

Informatica Certification Training Course
- 22k Enrolled Learners
- Weekend/Weekday
- Live Class
(8600)





 Copy Link!
Copy Link!Dealing with heterogeneous data surely is a tedious task, but as the volume of data increases, it only gets more tiresome. This is where the ETL tools help in transforming this data into homogeneous data. Now, this transformed data is easy to analyze and derive the necessary information from it. In this blog on Talend ETL, I will be talking about how Talend works exceptionally as an ETL Tool to harness valuable insights from Big Data.
In this Talend ETL blog, I will be discussing the following topics:
You could also go through this elaborate video tutorial where our Talend for Big Data Expert explains Talend ETL and data processing with it in a detailed manner with crisp examples.
What Is ETL Process?
ETL stands for Extract, Transform and Load. It refers to a trio of processes which are required to move the raw data from its source to a data warehouse or a database. Let me explain each of these processes in detail:
Extraction of data is the most important step of ETL which involves accessing the data from all the Storage Systems. The storage systems can be the RDBMS, Excel files, XML files, flat files, ISAM (Indexed Sequential Access Method), hierarchical databases (IMS), visual information etc. Being the most vital step, it needs to be designed in such a way that it doesn’t affect the source systems negatively. Extraction process also makes sure that every item’s parameters are distinctively identified irrespective of its source system.
Transformation is the next process in the pipeline. In this step, entire data is analyzed and various functions are applied on it to transform that into the required format. Generally, processes used for the transformation of the data are conversion, filtering, sorting, standardizing, clearing the duplicates, translating and verifying the consistency of various data sources.
Loading is the final stage of the ETL process. In this step, the processed data, i.e. the extracted and transformed data, is then loaded to a target data repository which is usually the databases. While performing this step, it should be ensured that the load function is performed accurately, but by utilizing minimal resources. Also, while loading you have to maintain the referential integrity so that you don’t lose the consistency of the data. Once the data is loaded, you can pick up any chunk of data and compare it with other chunks easily.
Now that you know about the ETL process, you might be wondering how to perform all these? Well, the answer is simple using ETL Tools. In the next section of this Talend ETL blog, I will be talking about the various ETL tools available.
But before I talk about ETL tools, let’s first understand what exactly is an ETL tool.
As I have already discussed, ETL are three separate processes which perform different functions. When all these processes are combined together into a single programming tool which can help in preparing the data and in the managing various databases. These tools have graphical interfaces using which results in speeding up the entire process of mapping tables and columns between the various source and target databases.
There are various ETL tools available in the market, which are quite popularly used. Some of them are:
Among all these tools, in this Talend ETL blog, I will be talking about how Talend as an ETL Tool.
Talend open studio for data integration is one of the most powerful data integration ETL tool available in the market. TOS lets you to easily manage all the steps involved in the ETL process, beginning from the initial ETL design till the execution of ETL data load. This tool is developed on the Eclipse graphical development environment. Talend open studio provides you the graphical environment using which you can easily map the data between the source to the destination system. All you need to do is drag and drop the required components from the palette into the workspace, configure them and finally connect them together. It even provides you a metadata repository from where you can easily reuse and re-purpose your work. This definitely will help you increase your efficiency and productivity over time.
With this, you can conclude that Talend open studio for DI provides an improvised data integration along with strong connectivity, easy adaptability and a smooth flow of extraction and transformation process.
To demonstrate the ETL process, I will be extracting data from an excel file, transform it by applying a filter to the data and then loading the new data into a database. Following is the format of my excel dataset:
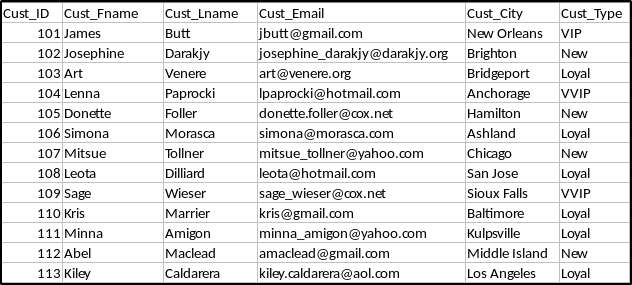
From this data set, I will be filtering out the rows of data based on the customer type and store each of them in a different database table. To perform this follow the below steps:
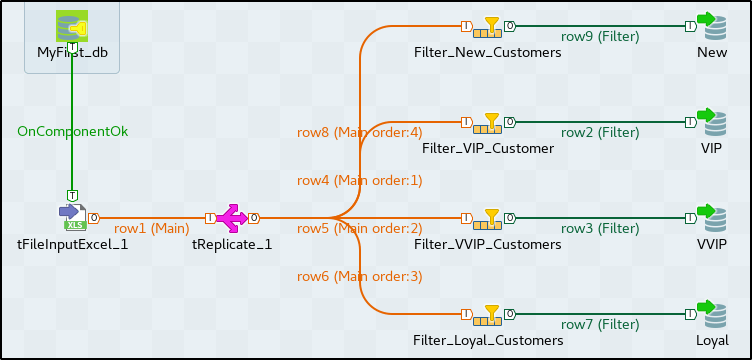
STEP 2: Connect the components together as shown below:
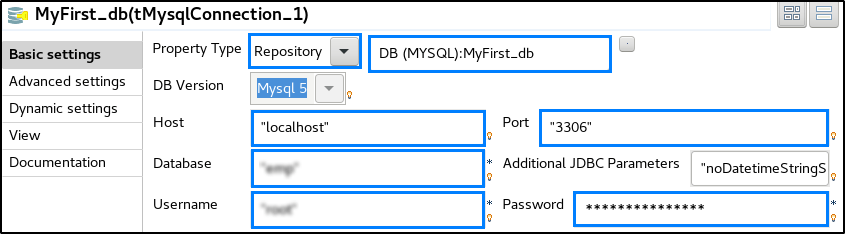
But if you are using a Repository connection then it will pick up the details by default from the Repository.
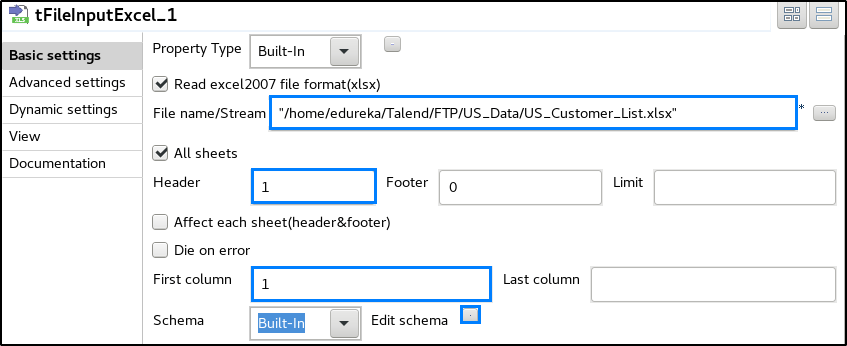
STEP 5: In the component tab of tReplicate, click on ‘Sync columns’.

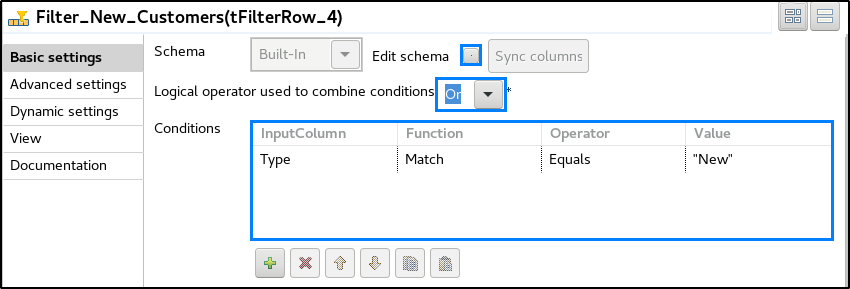
STEP 6: Go to the component tab of the first tFilterRow and check the schema. According to your condition, you can select the column(s) and specify the function, operator and the value on which data should be filtered.
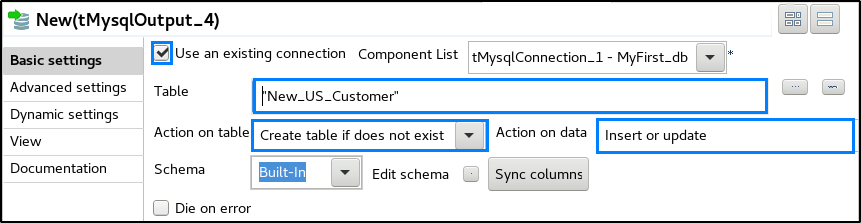
STEP 8: Finally, in the tMysqlOutput’s component tab, check mark on ‘Use an existing connection’. Then specify the table name in ‘Table’ field and select the ‘Action on table’ and ‘Action on data’ as per requirement.
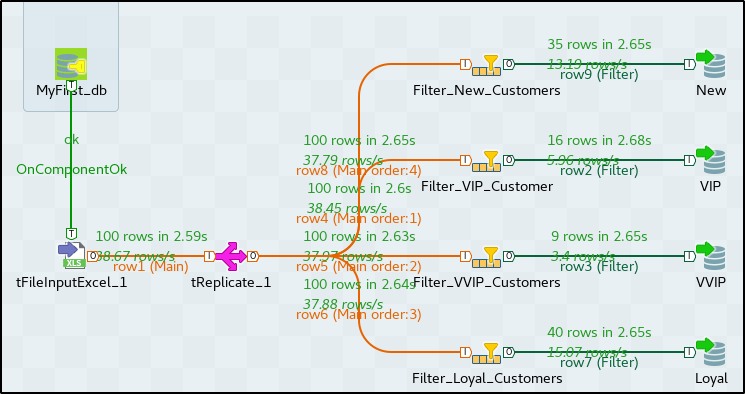
STEP 10: Once done, go to the ‘Run’ tab and execute the job.
This brings us to the end of this blog on Talend ETL. I would conclude this blog with a simple thought which you must follow:
“The future belongs to those who can control their data”

































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP

