
Data Science with Python Certification Course
- 132k Enrolled Learners
- Weekend
- Live Class
(49300)





 Copy Link!
Copy Link!Machine learning is the new age revolution in the computer era. We can perform tasks one can only dream of with the right set of data and relevant algorithms to process the data into getting the optimum results. In this article, we will go through one such classification algorithm in machine learning using python i.e Support Vector Machine In Python. The following topics are covered in this blog:
🐍 Ready to Unleash the Power of Python? Sign Up for Edureka’s Comprehensive Python Certification Course with access to hundreds of Python learning Modules and 24/7 technical support.
Machine learning is the process of feeding a machine enough data to train and predict a possible outcome using the algorithms at bay. The more the data is fed to the machine, the more efficient the machine will become. Let us try to understand this with a real-life example.
I am sure most of you are aware of the predictions made in any sport before any major match. In this case, let us take an example of a football penalty session.
The data of previous performances are considered, let’s say the goalkeeper has saved all the penalties to his right in the last 50 penalties he has saved. This data will be crucial to predicting if he will or will not save the next penalty faces. There are other factors to consider as well.
Another example is the suggestions that we get while surfing the internet, the data of our previous choices are processed to give us the most favorable content we are most likely to watch.
Anyhow, machine learning is not just feeding the machine an ample amount of data, there goes a lot of processes, algorithms and decisive factors to get the optimum results.
In this blog, we will go through one such support vector machine algorithm to understand how it works with python. Before that let us also take a look at the types of machine learning
Supervised Learning – The learning is contained in a controlled way to oversee the outcome accordingly. It is as the name suggest supervised in a way the machine learns what the user wants it to learn.
Unsupervised Learning – In this case, the machine simply explores the data given to it. The data is sometimes, unlabeled and uncategorized and the machine makes the possible references and predictions without any supervision.
Reinforcement Learning – It basically means to enforce a pattern of behavior. The machine needs to establish a systematic pattern of approach in reinforcement learning.
A Support Vector Machine was first introduced in the 1960s and later improvised in the 1990s. It is a supervised learning machine learning classification algorithm that has become extremely popular nowadays owing to its extremely efficient results.
An SVM is implemented in a slightly different way than other machine learning algorithms. It is capable of performing classification, regression and outlier detection.
Support Vector Machine is a discriminative classifier that is formally designed by a separative hyperplane. It is a representation of examples as points in space that are mapped so that the points of different categories are separated by a gap as wide as possible. In addition to this, an SVM can also perform non-linear classification. Let us take a look at how the Support Vector Machine work.
Effective in high dimensional spaces
Still effective in cases where the number of dimensions is greater than the number of samples
Uses a subset of training points in the decision function that makes it memory efficient
Different kernel functions can be specified for the decision function that also makes it versatile
Disadvantages of SVM
If the number of features is much larger than the number of samples, avoid over-fitting in choosing kernel functions and regularization term is crucial.
The main objective of a support vector machine is to segregate the given data in the best possible way. When the segregation is done, the distance between the nearest points is known as the margin. The approach is to select a hyperplane with the maximum possible margin between the support vectors in the given data-sets.

To select the maximum hyperplane in the given sets, the support vector machine follows the following sets:
Generate hyperplanes which segregates the classes in the best possible way
Select the right hyperplane with the maximum segregation from either nearest data points

How to deal with inseparable and non-linear planes
In some cases, hyperplanes can not be very efficient. In those cases, the support vector machine uses a kernel trick to transform the input into a higher-dimensional space. With this, it becomes easier to segregate the points. Let us take a look at the SVM kernels.
An SVM kernel basically adds more dimensions to a low dimensional space to make it easier to segregate the data. It converts the inseparable problem to separable problems by adding more dimensions using the kernel trick. A support vector machine is implemented in practice by a kernel. The kernel trick helps to make a more accurate classifier. Let us take a look at the different kernels in the Support vector machine.
Linear Kernel – A linear kernel can be used as a normal dot product between any two given observations. The product between the two vectors is the sum of the multiplication of each pair of input values. Following is the linear kernel equation.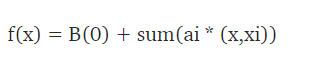
Polynomial Kernel – It is a rather generalized form of the linear kernel. It can distinguish curved or nonlinear input space. Following is the polynomial kernel equation.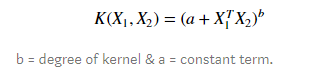
Radial Basis Function Kernel – The radial basis function kernel is commonly used in SVM classification, it can map the space in infinite dimensions. Following is the RBF kernel equation.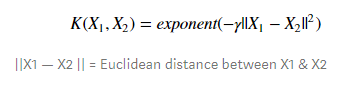
Face Detection
Text And HyperText Categorization
Classification Of Images
Bioinformatics
Protein Fold and Remote Homology Detection
Handwriting Recognition
Generalized Predictive Control
Let us now try to implement what we have learned so far in python using scikit-learn. To make a support vector machine classifier, we will follow the following steps.
Splitting Data
Model Evaluation
Loading The Data
We are using the cancer data-set in the sklearn library, we will make a classifier to predict whether the cancer is malignant or benign. We can load the data-set in the following manner.
from sklearn import datasets cancer_data = datasets.load_breast_cancer() print(cancer_data.data[5]
Output: 
After this, we will explore the data. Take a look at various values in the data-set. Check the target variable, etc.
Explore Data
The shape means that this data-set has 569 rows and 30 columns.
print(cancer_data.data.shape) #target set print(cancer_data.target)
Output: 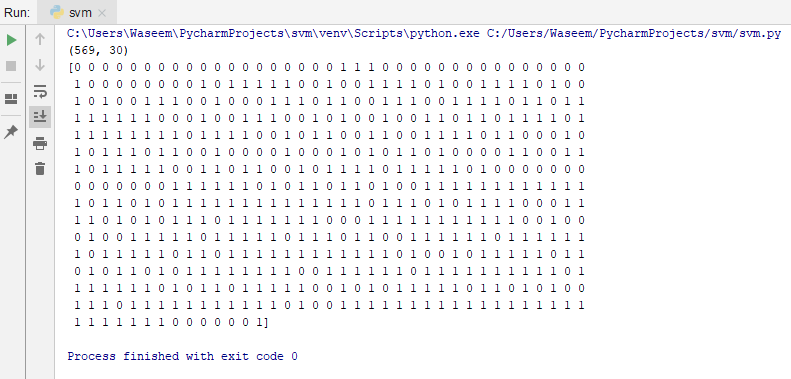
In this, 0 represents malignant, and 1 represents benign.
Splitting Data
We will divide the data-set into a training set and test set to get accurate results. After this, we will split the data using the train_test_split() function. We will need 3 parameters like in the example below. The features to train the model, the target, and the test set size.
from sklearn.model_selection import train_test_split cancer_data = datasets.load_breast_cancer() X_train, X_test, y_train, y_test = train_test_split(cancer_data.data, cancer_data.target, test_size=0.4,random_state=109)
Generating The Model
To generate the model, we will first import the SVM module from sklearn to create a support vector classifier in svc() by passing the argument kernel as the linear kernel.
Then we will train the data-set using the set() and make predictions using the predict() function.
from sklearn import svm #create a classifier cls = svm.SVC(kernel="linear") #train the model cls.fit(X_train,y_train) #predict the response pred = cls.predict(X_test)
With this, we can predict how accurately the model or classifier can predict if the patient has heart disease or not. So we will calculate the accuracy score, recall, and precision for our evaluation.
from sklearn import metrics
#accuracy
print("acuracy:", metrics.accuracy_score(y_test,y_pred=pred))
#precision score
print("precision:", metrics.precision_score(y_test,y_pred=pred))
#recall score
print("recall" , metrics.recall_score(y_test,y_pred=pred))
print(metrics.classification_report(y_test, y_pred=pred))
Output: 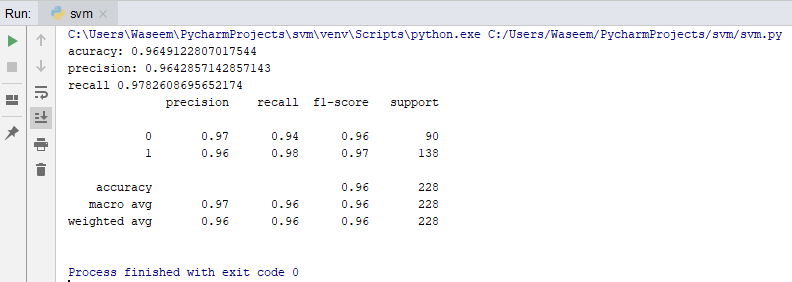
We are getting the accuracy, precision and recall values as 0.96, 0.96 and 0.97 which is highly unlikely. Since our data-set was quite descriptive and decisive we were able to get such accurate results. Normally, anything above a 0.7 accuracy score is a good score.
Let us take a look at another example to understand how we can use the Support Vector Machine classification algorithm in a different way.
Character Recognition With Support Vector Machine
In this example, we will use the existing digit data set and train the classifier. After this, we will use the classifier to predict a digit and plot the image to be more distinct.
import matplotlib.pyplot as plt from sklearn import datasets from sklearn import svm #loading the dataset letters = datasets.load_digits() #generating the classifier clf = svm.SVC(gamma=0.001, C=100) #training the classifier X,y = letters.data[:-10], letters.target[:-10] clf.fit(X,y) #predicting the output print(clf.predict(letters.data[:-10])) plt.imshow(letters.images[6], interpolation='nearest') plt.show()
Output: 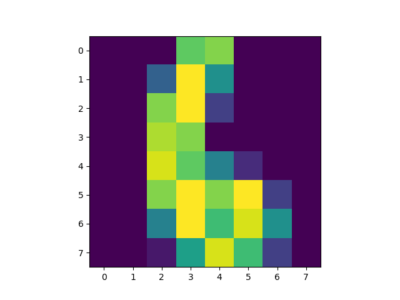
To increase the accuracy we can change the gamma values or C values in the SVC parameter but it will hinder the speed too. If we increase the gamma values, the accuracy will decrease but the speed will increase and vis-a-vis.
This brings us to the end of this article where we have learned how we can work with the support vector machines in Python. I hope you are clear with all that has been shared with you in this tutorial.
If you found this article on “Support Vector Machine In Python” relevant, check out the Edureka’s Python Certification Training, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe.
We are here to help you with every step on your journey and come up with a curriculum that is designed for students and professionals who want to be a Python developer. The course is designed to give you a head start into Python programming and train you for both core and advanced Python concepts along with various Python frameworks like Django.
If you come across any questions, feel free to ask all your questions in the comments section of “Support Vector Machine In Python” and our team will be glad to answer.






































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP