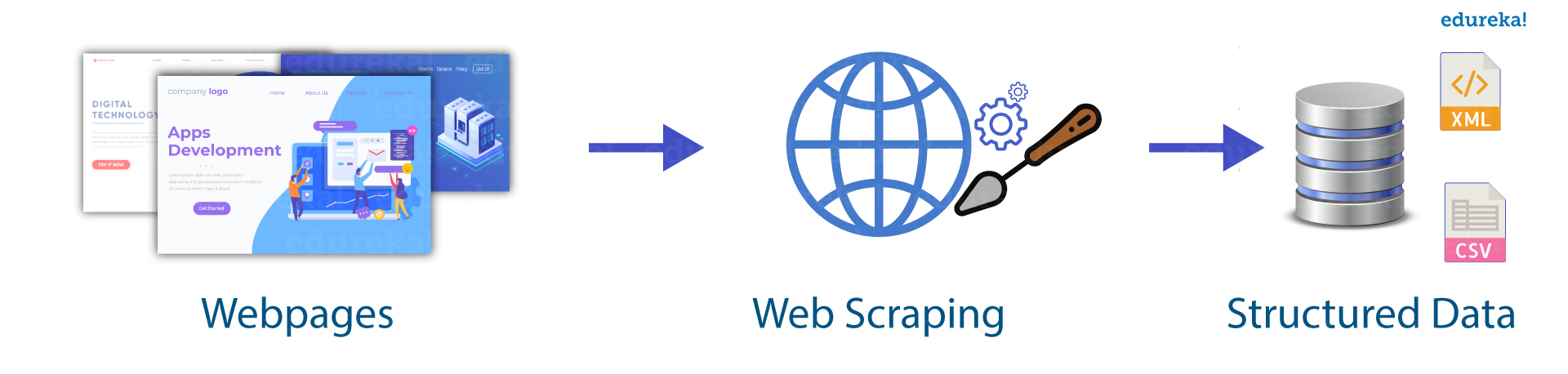
Let’s say you need to scrape a lot of information from the web, and time is of the essence. What alternative would there be to manually accessing each website and retrieving the information? “Web Scraping” is the technique that can be used. Web scraping merely facilitates and accelerates the process.
This “Python Full Course” video provides a comprehensive overview of Python programming.
In this article on Web Scraping with Python, you will learn about web scraping in brief and see how to extract data from a website with a demonstration.
Web scraping is used to collect large information from websites. You can also find more in-depth concepts about Web Scraping on Edureka’s Python course. But why does someone have to collect such large data from websites? To know about this, let’s look at the applications of web scraping:
Web scraping is one of the automated processes for gathering extensive information from the World Wide Web. The information found on the websites is disorganized. In order to store this data in a more organized fashion, web scraping is a useful tool. Online services, application programming interfaces (APIs), and custom code are just some of the options for scraping websites. This article will show how to use Python to perform web scraping.
Talking about whether web scraping is legal or not, some websites allow web scraping and some don’t. To know whether a website allows web scraping or not, you can look at the website’s “robots.txt” file. You can find this file by appending “/robots.txt” to the URL that you want to scrape. For this example, I am scraping Flipkart website. So, to see the “robots.txt” file, the URL is www.flipkart.com/robots.txt.
Here is the list of features of Python which makes it more suitable for web scraping.
In this video, we explore the Top 10 Technologies to Learn in 2025 that will shape the future of industries and careers.
When you run the code for web scraping, a request is sent to the URL that you have mentioned. As a response to the request, the server sends the data and allows you to read the HTML or XML page. The code then, parses the HTML or XML page, finds the data and extracts it.
To extract data using web scraping with python, you need to follow these basic steps:
Now let us see how to extract data from the Flipkart website using Python.
Check out this AI and ML course in collaboration with Illinois Tech to learn Python usage in Generative AI and ML and build a successful career.
As we know, Python is has various applications and there are different libraries for different purposes. In our further demonstration, we will be using the following libraries:
To use python in scraping data from a webpage, Follow these steps:
Step one: Selecting the webpage and its URL.
Determine which website you are going to take your content from. In our case, we are going to pull the highest rated film list from IMDb at https://www.imdb.com/.
Step two: Inspecting the website
View the structure of the webpage. This can be done by inspection using the “Inspect” option when right-clicking on the page. Note the class names and IDs of elements which look interesting.
Third Step: Install Required Libraries
The following commands install the libraries needed to perform web-scraping:
“`bash
pip install requests beautifulsoup4 pandas
“`
Fourth step: Write the Python Code**
Now write the following Python code to extract the data:
import requests from bs4 import BeautifulSoup import pandas as pd Not a scrap, but enabling for scraping websites in Python as of October 2022: import time
# Website URL to scrape
url = "https://www.imdb.com/chart/top"
# Send GET request to the website
response = requests.get(url)
# Parse the HTML code using BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# Extract relevant data from the scraped HTML code
movies = []
for row in soup.select('tbody.lister-list tr'):
title = row.find('td', class_='titleColumn').find('a').get_text()
year = row.find('td', class_='titleColumn').find('span', class_='secondaryInfo').get_text()[1:-1]
rating = row.find('td', class_='ratingColumn imdbRating').find('strong').get_text()
movies.append([title, year, rating])
# Store the info in a pandas dataframe
df = pd.DataFrame(movies, columns=['Title', 'Year', 'Rating'])
# Add delay between requests to not flood the website
time.sleep(1)
# Export the data into a CSV file
df.to_csv('top-rated-movies.csv', index=False)
Fifth Step : Export the Extracted Data**
Export this scraped data as a CSV file using pandas.
Sixth step : Check the Extracted Data**
Now, open the CSV file to check that the data has been scraped and stored correctly.
This code can be easily adjusted to suit any website and data that a user wants to extract.
Pre-requisites:
Let’s get started!
For this example, we are going scrape Flipkart website to extract the Price, Name, and Rating of Laptops. The URL for this page is https://www.flipkart.com/laptops/~buyback-guarantee-on-laptops-/pr?sid=6bo%2Cb5g&uniqBStoreParam1=val1&wid=11.productCard.PMU_V2.
Step 2: Inspecting the Page
The data is usually nested in tags. So, we inspect the page to see, under which tag the data we want to scrape is nested. To inspect the page, just right click on the element and click on “Inspect”.
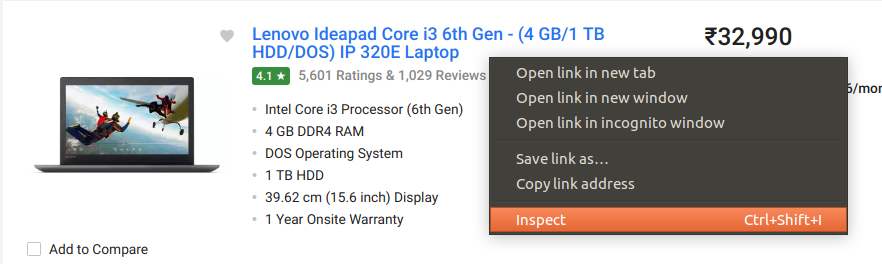
When you click on the “Inspect” tab, you will see a “Browser Inspector Box” open.
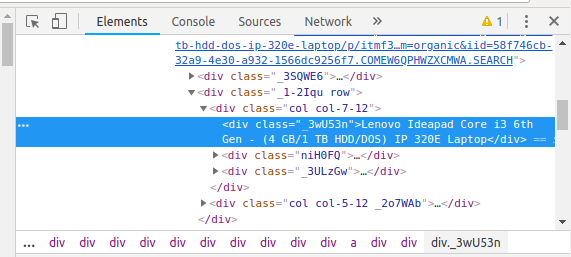
Let’s extract the Price, Name, and Rating which is in the “div” tag respectively.
First, let’s create a Python file. To do this, open the terminal in Ubuntu and type gedit <your file name> with .py extension.
I am going to name my file “web-s”. Here’s the command:
gedit web-s.py
Now, let’s write our code in this file.
First, let us import all the necessary libraries:
from selenium import webdriver from BeautifulSoup import BeautifulSoup import pandas as pd
To configure webdriver to use Chrome browser, we have to set the path to chromedriver
driver = webdriver.Chrome("/usr/lib/chromium-browser/chromedriver")
Refer the below code to open the URL:
products=[] #List to store name of the product
prices=[] #List to store price of the product
ratings=[] #List to store rating of the product
driver.get("https://www.flipkart.com/laptops/~buyback-guarantee-on-laptops-/pr?sid=6bo%2Cb5guniq")
Now that we have written the code to open the URL, it’s time to extract the data from the website. As mentioned earlier, the data we want to extract is nested in <div> tags. So, I will find the div tags with those respective class-names, extract the data and store the data in a variable. Refer the code below:
content = driver.page_source
soup = BeautifulSoup(content)
for a in soup.findAll('a',href=True, attrs={'class':'_31qSD5'}):
name=a.find('div', attrs={'class':'_3wU53n'})
price=a.find('div', attrs={'class':'_1vC4OE _2rQ-NK'})
rating=a.find('div', attrs={'class':'hGSR34 _2beYZw'})
products.append(name.text)
prices.append(price.text)
ratings.append(rating.text)
To run the code, use the below command:
python web-s.py
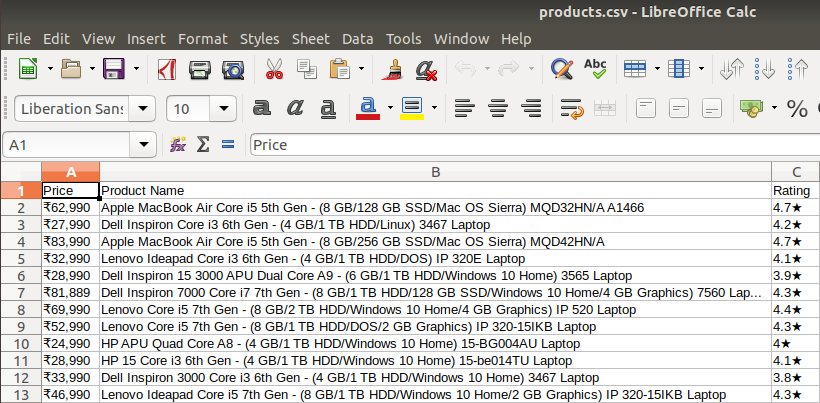
After extracting the data, you might want to store it in a format. This format varies depending on your requirement. For this example, we will store the extracted data in a CSV (Comma Separated Value) format. To do this, I will add the following lines to my code:
df = pd.DataFrame({'Product Name':products,'Price':prices,'Rating':ratings})
df.to_csv('products.csv', index=False, encoding='utf-8')
Now, I’ll run the whole code again.
A file name “products.csv” is created and this file contains the extracted data.
You can easily parse text from a website using Beautiful Soup or lxml. Here are the steps involved with the code.
The following is used to scrape text from a website using BeautifulSoup:.
import requests
from bs4 import BeautifulSoup
# Send an HTTP request to the URL of the webpage you want to access
response = requests.get("https://www.imdb.com")
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Extract the text content of the webpage
text = soup.get_text()
print(text)
Thats all you have to do to parse the text from website
You will most likely use a Python library, such as BeautifulSoup, lxml, or even mechanize, for scraping HTML forms. Here are the typical steps:
Send an HTTP request to the URL of the webpage containing the form you want to scrape. The request is responded to by the server returning the HTML content of the webpage.
After getting the HTML content, you will further leverage an HTML parser that assists in finding a form you want to scrape. You are, for example, going to be in a position to use the discover() method from BeautifulSoup to find the form tag.
Now, locate the form. Extracting the input fields along with their values will be using the HTML parser. For example, you’ll get through find_all() function from BeautifulSoup all the input labels located in the form then extract title and value attributes.
You later use that info when returning a frame or further processing information.
import requests
from bs4 import BeautifulSoup
def get_imdb_movie_info(movie_title):
base_url = "https://www.imdb.com"
search_url = f"{base_url}/find?q={movie_title}&s=tt"
response = requests.get(search_url)
soup = BeautifulSoup(response.content, 'html.parser')
result = soup.find(class_='findList').find('td', class_='result_text').find('a')
if not result:
return None
movie_path = result['href']
movie_url = f"{base_url}{movie_path}"
movie_response = requests.get(movie_url)
movie_soup = BeautifulSoup(movie_response.content, 'html.parser')
title = movie_soup.find(class_='title_wrapper').h1.text.strip()
rating = movie_soup.find(itemprop='ratingValue').text.strip()
summary = movie_soup.find(class_='summary_text').text.strip()
print(f"Title: {title}")
print(f"Rating: {rating}")
print(f"Summary: {summary}")
movie_title = input("Enter a movie title: ")
get_imdb_movie_info(movie_title)
To scrape and parse text from websites in Python, you can use the requests library to fetch the HTML content of the website and then use a parsing library like BeautifulSoup or lxml to extract the relevant text from the HTML. Here’s a step-by-step guide:
Step 1: Import necessary modules
import requests from bs4 import BeautifulSoup import re
Step 2: Fetch the HTML content of the website using `requests`
url = 'https://example.com'; # Replace this with the URL of the website you want to scrape
response = requests.get(url)
# Check if the request was successful
if response.status_code == 200:
html_content = response.content
else:
print("Failed to fetch the website.")
exit()
Step 3: Parse the HTML content using `BeautifulSoup`
# Parse the HTML content with BeautifulSoup soup = BeautifulSoup(html_content, 'html.parser')
Step 4: Extract the text from the parsed HTML using string methods
# Find all the text elements (e.g., paragraphs, headings, etc.) you want to scrape text_elements = soup.find_all(['p', 'h1', 'h2', 'h3', 'h4', 'h5', 'h6', 'span']) # Extract the text from each element and concatenate them into a single string scraped_text = ' '.join(element.get_text() for element in text_elements) print(scraped_text)
Step 5: Extract text from HTML using regular expressions
</pre> <span> </span></pre> <span style="font-weight: 400;">Note: The regular expression in Step 5 is a simple pattern that matches any HTML tag and removes them from the HTML content. In real-world scenarios, you may need more complex regular expressions depending on the structure of the HTML.</span> <strong>Check Your Understanding:</strong> <span style="font-weight: 400;">Now that you have built your web scraper, you can use either the string method approach or the regular expression approach to extract text from websites. Remember to use web scraping responsibly and adhere to website policies and legal restrictions. Always review the website's terms of service and robots.txt file before scraping any website. Additionally, excessive or unauthorized scraping may put a strain on the website's server and is generally considered unethical.</span> <h2>Use an HTML Parser for Web Scraping in Python</h2> <span style="font-weight: 400;">Here are the steps to use an HTML parser like Beautiful Soup for web scraping in Python:</span> <b>Step 1: Install Beautiful Soup</b> <span style="font-weight: 400;">Make sure you have the Beautiful Soup library installed. If not, you can install it using `pip`:</span> [python] bash pip install beautifulsoup4
Step 2: Create a BeautifulSoup Object
Import the necessary modules and create a BeautifulSoup object to parse the HTML content of the website.
from bs4 import BeautifulSoup import requests
Step 3: Use a BeautifulSoup Object
Fetch the HTML content of the website using the `requests` library, and then create a BeautifulSoup object to parse the HTML content.
[Python]
url = ‘https://example.com’
# Replace this with the URL of the website you want to scrape
response = requests.get(url)
# Check if the request was successful
if response.status_code == 200:
html_content = response.content
else:
print(“Failed to fetch the website.”)
exit()
# Create a BeautifulSoup object to parse the HTML content
soup = BeautifulSoup(html_content, ‘html.parser’)
[/python]
Step 4: Check Your Understanding
Now that you have a BeautifulSoup object (`soup`), you can use its various methods to extract specific data from the HTML. For example, you can use `soup.find()` to find the first occurrence of a specific HTML element, `soup.find_all()` to find all occurrences of an element, and `soup.select()` to use CSS selectors to extract elements.
Here’s an example of how to use `soup.find()` to extract the text of the first paragraph (`<p>`) tag:
# Find the first paragraph tag and extract its text
first_paragraph = soup.find('p').get_text()
print(first_paragraph)
You can explore more methods available in the BeautifulSoup library to extract data from the HTML content as needed for your web scraping task.
Remember to use web scraping responsibly, adhere to website policies and legal restrictions, and review the website’s terms of service and robots.txt file before scraping any website. Additionally, excessive or unauthorized scraping may put a strain on the website’s server and is generally considered unethical.
Certainly! Here are the steps to interact with HTML forms using MechanicalSoup in Python:
Step 1: Install MechanicalSoup
Ensure you have the MechanicalSoup library installed. If not, you can install it using `pip`:
pip install MechanicalSoup
Step 2: Create a Browser Object
Import the necessary modules and create a MechanicalSoup browser object to interact with the website.
import mechanicalsoup
Step 3: Submit a Form with MechanicalSoup
Create a browser object and use it to submit a form on a specific webpage.
# Create a MechanicalSoup browser object browser = mechanicalsoup.StatefulBrowser() # Navigate to the webpage with the form url = 'https://example.com/form-page' # Replace this with the URL of the webpage with the form browser.open(url) # Fill in the form fields form = browser.select_form() # Select the form on the webpage form['username'] = 'your_username'; # Replace 'username' with the name attribute of the username input field form['password'] = 'your_password'; # Replace 'password' with the name attribute of the password input field # Submit the form browser.submit_selected()
Step 4: Check Your Understanding
In this example, we used MechanicalSoup to create a browser object (`browser`) and navigate to a webpage with a form. We then selected the form using `browser.select_form()`, filled in the username and password fields using `form[‘username’]` and `form[‘password’]`, and finally submitted the form using `browser.submit_selected()`.
With these steps, you can interact with HTML forms programmatically. MechanicalSoup is a powerful tool for automating form submissions, web scraping, and interacting with websites that have forms.
Remember to use web scraping and form submission responsibly, adhere to website policies and legal restrictions, and review the website’s terms of service before interacting with its forms. Additionally, make sure that the website allows automated interactions and that you are not violating any usage policies. Unauthorized and excessive form submissions can cause strain on the website’s server and may be considered unethical.
You will be able to apply libraries in Python like ‘request’ to get the web pages, and then use modules likes Beautiful Soup or lxml for parsing HTML content. Here is the step-by-step procedure to scrape this online website in real-time:
Step 1:
Install Required Libraries
Make sure you have got the fundamental libraries installed an imported. You’ll introduce them utilizing pip in the event that you haven’t as of now:
Step 2:
Type in the Scraping Code
This is a fundamental case of how to scrape an online site in genuine time utilizing Python:
Step 3:
import requests
from bs4 import BeautifulSoup
def get_imdb_movie_info(movie_title):
base_url = "https://www.imdb.com"
search_url = f"{base_url}/find?q={movie_title}&s=tt"
response = requests.get(search_url)
soup = BeautifulSoup(response.content, 'html.parser')
result = soup.find(class_='findList').find('td', class_='result_text').find('a')
if not result:
return None
movie_path = result['href']
movie_url = f"{base_url}{movie_path}"
movie_response = requests.get(movie_url)
movie_soup = BeautifulSoup(movie_response.content, 'html.parser')
title = movie_soup.find(class_='title_wrapper').h1.text.strip()
rating = movie_soup.find(itemprop='ratingValue').text.strip()
summary = movie_soup.find(class_='summary_text').text.strip()
return {
'Title': title,
'Rating': rating,
'Summary': summary
}
# Example usage
movie_title = input("Enter a movie title: ")
movie_info = get_imdb_movie_info(movie_title)
if movie_info:
print(f"Title: {movie_info['Title']}")
print(f"Rating: {movie_info['Rating']}")
print(f"Summary: {movie_info['Summary']}")
else:
print("Movie not found on IMDb.")
Get it and Change Code
Beautiful Soup strategies like find or find_all can be used to search for specific elements within the page HTML structure.
Error Handling:
Then make your scrape more resilient by making sure it handles probable mistakes, like association problems or unexpected HTML structure.
The example also specifically covers the IMDb site for which these inputs by the user are used to extract data directly from IMDb. Setup—Algorithm for parsing—based on an existing structure of the IMDb website, the Beautiful Soup selectors.
Interact With Websites in Real Time
Interacting with websites in real-time typically involves performing actions on a webpage and receiving immediate feedback or responses without requiring a full page reload. There are several methods to achieve real-time interactions with websites, depending on the use case and technologies involved. Here are some common approaches:
Overall, the choice of the approach for real-time interactions with websites depends on the specific requirements and technologies involved. JavaScript, AJAX, WebSockets, SSE, WebRTC, and push notifications are some of the common technologies used to enable real-time communication and interactivity on modern web applications.
Explore top Python interview questions covering topics like data structures, algorithms, OOP concepts, and problem-solving techniques. Master key Python skills to ace your interview and secure your next developer role.
Lets understand this with help of pro-con of each library , then you can decide for yourself which one is your preference.
Beautiful Soup
pros:
cons:
Requests-HTML
LXML
PyQuery
Selenium
I hope you guys enjoyed this article on “Web Scraping with Python”. I hope this blog was informative and has added value to your knowledge. Now go ahead and try Web Scraping. Experiment with different modules and applications of Python.
If you wish to know about Web Scraping With Python on Windows platform, then the below video will help you understand how to do it or you can also join our Python Master course.
To get in-depth knowledge on Python Programming language along with its various applications, Enroll now in our comprehensive Python Course and embark on a journey to become a proficient Python programmer. Whether you’re a beginner or looking to expand your coding skills, this course will equip you with the knowledge to tackle real-world projects confidently.
Got a question regarding “web scraping with Python”? You can ask it on edureka! Forum and we will get back to you at the earliest or you can join our Python training in Hobart today..







































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
thanks for a great article on web scraping,it was helpful
Hello! great article about web scraping service.
Wonderful! It works perfectly….
syntax error when trying to run the redditbot with crawl, can you help?
Blog was helpful! Thank you so much Omkar bhai?!!
Hey Brunda, we are glad you found the blog helpful! Do take a look at our other blogs too and please do consider subscribing. Cheers!
Really very informative. Easy to understand… Good going Omkar..
Hey Markandeshwar, we are glad you loved the blog. Do check it our other blogs and please do consider subscribing. Cheers!