





Big Data Technologies, The Buzz-word which you get to hear much in the recent days. In this article, We shall discuss the groundbreaking technologies which made Big Data spread its branches to reach greater heights.
- What is Big Data Technology?
- Types of Big Data Technology
- Top Big Data Technologies
- Emerging Big Data Technologies
What is Big Data Technology?
Big Data Technology can be defined as a Software-Utility that is designed to Analyse, Process and Extract the information from an extremely complex and large data sets which the Traditional Data Processing Software could never deal with.

We need Big Data Processing Technologies to Analyse this huge amount of Real-time data and come up with Conclusions and Predictions to reduce the risks in the future.
Become a Big Data expert with this Data Architect Certification course online.
Now let us have a look at the Categories in which the Big Data Technologies are classified:
Types of Big Data Technologies:
Big Data Technology is mainly classified into two types:
- Operational Big Data Technologies
- Analytical Big Data Technologies

Firstly, the Operational Big Data is all about the normal day-to-day data that we generate. This could be online transactions, social media interactions, or data from a particular organization. For example, casinos not on Gamstop generate vast amounts of operational data through their gaming activities and user interactions. This raw data is then used to feed analytical Big Data technologies, enabling these casinos to enhance their services and user experience.
Get a better understanding of the technologies from the Big Data Hadoop Course.
A few examples of Operational Big Data Technologies are as follows:
- Online ticket bookings, which includes your Rail tickets, Flight tickets, movie tickets etc.
- Online shopping which is your Amazon, Flipkart, Walmart, Snap deal and many more.
- Data from social media sites like Facebook, Instagram, what’s app and a lot more.
- The employee details of any Multinational Company.
So, with this let us move into the Analytical Big Data Technologies.
Analytical Big Data is like the advanced version of Big Data Technologies. It is a little complex than the Operational Big Data. In short, Analytical big data is where the actual performance part comes into the picture and the crucial real-time business decisions are made by analyzing the Operational Big Data. You can get a better understanding with the Azure Data Engineering certification.
Few examples of Analytical Big Data Technologies are as follows:

- Stock marketing
- Carrying out the Space missions where every single bit of information is crucial.
- Weather forecast information.
- Medical fields where a particular patients health status can be monitored.
Let us have a look at the top Big Data Technologies being used in the IT Industries.
Learn more about Big Data and its applications from the Azure Data Engineering Training in Delhi.
Top Big Data Technologies
Top big data technologies are divided into 4 fields which are classified as follows:
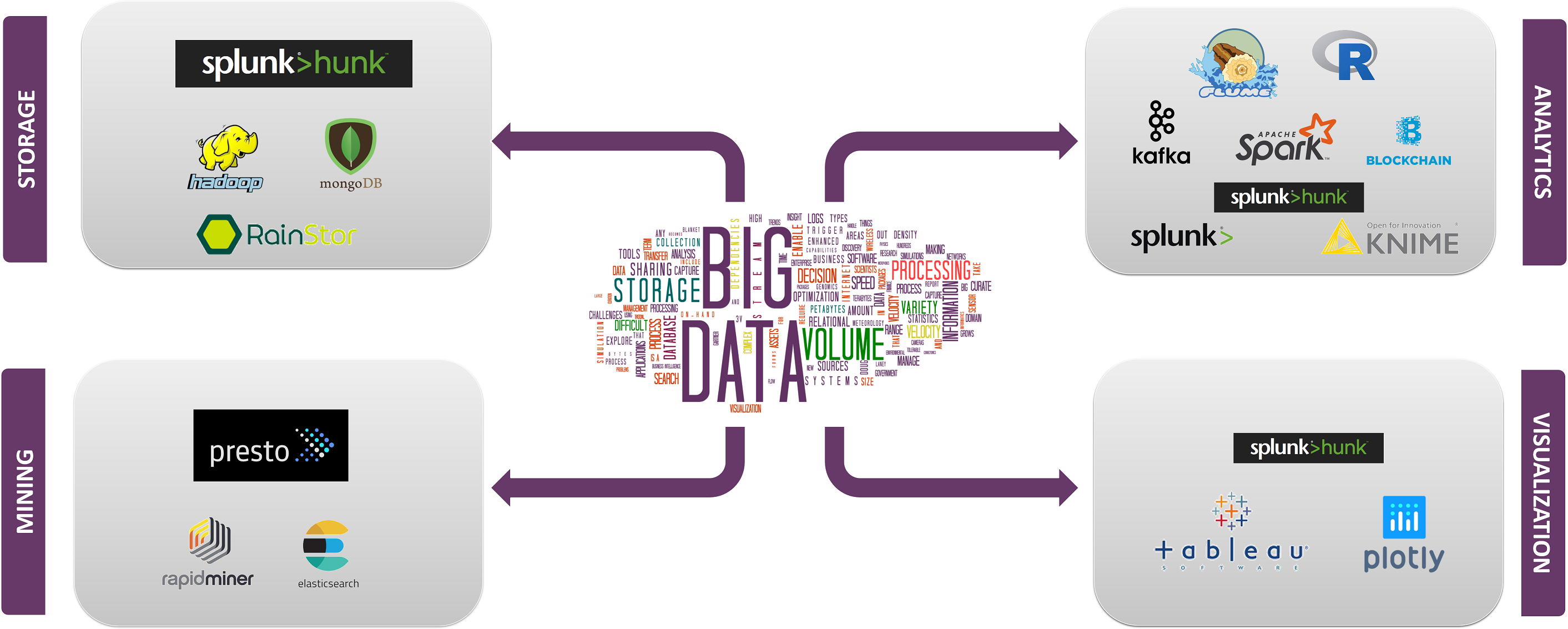
Now let us deal with the technologies falling under each of these categories with their facts and capabilities, along with the companies which are using them. You can even check out the details of Big Data with the Data Engineer Course.
Let us get started with Big Data Technologies in Data Storage.
Data Storage
Hadoop
![]()
Hadoop Framework was designed to store and process data in a Distributed Data Processing Environment with commodity hardware with a simple programming model. It can Store and Analyse the data present in different machines with High Speeds and Low Costs.
- Developed by: Apache Software Foundation in the year 2011 10th of Dec.
- Written in: JAVA
- Current stable version: Hadoop 3.11
Companies Using Hadoop:
MongoDB

The NoSQL Document Databases like MongoDB, offer a direct alternative to the rigid schema used in Relational Databases. This allows MongoDB to offer Flexibility while handling a wide variety of Datatypes at large volumes and across Distributed Architectures.
- Developed by: MongoDB in the year 2009 11th of Feb
- Written in: C++, Go, JavaScript, Python
- Current stable version: MongoDB 4.0.10
Companies Using MongoDB:

Rainstor
![]() RainStor is a software company that developed a Database Management System of the same name designed to Manage and Analyse Big Data for large enterprises. It uses Deduplication Techniques to organize the process of storing large amounts of data for reference.
RainStor is a software company that developed a Database Management System of the same name designed to Manage and Analyse Big Data for large enterprises. It uses Deduplication Techniques to organize the process of storing large amounts of data for reference.
- Developed by: RainStor Software company in the year 2004.
- Works like: SQL
- Current stable version: RainStor 5.5
Companies Using RainStor:

Hunk

Hunk lets you access data in remote Hadoop Clusters through virtual indexes and lets you use the Splunk Search Processing Language to analyse your data. With Hunk, you can Report and Visualize large amounts from your Hadoop and NoSQL data sources.
- Developed by: Splunk INC in the year 2013.
- Written in: JAVA
- Current stable version: Splunk Hunk 6.2
Now, let us move into Big Data Technologies used in Data Mining.
Data Mining
Presto

Presto is an open source Distributed SQL Query Engine for running Interactive Analytic Queries against data sources of all sizes ranging from Gigabytes to Petabytes. Presto allows querying data in Hive, Cassandra, Relational Databases and Proprietary Data Stores.
- Developed by: Apache Foundation in the year 2013.
- Written in: JAVA
- Current stable version: Presto 0.22
Companies Using Presto:

Rapid Miner
![]()
RapidMiner is a Centralized solution that features a very powerful and robust Graphical User Interface that enables users to Create, Deliver, and maintain Predictive Analytics. It allows creating very Advanced Workflows, Scripting support in several languages.
- Developed by: RapidMiner in the year 2001
- Written in: JAVA
- Current stable version: RapidMiner 9.2
Companies Using RapidMiner:

Elasticsearch
![]()
Elasticsearch is a Search Engine based on the Lucene Library. It provides a Distributed, MultiTenant-capable, Full-Text Search Engine with an HTTP Web Interface and Schema-free JSON documents.
- Developed by: Elastic NV in the year 2012.
- Written in: JAVA
- Current stable version: ElasticSearch 7.1
Companies Using Elasticsearch:

With this, we can now move into Big Data Technologies used in Data Analytics.
Data Analytics

Apache Kafka is a Distributed Streaming platform. A streaming platform has Three Key Capabilities that are as follows:
- Publisher
- Subscriber
- Consumer
This is similar to a Message Queue or an Enterprise Messaging System.
- Developed by: Apache Software Foundation in the year 2011
- Written in: Scala, JAVA
- Current stable version: Apache Kafka 2.2.0
Companies Using Kafka:

Splunk
 Splunk captures, Indexes, and correlates Real-time data in a Searchable Repository from which it can generate Graphs, Reports, Alerts, Dashboards, and Data Visualizations. It is also used for Application Management, Security and Compliance, as well as Business and Web Analytics.
Splunk captures, Indexes, and correlates Real-time data in a Searchable Repository from which it can generate Graphs, Reports, Alerts, Dashboards, and Data Visualizations. It is also used for Application Management, Security and Compliance, as well as Business and Web Analytics.
- Developed by: Splunk INC in the year 2014 6th May
- Written in: AJAX, C++, Python, XML
- Current stable version: Splunk 7.3
Companies Using Splunk:

KNIME
 KNIME allows users to visually create Data Flows, Selectively execute some or All Analysis steps, and Inspect the Results, Models, and Interactive views. KNIME is written in Java and based on Eclipse and makes use of its Extension mechanism to add Plugins providing Additional Functionality.
KNIME allows users to visually create Data Flows, Selectively execute some or All Analysis steps, and Inspect the Results, Models, and Interactive views. KNIME is written in Java and based on Eclipse and makes use of its Extension mechanism to add Plugins providing Additional Functionality.
- Developed by: KNIME in the year 2008
- Written in: JAVA
- Current stable version: KNIME 3.7.2
Companies Using KNIME:
 Spark
Spark

Spark provides In-Memory Computing capabilities to deliver Speed, a Generalized Execution Model to support a wide variety of applications, and Java, Scala, and Python APIs for ease of development.
- Developed by: Apache Software Foundation
- Written in: Java, Scala, Python, R
- Current stable version: Apache Spark 2.4.3
Companies Using Spark:


R is a Programming Language and free software environment for Statistical Computing and Graphics. The R language is widely used among Statisticians and Data Miners for developing Statistical Software and majorly in Data Analysis.
- Developed by: R-Foundation in the year 2000 29th Feb
- Written in: Fortran
- Current stable version: R-3.6.0
Companies Using R-Language:

![]() BlockChain is used in essential functions such as payment, escrow, and title can also reduce fraud, increase financial privacy, speed up transactions, and internationalize markets.
BlockChain is used in essential functions such as payment, escrow, and title can also reduce fraud, increase financial privacy, speed up transactions, and internationalize markets.
BlockChain can be used for achieving the following in a Business Network Environment:
- Shared Ledger: Here we can append the Distributed System of records across a Business network.
- Smart Contract: Business terms are embedded in the transaction Database and Executed with transactions.
- Privacy: Ensuring appropriate Visibility, Transactions are Secure, Authenticated and Verifiable
- Consensus: All parties in a Business network agree to network verified transactions.
- Developed by: Bitcoin
- Written in: JavaScript, C++, Python
- Current stable version: Blockchain 4.0
Companies Using Blockchain:

With this, we shall move into Data Visualization Big Data technologies
Data Visualization

Tableau is a Powerful and Fastest growing Data Visualization tool used in the Business Intelligence Industry. Data analysis is very fast with Tableau and the Visualizations created are in the form of Dashboards and Worksheets.
- Developed by: TableAU 2013 May 17th
- Written in: JAVA, C++, Python, C
- Current stable version: TableAU 8.2
Companies Using Tableau:

Plotly
![]()
Mainly used to make creating Graphs faster and more efficient. API libraries for Python, R, MATLAB, Node.js, Julia, and Arduino and a REST API. Plotly can also be used to style Interactive Graphs with Jupyter notebook.
- Developed by: Plotly in the year 2012
- Written in: JavaScript
- Current stable version: Plotly 1.47.4
Companies Using Plotly:
 now let us discuss the Emerging Big Data Technologies
now let us discuss the Emerging Big Data Technologies
Emerging Big Data Technologies

TensorFlow has a Comprehensive, Flexible Ecosystem of tools, Libraries and Community resources that lets Researchers push the state-of-the-art in Machine Learning and Developers can easily build and deploy Machine Learning powered applications.
- Developed by: Google Brain Team in the year 2019
- Written in: Python, C++, CUDA
- Current stable version: TensorFlow 2.0 beta
Companies Using TensorFlow:

Beam
![]()
Apache Beam provides a Portable API layer for building sophisticated Parallel-Data Processing Pipelines that may be executed across a diversity of Execution Engines or Runners.
- Developed by: Apache Software Foundation in the year 2016 June 15th
- Written in: JAVA, Python
- Current stable version: Apache Beam 0.1.0 incubating.
Companies Using Beam:


Docker is a tool designed to make it easier to Create, Deploy, and Run applications by using Containers. Containers allow a developer to Package up an application with all of the parts it needs, such as Libraries and other Dependencies, and Ship it all out as One Package.
- Developed by: Docker INC in the year 2003 13th of March.
- Written in: Go
- Current stable version: Docker 18.09
Companies Using Docker:

Airflow
![]() Apache Airflow is a WorkFlow Automation and Scheduling System that can be used to author and manage Data Pipelines. Airflow uses workflows made of Directed Acyclic Graphs (DAGs) of tasks. Defining Workflows in code provides Easier Maintenance, Testing and Versioning.
Apache Airflow is a WorkFlow Automation and Scheduling System that can be used to author and manage Data Pipelines. Airflow uses workflows made of Directed Acyclic Graphs (DAGs) of tasks. Defining Workflows in code provides Easier Maintenance, Testing and Versioning.
- Developed by: Apache Software Foundation on May 15th 2019
- Written in: Python
- Current stable version: Apache AirFlow 1.10.3
Companies Using AirFlow:

 Kubernetes is a Vendor-Agnostic Cluster and Container Management tool, Open Sourced by Google in 2014. It provides a platform for Automation, Deployment, Scaling, and Operations of Application Containers across Clusters of Hosts.
Kubernetes is a Vendor-Agnostic Cluster and Container Management tool, Open Sourced by Google in 2014. It provides a platform for Automation, Deployment, Scaling, and Operations of Application Containers across Clusters of Hosts.
- Developed by: Cloud Native Computing Foundation in the year 2015 21st of July
- Written in: Go
- Current stable version: Kubernetes 1.14
Companies Using Kubernetes:

With this, we come to an end of this article. I hope I have thrown some light on to your knowledge on Big Data and its Technologies.
For details, You can even check out tools and systems used by Big Data experts and its concepts with the Data engineer online course.
Now that you have understood Big data and its Technologies, check out the Hadoop training in Delhi by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. The Edureka’s Data architecture course helps learners become expert in HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume and Sqoop using real-time use cases on Retail, Social Media, Aviation, Tourism, Finance domain.



































Nice Articles… Thank You…..