





UiPath PDF Data Extraction
PDF has been one of the most reliable formats to store data. From hyper-growth companies to small enterprises each and everyone stores data of various kinds in such format. But, imagine if you had to extract the raw data from these PDF documents. Would it be possible to do it manually? Well, the simple answer is no, as it is quite a tedious task, but, if you are familiar with certain services in automation, then you can easily automate this process.
This blog on UiPath PDF Data Extraction will brief you on all the activities that UiPath offers to extract data from PDFs, whether in native text format or scanned images.
To make it easy for you to understand, I have divided this article into the following two sections:
Let’s get started now.
Now, before you actually start extracting data, one important thing that you need to make sure is that you have UiPath.PDF.Activities, from the Manage Packages Section installed on your system. Once you chosen the package, click on Save and the package will start getting installed. Refer to the snapshot below.
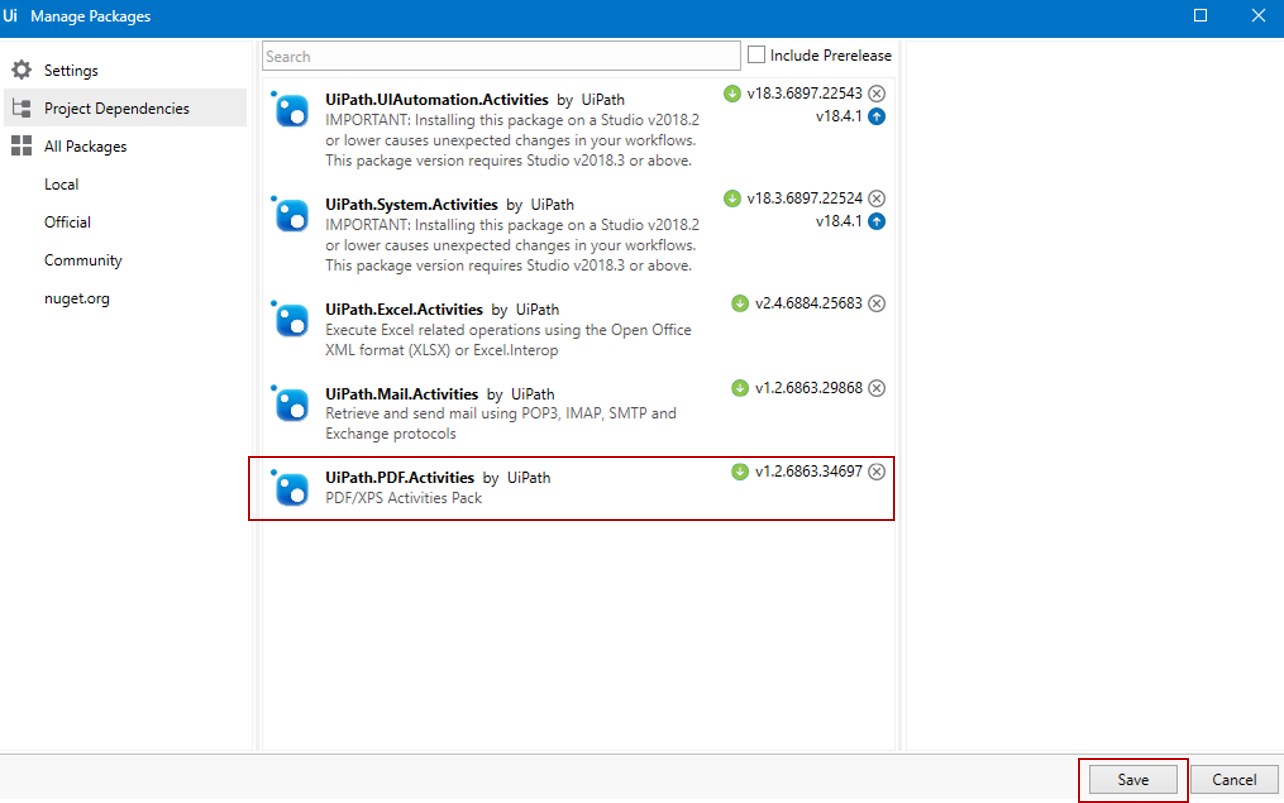 Fig 1: Snapshot of Manage Packages – UiPath PDF Data Extraction
Fig 1: Snapshot of Manage Packages – UiPath PDF Data Extraction
Before we move on if you wish to learn about extracting data from PDFs’ using UiPath, you can refer to the following video. This video will help you gain hands-on experience in data extraction.
UiPath PDF Data Extraction | Edureka
This session on UiPath PDF Data Extraction will cover all the concepts on how to extract data from PDFs using UiPath.
Now, that you know which package has to be installed, let me quickly tell you how to extract large texts in PDF documents.
Extracting Large Texts
There can be instances where, we have a document completely full of text, or a mixture of text and images. Well, extracting large texts pertains to such kind of documents where the documents contain only text or a mixture of both texts and images.
There are mainly two options that UiPath, offers to extract large texts. Those Activities are:
Apart from these, we also have the Screen Scraping Wizard. Let us start with the Read PDF Text Activity.
Read PDF Text Activity
The Read PDF activity is used to extract data from the PDF files which have Text only. So, in case there is an image in the PDF, this activity would not be the right activity to be chosen, as it would not extract the data present in the image.
Let me show you how you can use this activity. But, before that, you can refer to the snapshot below, which showcases the sample PDF file that I am going to use for this blog. In the PDF document, the upper part is Text, and the quoted section is an image.
 Now, I am going to create a sequence, in which I am going to mention the directory of PDF from which the data has to be extracted and I am going to write the output in a message box.
Now, I am going to create a sequence, in which I am going to mention the directory of PDF from which the data has to be extracted and I am going to write the output in a message box.
NOTE: You can write the output to any format of files such as Write Text File, Write Line, Write Cell Activity and so on.
Step 1: Create a Sequence and rename it if you wish to do so. Here, I have renamed it to Extract Text.
Step 2: Drag and drop the Read PDF Text Activity. In the activity, mention the path of the PDF Document from which data has to be extracted.
Step 3: Now, in the Properties Pane, of the Read PDF Text Activity, mention an output variable to see the output. To set an output variable, press on CTRL + K, and give a name. Here I have mentioned as output.
Step 4: After that, drag and drop a message box in the sequence and then mention the output variable in it.
Your complete sequence and the output should look as shown in the below snapshots, respectively.
 Fig 2: Snapshot of Read PDF Text Activity with Output – UiPath PDF Data Extraction
Fig 2: Snapshot of Read PDF Text Activity with Output – UiPath PDF Data Extraction
Here, you can clearly see that the text present in our image was not extracted, and only text present in the sample PDF document was extracted. So, that’s how you folks can use the Read PDF Text Activity.
Now, moving onto the next activity which is the Read PDF with OCR Activity.
Read PDF with OCR Activity
The Read PDF with OCR Activity is used to extract data from the PDF documents which have both Text and Images. So, if you have any images apart from the text in the document, this activity would extract data from those images and give a Text output.
As the activity’s name suggests, this activity uses optical character recognition to scan the images inside the PDF document and output all the text as a variable. So, for that, it needs an OCR Engine. In the Activities Pane, if you search for OCR Engine, you will get a list of installed engines. Refer to the snapshot on the right side.
Now, I am going to create a sequence, in which I am shall mention the directory of PDF from which data has to be extracted and I am going to write the output in a message box. The only difference is, you will see the text in the image also getting extracted.
Follow the below steps, to create automation for extracting text present inside images.
Step 1: Create a Sequence and rename it if you wish to do so. Here, I have renamed it to Extract Text with OCR.
Step 2.1: Drag and drop the Read PDF with OCR Activity. In the activity, mention the path of the PDF Document from which data has to be extracted.
Step 2.2: Now, search for an OCR Engine, and drag and drop an OCR Engine based on whichever is installed. Here I have used Google OCR Engine.
Step 3: Now, in the Properties Pane, of the Read PDF with OCR Activity, mention an output variable to see the output. To set an output variable Press on CTRL + K, and give a name. Here I have mentioned as output.
Step 4: After that, drag and drop a message box in the sequence and then mention the output variable in it.
Your complete sequence and the output should look as shown in the below snapshots, respectively.
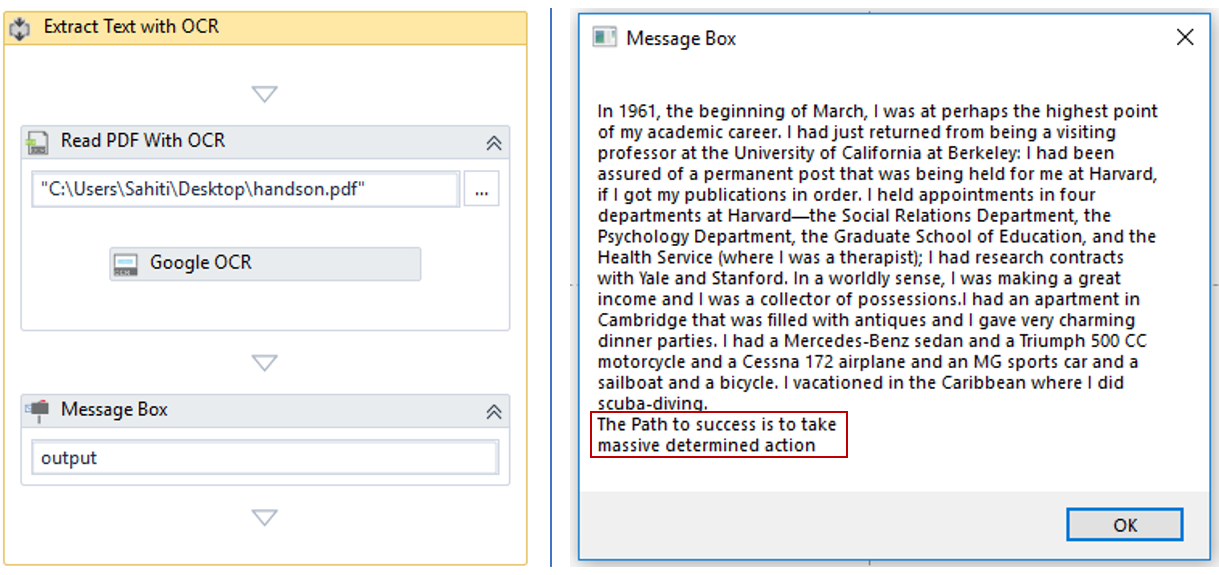 Fig 2: Snapshot of Read PDF with OCR Activity and Output – UiPath PDF Data Extraction
Fig 2: Snapshot of Read PDF with OCR Activity and Output – UiPath PDF Data Extraction
Here, you can clearly see that the text present in the image of the sample document got extracted. So, that’s how you can use the Read PDF with OCR Activity.
Alright, now before I end this part, let me mention a few important pointers about Read PDF with OCR Activity
Key Pointers
In the Properties Pane of Read Text Activity and Read PDF with OCR Activity, we have a parameter called Range. This parameter is used is used to mention the range of page numbers (1, All, 2-10 10-All), from which data has to be extracted.
Both the above-mentioned activities are self-contained, i.e. they don’t need other applications open. So, these activities can execute your tasks even if your PDF Documents are not open on the screen.
Now, apart from the above activities, there is another way to extract data, i.e. by using Screen Scraping Wizard present inside the Design Tab.
Screen Scraping Wizard
Screen Scraping Wizard is a feature provided by UiPath to scrape data from many platforms.
To use this wizard, you can follow the below steps, by keeping your PDF Document open.
Step 1: Click on the Screen Scraping icon, and select the section in the PDF Document you want to extract.
Step 2: Then you will be redirected to the Screen Scraper Wizard that you can see below, with the extracted text. Now, over here you have an option for the Scraping Method (Native/ Full Text/ OCR). Choose the method that you wish and click on Finish.
 Fig 3: Snapshot of Screen Scraper Wizard – UiPath PDF Data Extraction
Fig 3: Snapshot of Screen Scraper Wizard – UiPath PDF Data Extraction
Step 3: Once you click on Finish, the Scraping Wizard will return you to your Sequence. Over here add a message box to see the output and mention the output variable, that is mentioned in the ‘Get Full Text /Get OCR Text’ Activity in the returned sequence. Here the variable name was ‘AvlAvview’, which I mentioned in the message box.
Your complete sequence and the output should look like the below snapshot.

Fig 4: Snapshot of Screen Scraping and Output – UiPath PDF Data Extraction
Here, you can clearly see that the text present in the image of the sample document got extracted, along with the text present in the document. So, that’s how you can use the Screen Scraper Wizard to extract both text and images.
Now, moving on to our next section, i.e. Extracting Specific Elements
Extracting Specific Elements
By extracting specific elements, I mean that there can instances where you want to extract specific elements, such as total from invoices, or contact number from resumes and so on.
There are mainly two options that UiPath, offers to extract large texts. Those Activities are:
Get Text Activity
This activity simply points to the element you’re interested in to extract. Using this activity, text can be extracted, and an output variable can be used. After that, you can either use a Message Box or a Write Text File Activity and mention the output variable.
Refer to the snapshot below to check the sequence and output. Over here, I have extracted Total amount and then displayed the output in a message box.
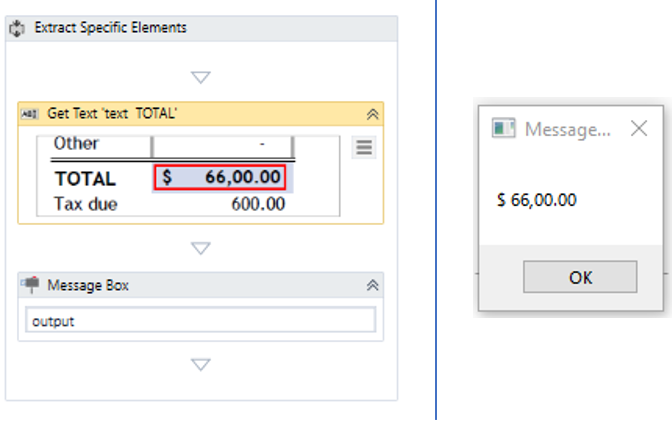 Fig 5: Snapshot of Get Text Activity and Output – UiPath PDF Data Extraction
Fig 5: Snapshot of Get Text Activity and Output – UiPath PDF Data Extraction
So, that’s how you can use the Get Text Action. Now, moving onto our Next Activity which is Anchor-Base Activity.
Anchor-Base Activity
Anchor Base Activity is used to extract text and images. This activity is made up of two actions, as it performs an action in relation to another fixed element or anchor.
So, a typical anchor-base activity mostly has two activities which are used underneath it:
- Find element / Find Image Activity
- Get Text Activity
Find Element / Find Image Activity
The Find Element / Find Image Activity is used to find an element, i.e. text and an image respectively. You can use the activities as per your need. Now, since the Anchor Base activity is a relative activity, you can use the Get Text Activity as I mentioned before.
Refer to the snapshot below. Here I have used the Anchor-Base activity, with the Find Image Activity and Get Text Activity. In the Find Image Activity I have selected Total, so basically Total would be searched and then, in The Get Text Activity, since the value is selected, the value would be extracted.
 Fig 6: Snapshot of Anchor Base Activity – UiPath PDF Data Extraction
Fig 6: Snapshot of Anchor Base Activity – UiPath PDF Data Extraction
Similarly, you could have also used the Find Element Activity.
So, folks! With this, we come to an end to this blog on UiPath PDF Data Extraction.
We at Edureka! also offer RPA Certification Program. If you are interested in shifting your career to RPA, you can enroll for the course here, and get started.
Got a question for us? Please mention it in the comments section of this UiPath PDF Data Extraction blog and we will get back to you.




















