Data is the new fuel of the 21st Century and Hadoop is the segment leader with remarkable data handling capabilities. All this wouldn’t be possible without the high-calibre Hadoop Developers with their outstanding skills. In this article, we shall learn the important Hadoop Developer Skills.
- Who is a Hadoop Developer?
- How to Become a Hadoop Developer?
- Why is Hadoop in such a High Demand?
- Skills required to become a Hadoop Developer
- Roles and Responsibilities of a Hadoop Developer
- Companies Hiring Hadoop Developers
- Hadoop Developer Interview Questions
Who is a Hadoop Developer?
 Hadoop Developer is a professional programmer, with sophisticated knowledge of Hadoop components and tools. A Hadoop Developer, basically designs, develops and deploys Hadoop applications with strong documentation skills.
Hadoop Developer is a professional programmer, with sophisticated knowledge of Hadoop components and tools. A Hadoop Developer, basically designs, develops and deploys Hadoop applications with strong documentation skills.
Are you looking for real-time experience in Hadoop tools and their concepts, then this Online Big Data training course will help to get a real-time project experience from Top Industry Experts.
How to Become a Hadoop Developer?
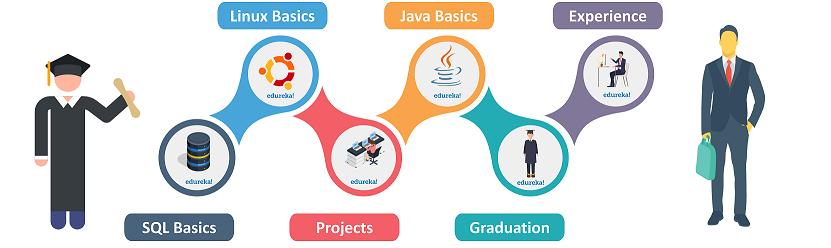
To become a Hadoop Developer, you have to go through the road map described.
A strong grip on the SQL basics and Distributed systems is mandatory.
For a beginner, understanding the terminology of SQL and database would be helpful to learn Hadoop Components.
Strong Programming skills in languages such as Java, Python, JavaScript, NodeJS
Hadoop was developed using Java which gave birth many Programming languages like Scala and Scripting languages PigLatin. Having a good grip on programming languages will be beneficial for a beginner.
Build your own Hadoop Projects in order to understand the terminology of Hadoop
Building your own Hadoop Project will give you a brief understanding of the working of Hadoop tools and components.
A Bachelors or a Masters Degree in Computer Science
A Bachelor’s Degree in computer science and engineering technology is a must to understand the technicalities of Hadoop in depth.
Minimum experience of 2 to 3 years
You might want to work as an intern or join a start-up company for minimum experience in the concerned technology for better chances to get placed as a professional Hadoop developer
Now, we will understand why exactly Hadoop is in such great demand.
Why is Hadoop in such a High Demand?
In the recent job survey according to the biggest job portal, the indeed.com, we have found that Hadoop is extensively used in major sectors amongst all the leading MNCs. The reasons are:
It is highly flexible
It is designed to be fault-tolerant almost any potential attack
Its Hyper data processing capabilities
It is highly cost-effective compared to traditional data servers.
It is easy to maintain and most importantly, it is easily scalable.
Also, there is a huge gap between the vacancies and available Hadoop developers. The below chart explains better.
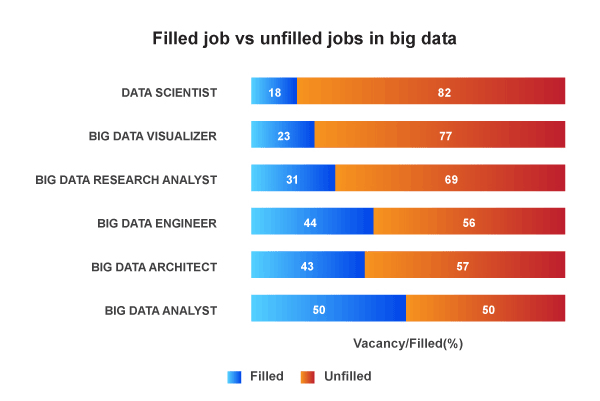
about 50,000 vacancies for Hadoop Developers are available in India.
India is the contributor of 12% of Hadoop Developer jobs in the worldwide market.
Many big MNCs in India are offering handsome salaries for Hadoop Developers in India.
80% of market employers are looking for Hadoop experts.
The Big Data Analytics market in India is currently valued at $2 Billion and is expected to grow at a CAGR of 26 per cent reaching approximately $16 Billion by 2025, making India’s share approximately 32 percent in the overall global market.
This contributes to one-fifth of India’s KPO market worth $5.6 billion.
The Hindu predicts that by the end of 2019, India alone will face a shortage of close to three lakh Data Scientists.
- Learn more about Big Data and its applications from the Data Engineering Courses online.
Skills required to become a Hadoop Developer

For any Hadoop Developer as a beginner, the basic and important skills required are described below.
- Hadoop Fundamental units
- Data Ingestion tools
- Writing Code to Solve Problems
- Top ETL tools
- Machine Learning Tools
- Job Scheduling Tools
- Cluster Computing Tools
Find out our Big Data Hadoop Course in Top Cities
First up, he or she must have a comfortable understanding of the Hadoop Eco-System and its components.
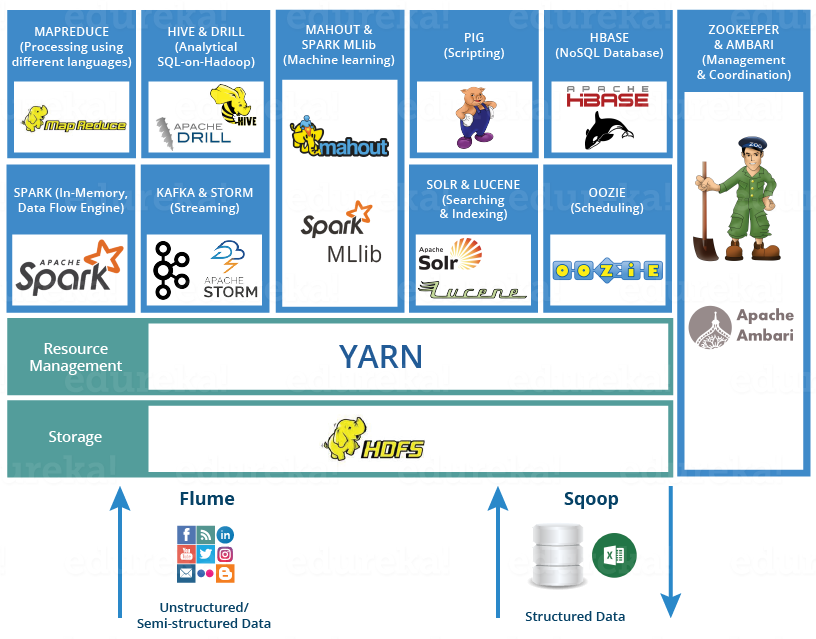
- Hadoop has two fundamental units – Storage and Processing. Hadoop was designed to handle colossal amounts of Big-Data. Unless a developer has hands-on experience with the huge data storage components used in Hadoop, it would be difficult to handle the data. The basic Hadoop Storage units that a beginner needs to know are:
HDFS Hadoop Distributed File System
![]()
HDFS (Hadoop Distributed File System) is a Java-based distributed file system that allows you to store large data across multiple nodes in a Hadoop cluster. Almost all the processing frameworks like the Apache Spark, MapReduce etc, run on top of HDFS.
![]()
Hadoop developers run HBase on top of HDFS (Hadoop Distributed File System). It provides BigTable like capabilities to Hadoop. It is designed to provide a fault-tolerant way of storing a large collection of sparse data sets.

You might also consider learning Spark SQL which is lightning fast when it comes to Data Querying. Spark SQL integrates relational processing with Spark’s functional programming. It provides support for various data sources and makes it possible to weave SQL queries with code transformations thus resulting in a very powerful tool.
Data comes from various sources, and Hadoop is a framework that is designed to deal with almost all types of data, irrelevant of structured, semi-structured or unstructured. Good knowledge of data ingestion tools will come handy while dealing with data from different sources. The popular data ingesting tools available in Hadoop are:

Hadoop Developers use Apache Flume to collect, aggregate and transport a large amount of streaming data such as log files, events from various sources like network traffic, social media, email messages etc. to HDFS. Flume is a highly reliable & distributed.
The main idea behind the Flume’s design is to capture streaming data from various web servers to HDFS. It has a simple and flexible architecture based on streaming data flows. It is fault-tolerant and provides reliability mechanism for Fault-tolerance & failure recovery.

Hadoop Developers, use Apache Sqoop to transfer data between HDFS (Hadoop storage) and relational database servers like MySQL, Oracle RDB, SQLite, Teradata, Netezza, Postgres and many more.
Apache Sqoop imports data from relational databases to HDFS, and exports data from HDFS to relational databases. It efficiently transfers bulk data between Hadoop and external data stores such as enterprise data warehouses, relational databases.
![]()
Hadoop Developers use Apache Kafka as a real-time distributed publish-subscribe messaging system. It was originally developed at LinkedIn and later on became a part of the Apache project. Kafka is fast, agile, scalable and distributed by design. It has the following components.
Kafka Architecture and Terminology :

Topic: A stream of messages belonging to a particular category is called a topic
Producer: A producer can be any application that can publish messages to a topic
Consumer: A consumer can be any application that subscribes to topics and consumes the messages
Broker: Kafka cluster is a set of servers, each of which is called a broker
Once, you are comfortable with the data ingestion tool, the next crucial skill is to be capable enough to write code to solve problems of big-data. To write perfect code, you need to have a better understanding of the data processing tools in Hadoop. The crucial data processing tools are MapReduce and Spark.
![]()
Beginners in Hadoop Development, use MapReduce as a programming framework to perform distributed and parallel processing on large data sets in a distributed environment.
MapReduce has two sub-divided tasks. A Mapper task and Reducer Task. The output of a Mapper or map job (key-value pairs) is input to the Reducer. The reducer receives the key-value pair from multiple map jobs.
![]()
Spark cluster computing framework is used by developers for real-time processing. With a huge open-source community, is the active Apache project. It gives an interface for programming clusters with implicit data parallelism and fault-tolerance.
- Once you have a strong understanding of the basic working of the Hadoop Eco-System, then you can take a step further and learn Data warehousing and the Extract, Transform and Load process.
- The Top ETL tools in Hadoop are:
 Developers used to analyze large data sets representing them as data flows. It is designed to provide an abstraction over MapReduce, reducing the complexities of writing a MapReduce program.
Developers used to analyze large data sets representing them as data flows. It is designed to provide an abstraction over MapReduce, reducing the complexities of writing a MapReduce program.
![]()
Apache Hive is a data warehousing project is used by developers for Data Querying and Data Analytics built on top of Hadoop. It was originally built by Data Infrastructure Team at Facebook.

GraphX is Apache Spark’s API used by developers for graphs and graph-parallel computation. GraphX unifies ETL (Extract, Transform & Load) process, exploratory analysis and iterative graph computation within a single system.
- We all know that Big Data analytics is being extensively used in the field of Artificial Intelligence and Machine Learning. The top Hadoop Frameworks used in Machine Learning are Mahout and Spark ML-Lib.
![]()
Hadoop Developers use Mahout for ML. It enables machines to learn without being overly programmed. It produces scalable machine learning algorithms, extracts recommendations from data sets in a simplified way.

Spark MLlib was designed by the Apache foundation. It is mainly used to perform machine learning on top of Apache Spark. MLlib consists of popular algorithms and utilities.
Managing the Hadoop Eco-System and executing the Hadoop Jos in a cluster is crucial and Apache Oozie happens to be the perfect choice for this.

Apache Oozie is a scheduler system to manage & execute Hadoop jobs in a distributed environment.
Developers create the desired pipeline by combining a different kind of tasks. It can be your Hive, Pig, Sqoop or MapReduce task. Using Apache Oozie you can also schedule your jobs. Within a sequence of the task, two or more jobs can also be programmed to run parallel to each other. It is a scalable, reliable and extensible system.
Hadoop Developers are expected to manage the Hadoop Cluster. Ambari is the most simple and easiest interface to manage a Hadoop Cluster.
Ambari
![]() Apache Ambari is a software project of the Apache software foundation. Hadoop Developers use Ambari for system administrators to provision, manage and monitor a Hadoop cluster, and also to integrate Hadoop with the prevailing
Apache Ambari is a software project of the Apache software foundation. Hadoop Developers use Ambari for system administrators to provision, manage and monitor a Hadoop cluster, and also to integrate Hadoop with the prevailing
So, these were the few key skills required by a Hadoop Developer. Now, let us move further and understand the key roles and responsibilities of a Hadoop Developer.
You can even check out the details of Big Data with the Azure Data Engineering Course in Pune.
Roles and Responsibilities of a Hadoop Developer

The Roles and Responsibilities of Hadoop Developers need a varied skill set to capable enough to handle multiple situations with instantaneous solutions. Because different companies have different issues with their data. Some of the major and general roles and responsibilities of the Hadoop Developer are.
Design, build, install, configure and support Hadoop system
Ability to translate complex technical requirements in detailed a design.
Maintain security and data privacy.
Design scalable and high-performance web services for data tracking.
High-speed data querying.
Defining job flows using schedulers like Zookeeper
Companies Hiring Hadoop Developers
There is a huge demand for Hadoop Developers in the current IT Industry. Some of the major tech giants hiring Hadoop Developers are shown below.

Moving ahead, we will discuss the interview questions for a Hadoop Developer.
Hadoop Developer Interview Questions
This Hadoop Interview Questions Article will redirect you to the most frequently asked interview questions for a Hadoop Developer Profile

With this, we come to an end of this article. I hope I have thrown some light on to your knowledge on a Hadoop Developer Skills along with roles and responsibilities, job trends and Salary trends,
Now that you have understood Big data and its Technologies, check out the Big Data training in India by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. The Edureka Big Data Hadoop Certification Training course helps learners become expert in HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume and Sqoop using real-time use cases on Retail, Social Media, Aviation, Tourism, Finance domain.
If you have any query related to this “Hadoop Developer Skills” article, then please write to us in the comment section below and we will respond to you as early as possible or join our Hadoop Training in Bhubaneswar.