In this blog, I am going to talk about one of the most trending analytical tool Splunk, which is winning hearts in the fields of big data and operational intelligence. It is a horizontal technology used for application management, security and compliance, as well as business and Web analytics, with tremendous market demand for professionals with Splunk Certification Training. Splunk is a complete solution which helps in searching, analyzing and visualizing the log generated from different machines. Through this Splunk tutorial, I will introduce you to each aspect of Splunk and help you understand how everything fits together to gain insights from it.
But before I start, let me list down the topics that I will be discussing:
- Splunk & it’s advantages
- Architecture
- Splunk Pricing
- Configuration Files
Splunk Introduction
Before getting started with Splunk, have you ever realized the challenges with unstructured data and the logs coming in real-time? For example- live customers queries, increased number of logs through which the size of the dataset keeps on fluctuating every minute. How can all of these problems be tacked? Here, Splunk comes to the rescue.
Splunk is a one-stop solution as it automatically pulls data from various sources and accepts data in any format such as .csv, json, config files, etc. Also, Splunk is the easiest tool to install and allows functionality like: searching, analyzing, reporting as well as visualizing machine data. It has a huge market in the IT infrastructure and business. Many big players in the industry are using Splunk such as Dominos, Adobe, Bosch, Vodafone, Coca-Cola etc.
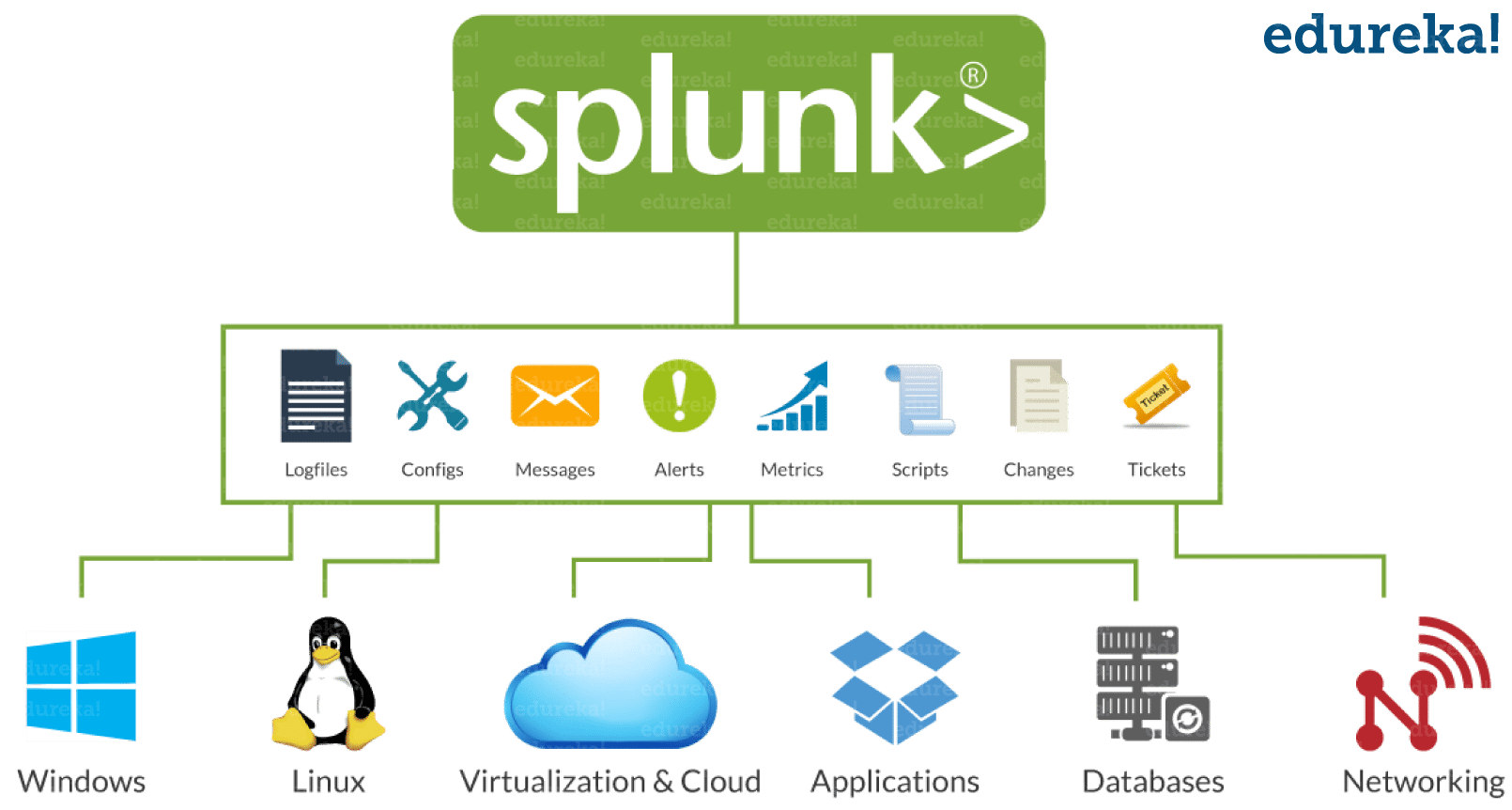
As you can see in the above image, Splunk has some really cool advantages:
- Splunk collects data in real-time from multiple systems
- It accepts data in any form, example- log file, .csv, json, config etc.
- Splunk can pull data from database, cloud and any other OS
- It analyze and visualize the data for better performance
- Splunk give alerts/ event notifications
- Provides real-time visibility
- It satisfies industry needs like horizontal scalability (using many systems in parallel)
Moving ahead in Splunk tutorial, let’s understand how things work internally.
Splunk Architecture
Splunk’s architecture comprises of various components and its functionalities. Refer to the below image which gives a consolidated view of the components involved in the process: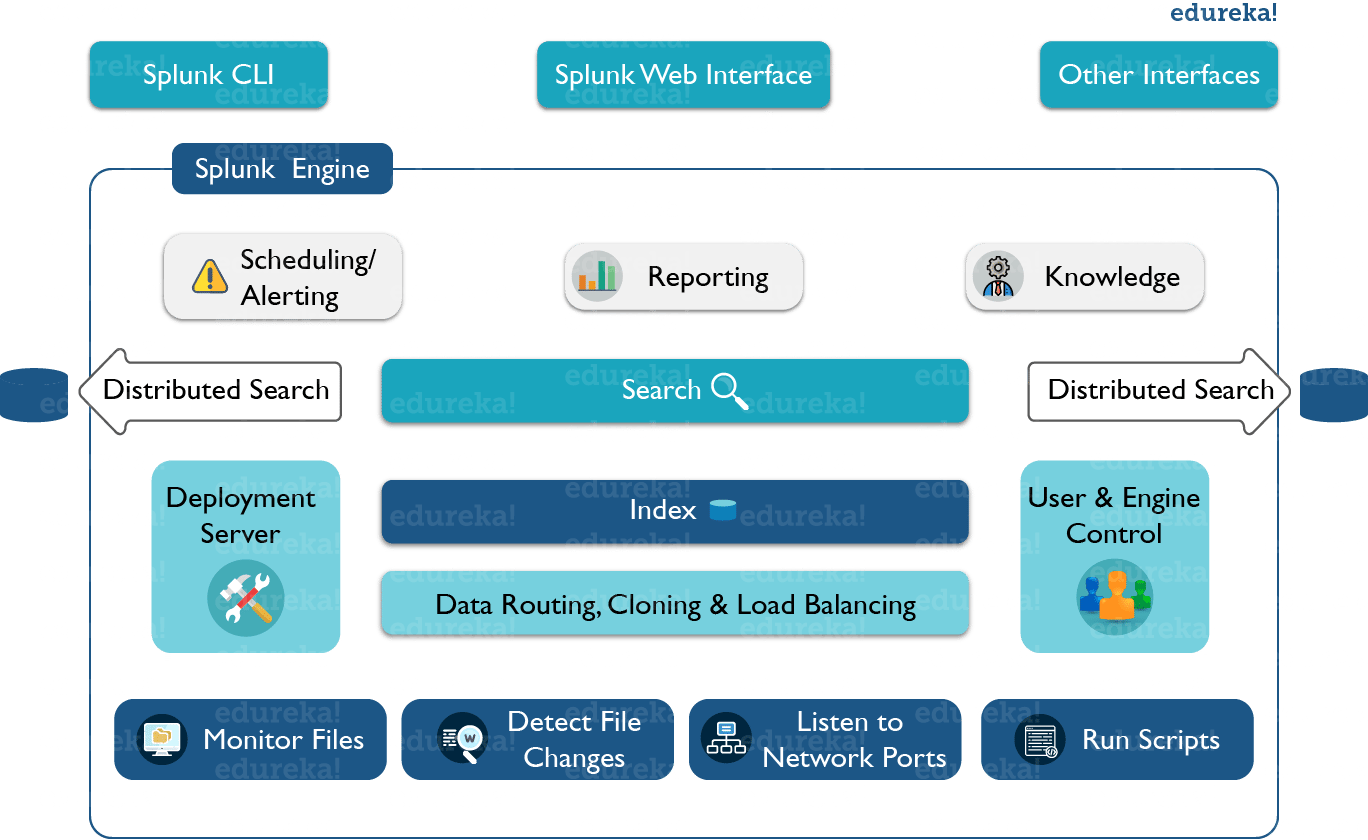
As you can see in the above image, splunk CLI/ splunk web interface or any other interface interacts with the search head. This communication happens via Rest API. You can then use search head to make distributed searches, setup knowledge objects for operational intelligence, perform scheduling/ alerting and create reports or dashboards for visualization. You can also run scripts for automating data forwarding from remote Splunk forwarders to pre-defined network ports. After that you can monitor the files that are coming at real time and analyze if there are any anomalies and set alert/ reminders accordingly. You can also perform routing, cloning and load balancing of the data that is coming in from the forwarder, before they are stored in an indexer. You can also create multiple users to perform various operations on the indexed data.
Splunk Pricing
While indexing the data, the first question that will arise is “How much will it cost?”. Well, it all depends on the volume that you are indexing. So, in a nutshell:
There are major two Splunk editions:
- In Splunk free edition, you can collect and index data upto 500 MB per day. It can be used only by one user where you can search, analyze and visualize the data.
- Splunk Enterprise edition starts from $225 per month. There is no limit for users and you can scale unlimited amount of data per day. You are provided by Enterprise-Grade Support and you can also deploy on-premises in your own cloud, or use Splunk Cloud service. You can perform unlimited searches and monitor them accordingly. There are many such advantages with the enterprise edition.
We have different types of licenses, refer to the below screenshot.
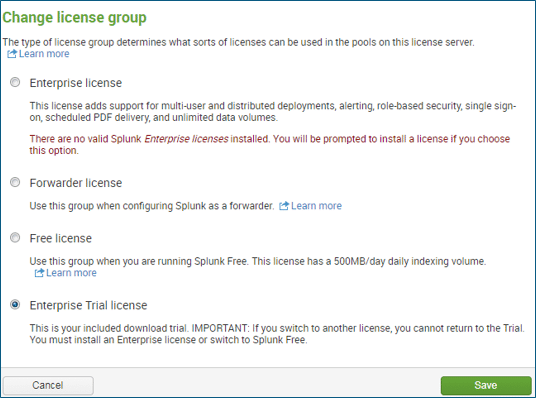
- Enterprise Trial license: You can index 500MB per day but this license is valid only for 60 days. You have all the features enabled such as alerts, multiple user access, distributed search, clustering etc. Now after 60 days, it will convert this license into free license.
- Free License: In free license, you will not have any user access control, it will be only available for one user(Admin). There won’t be any user accounts available, clustering, distributed search and even alerts will be disabled. Therefore, it is only used for performance of log collection & log analyses.
- Forwarder License: Whenever you are setting up heavy forwarder, you should install a forwarder license on it, then only the Splunk instance will turn into a heavy forwarder.
Next, let us move ahead in Splunk tutorial and understand the configuration files.
Splunk Tutorial: Configuration Files
Configuration files play a very important role in the functioning of your Splunk environment. These configuration files contain Splunk system settings, configuration settings and app configuration settings. You can edit these files and accordingly changes will be reflected in your Splunk environment. However, the changes made to configuration files will be taken into effect only if the Splunk instance is restarted.
These configuration files can be found in the below places:
- $SPLUNK_HOME/etc/system/default
- $SPLUNK_HOME/etc/system/local
- $SPLUNK_HOME/etc/apps/
Path where these configuration files are stored is consistent in all operating systems. They are always stored in $SPLUNK_HOME, the directory where Splunk is installed.There is another path where configuration files are stored: $SPLUNK_HOME/etc/users. In this folder, user specific settings in UI, user specific configurations and preference will be stored. As an administrator you can also store user specific settings for multiple Splunk users.
Everything you see in the UI is configurable/ modifiable via the configuration file. In fact there are a lot of options that cannot be edited via UI, but it is possible via CLI or by directly editing a configuration file. Moving ahead in splunk tutorial,let us know discuss the structure of these conf files.
Configuration File Structure
[stanza1] <attr1> = <value> <attr2> = <value>
For example:
[SSL] serverCert = <pathname> password = <password>
In the last section of this Splunk tutorial blog, I will talk about the most common configuration files in Splunk:
- inputs.conf
- outputs.conf
- props.conf
- savedsearches.conf
- indexes.conf
- authentication.conf
- authorize.conf
That brings us to the end of this Splunk tutorial blog. I am pretty sure that by now, most of you have understood the fundamentals of Splunk, so you can start indexing data and gain insights from it.