





The demand for Splunk Certified professionals has seen a tremendous rise, mainly due to the ever-increasing machine-generated log data from almost every advanced technology that is shaping our world today. If you want to implement Splunk in your infrastructure, then it is important that you know how Splunk works internally. I have written this blog to help you understand the Splunk architecture and tell you how different Splunk components interact with one another.
In case you want more clarity on what is Splunk, refer to the Splunk Certification that will give you an understanding of Splunk and tell you why it is a necessity for companies having a huge infrastructure.
Before I talk about how different Splunk components function, let me mention the various stages of data pipeline each component falls under.
Different Stages In Data Pipeline
There are primarily 3 different stages in Splunk:
- Data Input stage
- Data Storage stage
- Data Searching stage

Data Input Stage
In this stage, Splunk software consumes the raw data stream from its source, breaks it into 64K blocks, and annotates each block with metadata keys. The metadata keys include hostname, source, and source type of the data. The keys can also include values that are used internally, such as character encoding of the data stream and values that control the processing of data during the indexing stage, such as the index into which the events should be stored.
Data Storage Stage
Data storage consists of two phases: Parsing and Indexing.
- In Parsing phase, Splunk software examines, analyzes, and transforms the data to extract only the relevant information. This is also known as event processing. It is during this phase that Splunk software breaks the data stream into individual events. The parsing phase has many sub-phases:
- Breaking the stream of data into individual lines
- Identifying, parsing, and setting timestamps
- Annotating individual events with metadata copied from the source-wide keys
- Transforming event data and metadata according to regex transform rules
- In Indexing phase, Splunk software writes parsed events to the index on disk. It writes both compressed raw data and the corresponding index file. The benefit of Indexing is that the data can be easily accessed during searching.
Data Searching Stage
This stage controls how the user accesses, views, and uses the indexed data. As part of the search function, Splunk software stores user-created knowledge objects, such as reports, event types, dashboards, alerts and field extractions. The search function also manages the search process.
Splunk Components
If you look at the below image, you will understand the different data pipeline stages under which various Splunk components fall under.

There are 3 main components in Splunk:
- Splunk Forwarder, used for data forwarding
- Splunk Indexer, used for Parsing and Indexing the data
- Search Head, is a GUI used for searching, analyzing and reporting
Splunk Forwarder
Splunk Forwarder is the component which you have to use for collecting the logs. Suppose, you want to collect logs from a remote machine, then you can accomplish that by using Splunk’s remote forwarders which are independent of the main Splunk instance.
In fact, you can install several such forwarders in multiple machines, which will forward the log data to a Splunk Indexer for processing and storage. What if you want to do real-time analysis of the data? Splunk forwarders can be used for that purpose too. You can configure the forwarders to send data to Splunk indexers in real-time. You can install them in multiple systems and collect the data simultaneously from different machines in real time.
To understand how real time forwarding of data happens, you can read my blog on how Domino’s is using Splunk to gain operational efficiency.
Compared to other traditional monitoring tools, Splunk Forwarder consumes very less cpu ~1-2%. You can scale them up to tens of thousands of remote systems easily, and collect terabytes of data with minimal impact on performance.
Now, let us understand the different types of Splunk forwarders.

Universal Forwarder – You can opt for an universal forwarder if you want to forward the raw data collected at the source. It is a simple component which performs minimal processing on the incoming data streams before forwarding them to an indexer.
Data transfer is a major problem with almost every tool in the market. Since there is minimal processing on the data before it is forwarded, lot of unnecessary data is also forwarded to the indexer resulting in performance overheads.
Why go through the trouble of transferring all the data to the Indexers and then filter out only the relevant data? Wouldn’t it be better to only send the relevant data to the Indexer and save on bandwidth, time and money? This can be solved by using Heavy forwarders which I have explained below.

Heavy Forwarder – You can use a Heavy forwarder and eliminate half your problems, because one level of data processing happens at the source itself before forwarding data to the indexer. Heavy Forwarder typically does parsing and indexing at the source and also intelligently routes the data to the Indexer saving on bandwidth and storage space. So when a heavy forwarder parses the data, the indexer only needs to handle the indexing segment.
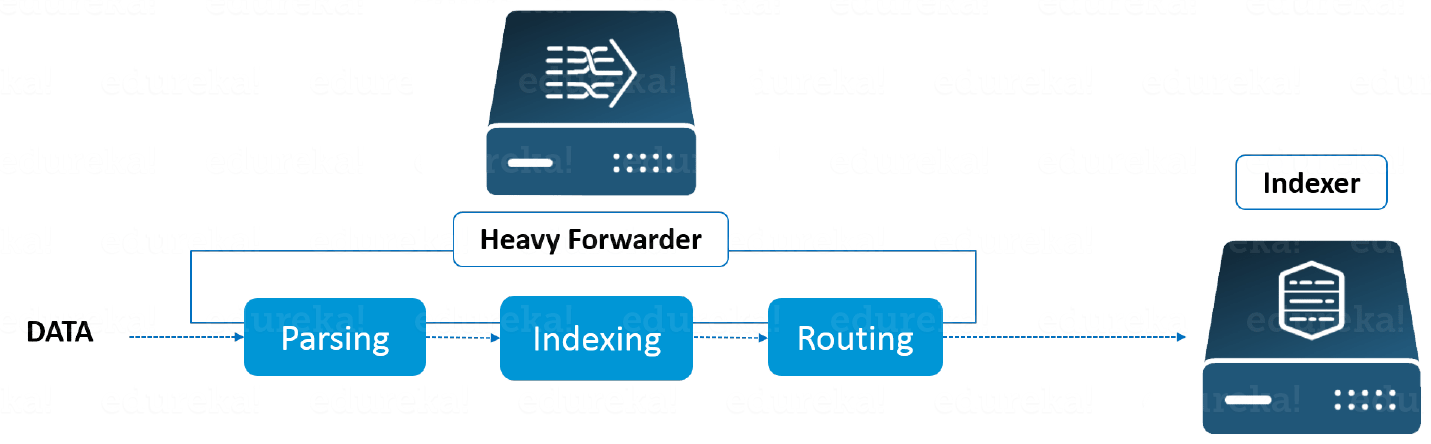
Splunk Indexer

Indexer is the Splunk component which you will have to use for indexing and storing the data coming from the forwarder. Splunk instance transforms the incoming data into events and stores it in indexes for performing search operations efficiently. If you are receiving the data from a Universal forwarder, then the indexer will first parse the data and then index it. Parsing of data is done to eliminate the unwanted data. But, if you are receiving the data from a Heavy forwarder, the indexer will only index the data.
As the Splunk instance indexes your data, it creates a number of files. These files contain one of the below:
- Raw data in compressed form
- Indexes that point to raw data (index files, also referred to as tsidx files), plus some metadata files
These files reside in sets of directories called buckets.
Let me now tell you how Indexing works.
Splunk processes the incoming data to enable fast search and analysis. It enhances the data in various ways like:
- Separating the data stream into individual, searchable events
- Creating or identifying timestamps
- Extracting fields such as host, source, and sourcetype
- Performing user-defined actions on the incoming data, such as identifying custom fields, masking sensitive data, writing new or modified keys, applying breaking rules for multi-line events, filtering unwanted events, and routing events to specified indexes or servers
This indexing process is also known as event processing.
Another benefit with Splunk Indexer is data replication. You need not worry about loss of data because Splunk keeps multiple copies of indexed data. This process is called Index replication or Indexer clustering. This is achieved with the help of an Indexer cluster, which is a group of indexers configured to replicate each other’s’ data.
Splunk Search Head

Search head is the component used for interacting with Splunk. It provides a graphical user interface to users for performing various operations. You can search and query the data stored in the Indexer by entering search words and you will get the expected result.
You can install the search head on separate servers or with other Splunk components on the same server. There is no separate installation file for search head, you just have to enable splunkweb service on the Splunk server to enable it.
A Splunk instance can function both as a search head and a search peer. A search head that performs only searching, and not indexing is referred to as a dedicated search head. Whereas, a search peer performs indexing and responds to search requests from other search heads.
In a Splunk instance, a search head can send search requests to a group of indexers, or search peers, which perform the actual searches on their indexes. The search head then merges the results and sends them back to the user. This is a faster technique to search data called distributed searching.
Search head clusters are groups of search heads that coordinate the search activities. The cluster coordinates the activity of the search heads, allocates jobs based on the current loads, and ensures that all the search heads have access to the same set of knowledge objects.
Advanced Splunk Architecture With A Deployment Server / Management Console Host

Look at the above image to understand the end to end working of Splunk. The images shows a few remote Forwarders that send the data to the Indexers. Based on the data present in the Indexer, you can use the Search Head to perform functions like searching, analyzing, visualizing and creating knowledge objects for Operational Intelligence.
The Management Console Host acts as a centralized configuration manager responsible for distributing configurations, app updates and content updates to the Deployment Clients. The Deployment Clients are Forwarders, Indexers and Search Heads.
Splunk Architecture
If you have understood the concepts explained above, you can easily relate to the Splunk architecture. Look at the image below to get a consolidated view of the various components involved in the process and their functionalities.
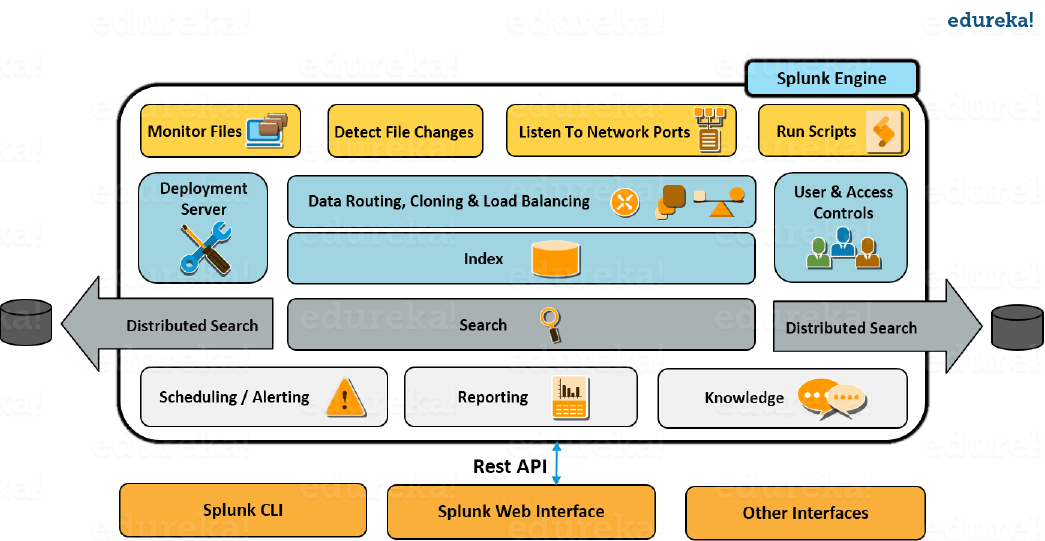
- You can receive data from various network ports by running scripts for automating data forwarding
- You can monitor the files coming in and detect the changes in real time
- The forwarder has the capability to intelligently route the data, clone the data and do load balancing on that data before it reaches the indexer. Cloning is done to create multiple copies of an event right at the data source where as load balancing is done so that even if one instance fails, the data can be forwarded to another instance which is hosting the indexer
- As I mentioned earlier, the deployment server is used for managing the entire deployment, configurations and policies
- When this data is received, it is stored in an Indexer. The indexer is then broken down into different logical data stores and at each data store you can set permissions which will control what each user views, accesses and uses
- Once the data is in, you can search the indexed data and also distribute searches to other search peers and the results will merged and sent back to the Search head
- Apart from that, you can also do scheduled searches and create alerts, which will be triggered when certain conditions match saved searches
- You can use saved searches to create reports and make analysis by using Visualization dashboards
- Finally you can use Knowledge objects to enrich the existing unstructured data
- Search heads and Knowledge objects can be accessed from a Splunk CLI or a Splunk Web Interface. This communication happens over a REST API connection
I hope you enjoyed reading this blog on Splunk Architecture, which talks about the various Splunk components and their working. Stay tuned for reading my next blog on Splunk Knowledge Objects and in the meanwhile you can read my previous blogs in the Splunk tutorial series by clicking on the link below.
Do you want to learn Splunk and implement it in your business? Check out our Splunk training here, which comes with instructor-led live training and real-life project experience.
You can also download the Splunk Tutorial Series e-book.


































Really Helpful
Very good article.
Thank you fr appreciating our work, Ashutosh. Cheers :)
can the indexer and search head be on the same machine for test envirnment
yes but not recommended