
Data Science with Python Certification Course
- 131k Enrolled Learners
- Weekend
- Live Class
(49300)





 Copy Link!
Copy Link!_1648290501.jpg)
Since the time Data Science has been ranked at number 1 for being the most promising job of the era, we’re all trying to join the race of learning Data Science. This blog post on SQL for Data Science will help you understand how SQL can be used to store, access and retrieve data to perform data analysis.
Did you know that we’re generating more than 2.5 quintillion bytes of data each day? This pace of data generation is the reason behind the popularity of high-end technologies such as Data Science, Artificial Intelligence, Machine Learning and so on.
Enroll for the Data Science PGP Program, a Post Graduate program by Edureka to elevate your career.
Deriving useful insights from data is what is termed as Data Science. Data Science involves extracting, processing, and analyzing tons of data. At present what we need are tools that can be used to store and manage this vast amount of data.

SQL can be used to store, access and extract massive amounts of data in order to carry out the whole Data Science process more smoothly.
Check out this Artificial Intelligence Course by Edureka to upgrade your AI skills to the next level.
SQL which stands for Structured Query Language is a querying language aimed to manage Relational Databases.
But what exactly is a Relational Database?
A relational database is a group of well-defined tables from which data can be accessed, edited, updated and so on, without having to alter the database tables. SQL is the standard (API) for relational databases.
Coming back to SQL, SQL programming can be used to perform multiple actions on data such as querying, inserting, updating, deleting database records. Examples of relational databases that use SQL include MySQL Database, Oracle, etc.
To learn more about SQL, you can go through the following blogs:
Before we get started with a demo on SQL, let’s get familiar with the basic SQL commands.
SQL provides a set of simple commands to modify data tables, let’s go through some of the basic SQL commands:
To better understand SQL, let’s install MySQL and see how you can play with data.
Enroll for the Python for Data Science course by Edureka to elevate your career.
Installing MySQL is a simple task. Here’s a step by step guide that will help you install MySQL on your system.
Once you’re done installing MySQL, follow the below section for a simple demo that will show you how can you insert, manipulate and modify data.
SQL For Data Science – MySQL Demo
In this demonstration, we will see how to create databases and process them. This is a beginner level demonstration to get you started with data analysis on SQL.
So let’s get started!
Step 1: Create a SQL Database
A SQL database is a storage warehouse where data can be stored in a structured format. Now let’s create a database by using MySQL:
CREATE DATABASE edureka; USE edureka;
In the above code, there are two SQL commands:
Note: SQL commands are defined in capital letters and a semi-colon is used to terminate a SQL command.
CREATE DATABASE: This command creates a database called ‘edureka’
USE: This command is used to activate the database. Here we’re activating the ‘edureka’ database.
Step 2: Create a table with the required data features
Creating a table is as simple as creating a database. You just have to define the variables or the features of the table with their respective data types. Let’s see how this can be done:
CREATE TABLE toys (TID INTEGER NOT NULL PRIMARY KEY AUTO_INCREMENT, Item_name TEXT, Price INTEGER, Quantity INTEGER);
In the above code snippet the following things occur:
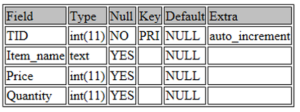
You can further check the details of the defined table by using the following command:
DESCRIBE toys;
Step 3: Inserting data into the table
Now that we’ve created a table, let’s fill it up with some values. Earlier in this blog, I mentioned how you can add data into a table by just using a single command, i.e., INSERT INTO.
Let’s see how this is done:
INSERT INTO toys VALUES (NULL, "Train", 550, 88); INSERT INTO toys VALUES (NULL, "Hotwheels_car", 350, 80); INSERT INTO toys VALUES (NULL, "Magic_Pencil", 70, 100); INSERT INTO toys VALUES (NULL, "Dog_house", 120, 54); INSERT INTO toys VALUES (NULL, "Skateboard", 700, 42); INSERT INTO toys VALUES (NULL, "G.I. Joe", 300, 120);
In the above code snippet, we simply inserted 6 observations into our ‘toys’ table by using the INSERT INTO command. For each observation, within the brackets, I’ve specified the value of each variable or feature that was defined while creating the table.
The TID variable is set to NULL since it auto-increments from 1.
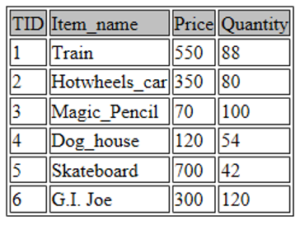
Now let’s display all the data present in our table. This can be done by using the below command:
SELECT * FROM toys;
Step 4: Modify the data entries
Let’s say that you decided to increase the price of the G.I. Joe since it is getting you a lot of customers. How would you update the price of the variable in a database?
It’s simple, just use the below command:
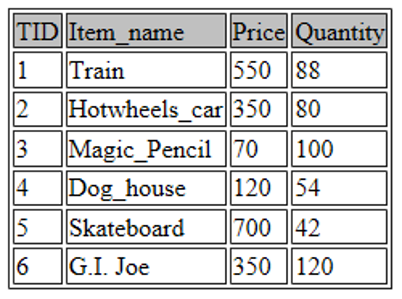
UPDATE toys SET Price=350 WHERE TID=6;
The UPDATE command allows you to modify any values/variables stored in the table. The SET parameter allows you to select a particular feature and the WHERE parameter is used to identify the variable/ value that you want to change. In the above command, I’ve updated the price of the data entry whose TID is 6 (G.I. Joe).
Now let’s view the updated table:
SELECT * FROM toys;
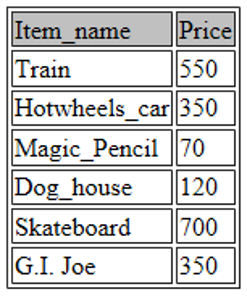
You can also modify what you want to be displayed by just referring to the columns you want to view. For example, the below command will display only the name of the toy and its respective price:
SELECT Item_name, Price FROM toys;
Step 5: Retrieving data
So after inserting the data and modifying it, it’s finally time to extract and retrieve the data according to the business requirements. This is where data can be retrieved for further data analysis and data modeling.
Note that is a simple example to get you started with SQL, however, in real-world scenarios the data is much more complicated and big in size. Despite this, the SQL commands still remain the same and that’s what makes SQL so simple and understandable. It can process complex data sets with a set of simple SQL commands.
Now let’s retrieve data with a couple of modifications. Refer the code below and try to understand what it does without looking at the output:
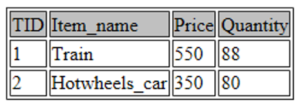
SELECT * FROM toys LIMIT 2;
You guessed it! It displays the first two observations present in my table.
Let’s try something more interesting.
SELECT * FROM toys ORDER BY Price ASC;
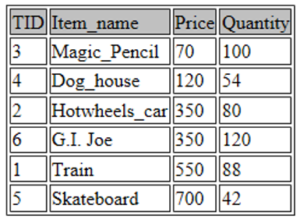
As shown in the figure, the values are arranged with respect to the ascending order of the price variable. If you want to look for the three most frequently bought items, what would you do?
It’s quite simple really!
SELECT * FROM toys ORDER BY Quantity DESC LIMIT 3;
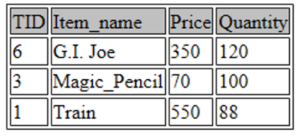
Let’s try one more.
SELECT * FROM toys WHERE Price > 400 ORDER BY Price ASC;
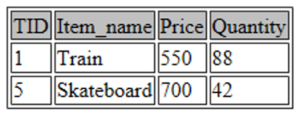
This query extracts the details of the toys whose price is more than 400 and arranges the output in ascending order of the price.
So that’s how you can process data by using SQL. Now that you know the basics of SQL for Data Science, I’m sure you’re curious to learn more. Here are a couple of blogs to get you started:
If you wish to enroll for a complete course on Artificial Intelligence and Machine Learning, Edureka has a specially curated Machine Learning Engineer Master Program that will make you proficient in techniques like Supervised Learning, Unsupervised Learning, and Natural Language Processing. It includes training on the latest advancements and technical approaches in Artificial Intelligence & Machine Learning such as Deep Learning, Graphical Models and Reinforcement Learning.
Also, Edureka has a specially curated Data Science Course that helps you gain expertise in Machine Learning Algorithms like K-Means Clustering, Decision Trees, Random Forest, and Naive Bayes. You’ll learn the concepts of Statistics, Time Series, Text Mining, and an introduction to Deep Learning as well. You’ll solve real-life case studies on Media, Healthcare, Social Media, Aviation, and HR. New batches for this course are starting soon!!




































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP