
Agentic AI Certification Training Course
- 138k Enrolled Learners
- Weekend/Weekday
- Live Class
(63442)





 Copy Link!
Copy Link!Supervised Learning is the method, wherein the training data includes both the input and the desired results. Training the system with examples is called supervised learning. Or else, training the algorithm with a teacher can also be treated as supervised learning. After training the algorithm with all sample data or labelled data, which has both the predictors on the target variable, one can train the algorithm and use the unseen example for further classification.
Here are some of the important features of Supervised Learning in Mahout:
In case, you want to train a mission and you are given with two different groups of images along with the labelled data, e.g. in the above picture, one group has the images of an elephant and the other has those of a lion. Labelled data implies each data set to be having a target value. In the above example, the data set is images of elephant, while the label given to it, i.e. “Elephant” is the target value of the data set. Such labelled data set is used for the training process, so that the training algorithm can leverage on this data set and build some model, which can be further used to classify the unseen examples without the labelled data, or target variable.
Let’s identify the features that help in identifying an object as an elephant or a lion:
The Features could be– size, colour, height, ear size, trunk, tusk
This can be called a feature set, which will be used for the training purpose. This feature set will impact the final target variable. These variables are known as predictor variables, because they help us in determining the final target variable. The final variable can also be called a label. The final variable here is Elephant/Lion.
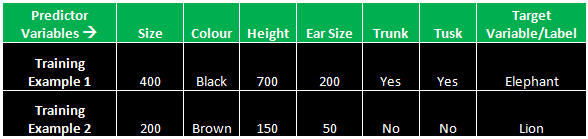
In this example, each of the records in the categories, size, colour, height, ear size, trunk and tusk is a predictor variable, while Elephant and Lion are the target variables. These variables can be treated as training examples and training datasets respectively.
Thus, Supervised Learning is a way, through which you train along with the labels, wherein you ask the algorithm to extract certain features out of it, and based on that, whenever you see an unseen example, the algorithm will be able to classify it into the right class.
Got a question for us? Mention them in the comments section and we will get back to you.
Related Posts:














 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP



