





Apache Spark is an open-source cluster computing framework for real-time processing. It is of the most successful projects in the Apache Software Foundation. Spark has clearly evolved as the market leader for Big Data processing. Today, Spark is being adopted by major players like Amazon, eBay, and Yahoo! Many organizations run Spark on clusters with thousands of nodes and there is a huge opportunity in your career to become a Spark certified professional. We are excited to begin this exciting journey through this Spark Tutorial blog. This blog is the first blog in the upcoming Apache Spark blog series which will include Spark Streaming, Spark Interview Questions, Spark MLlib and others.
When it comes to Real Time Data Analytics, Spark stands as the go-to tool across all other solutions. Through this blog, I will introduce you to this new exciting domain of Apache Spark and we will go through a complete use case, Earthquake Detection using Spark.
Spark Tutorial: Real Time Analytics
Before we begin, let us have a look at the amount of data generated every minute by social media leaders.
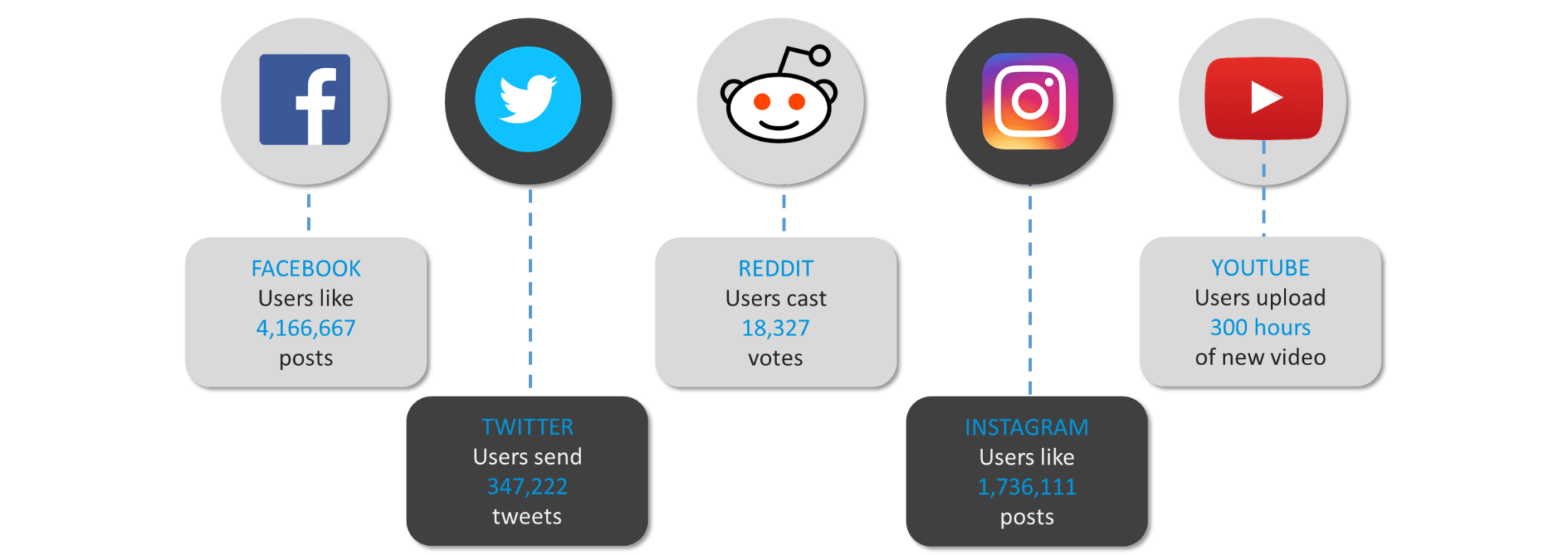
Figure: Amount of data generated every minute
As we can see, there is a colossal amount of data that the internet world necessitates to process in seconds. We will go through all the stages of handling big data in enterprises and discover the need for a Real Time Processing Framework called Apache Spark.
To begin with, let me introduce you to few domains using real-time analytics big time in today’s world.

Figure: Spark Tutorial – Examples of Real Time Analytics
We can see that Real Time Processing of Big Data is ingrained in every aspect of our lives. From fraud detection in banking to live surveillance systems in government, automated machines in healthcare to live prediction systems in the stock market, everything around us revolves around processing big data in near real time.
Let us look at some of these use cases of Real Time Analytics:
- Healthcare: Healthcare domain uses Real Time analysis to continuously check the medical status of critical patients. Hospitals on the look out for blood and organ transplants need to stay in a real-time contact with each other during emergencies. Getting medical attention on time is a matter of life and death for patients.
- Government: Government agencies perform Real Time Analysis mostly in the field of national security. Countries need to continuously keep a track of all the military and police agencies for updates regarding threats to security.
- Telecommunications: Companies revolving around services in the form of calls, video chats and streaming use real-time analysis to reduce customer churn and stay ahead of the competition. They also extract measurements of jitter and delay in mobile networks to improve customer experiences.
- Banking: Banking transacts with almost all of the world’s money. It becomes very important to ensure fault tolerant transactions across the whole system. Fraud detection is made possible through real-time analytics in banking.
- Stock Market: Stockbrokers use real-time analytics to predict the movement of stock portfolios. Companies re-think their business model after using real-time analytics to analyze the market demand for their brand.
Spark Tutorial: Why Spark when Hadoop is already there?
The first of the many questions everyone asks when it comes to Spark is, “Why Spark when we have Hadoop already?“.
To answer this, we have to look at the concept of batch and real-time processing. Hadoop is based on the concept of batch processing where the processing happens of blocks of data that have already been stored over a period of time. At the time, Hadoop broke all the expectations with the revolutionary MapReduce framework in 2005. Hadoop MapReduce is the best framework for processing data in batches.
This went on until 2014, till Spark overtook Hadoop. The USP for Spark was that it could process data in real time and was about 100 times faster than Hadoop MapReduce in batch processing large data sets.
The following figure gives a detailed explanation of the differences between processing in Spark and Hadoop.
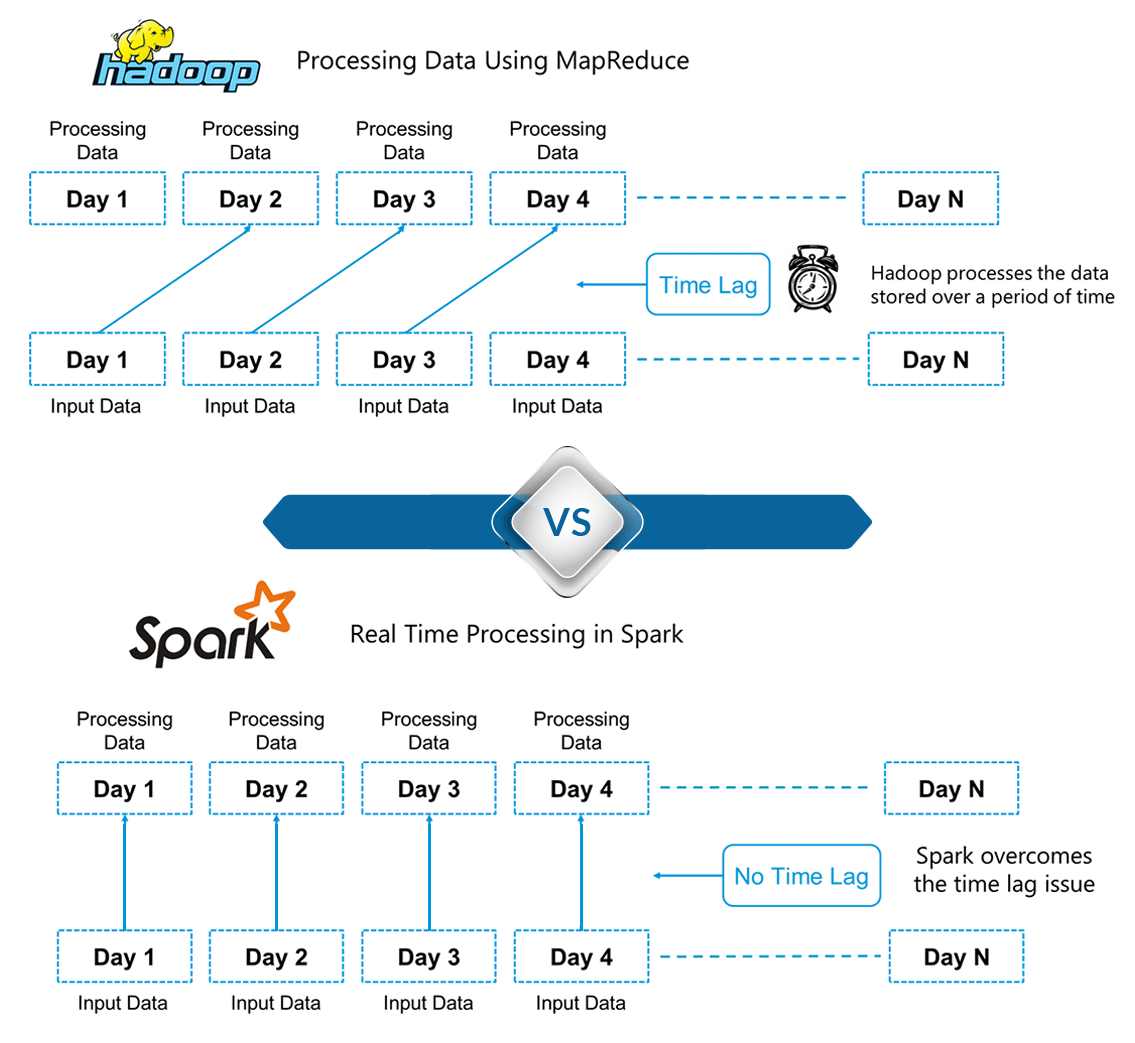 Figure: Spark Tutorial – Differences between Hadoop and Spark
Figure: Spark Tutorial – Differences between Hadoop and Spark
Here, we can draw out one of the key differentiators between Hadoop and Spark. Hadoop is based on batch processing of big data. This means that the data is stored over a period of time and is then processed using Hadoop. Whereas in Spark, processing can take place in real-time. This real-time processing power in Spark helps us to solve the use cases of Real Time Analytics we saw in the previous section. Alongside this, Spark is also able to do batch processing 100 times faster than that of Hadoop MapReduce (Processing framework in Apache Hadoop). Therefore, Apache Spark is the go-to tool for big data processing in the industry.
Spark Tutorial: What is Apache Spark?
Apache Spark is an open-source cluster computing framework for real-time processing. It has a thriving open-source community and is the most active Apache project at the moment. Spark provides an interface for programming entire clusters with implicit data parallelism and fault-tolerance.
 Figure: Spark Tutorial – Real Time Processing in Apache Spark
Figure: Spark Tutorial – Real Time Processing in Apache Spark
It was built on top of Hadoop MapReduce and it extends the MapReduce model to efficiently use more types of computations.
Spark Tutorial: Features of Apache Spark
Spark has the following features:
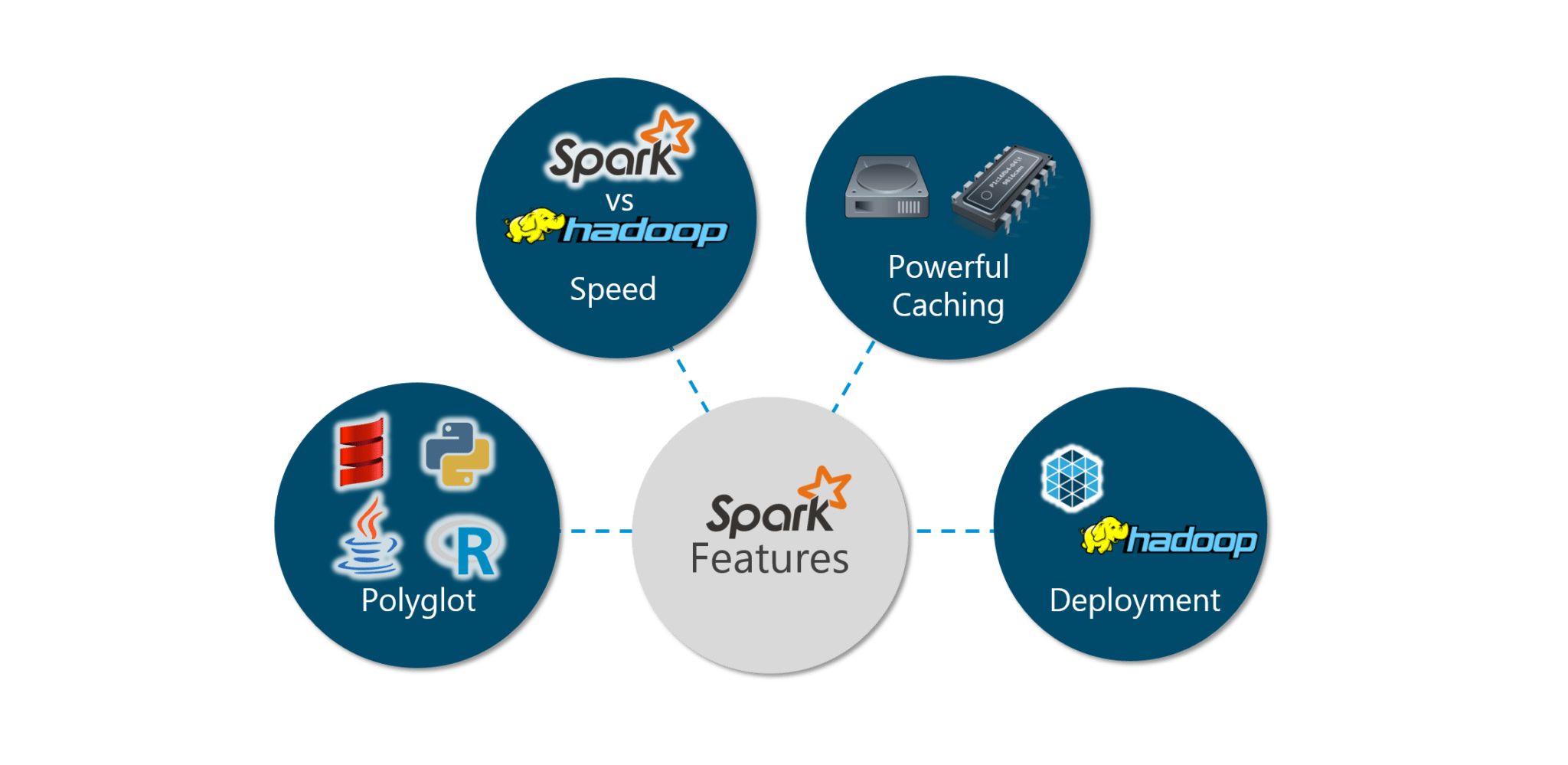 Figure: Spark Tutorial – Spark Features
Figure: Spark Tutorial – Spark Features
Let us look at the features in detail:
| Polyglot: Spark provides high-level APIs in Java, Scala, Python and R. Spark code can be written in any of these four languages. It provides a shell in Scala and Python. The Scala shell can be accessed through ./bin/spark-shell and Python shell through ./bin/pyspark from the installed directory. |  |
Speed: Spark runs up to 100 times faster than Hadoop MapReduce for large-scale data processing. Spark is able to achieve this speed through controlled partitioning. It manages data using partitions that help parallelize distributed data processing with minimal network traffic. |

| Multiple Formats: Spark supports multiple data sources such as Parquet, JSON, Hive and Cassandra apart from the usual formats such as text files, CSV and RDBMS tables. The Data Source API provides a pluggable mechanism for accessing structured data though Spark SQL. Data sources can be more than just simple pipes that convert data and pull it into Spark. |  |
 | Lazy Evaluation: Apache Spark delays its evaluation till it is absolutely necessary. This is one of the key factors contributing to its speed. For transformations, Spark adds them to a DAG (Directed Acyclic Graph) of computation and only when the driver requests some data, does this DAG actually gets executed. |
| Real Time Computation: Spark’s computation is real-time and has low latency because of its in-memory computation. Spark is designed for massive scalability and the Spark team has documented users of the system running production clusters with thousands of nodes and supports several computational models. |  |
 | Hadoop Integration: Apache Spark provides smooth compatibility with Hadoop. This is a boon for all the Big Data engineers who started their careers with Hadoop. Spark is a potential replacement for the MapReduce functions of Hadoop, while Spark has the ability to run on top of an existing Hadoop cluster using YARN for resource scheduling. |
Machine Learning: Spark’s MLlib is the machine learning component which is handy when it comes to big data processing. It eradicates the need to use multiple tools, one for processing and one for machine learning. Spark provides data engineers and data scientists with a powerful, unified engine that is both fast and easy to use. |  |
Spark Tutorial: Getting Started With Spark
The first step in getting started with Spark is installation. Let us install Apache Spark 2.1.0 on our Linux systems (I am using Ubuntu).
Installation:
- The prerequisites for installing Spark is having Java and Scala installed.
- Download Java in case it is not installed using below commands.
sudo apt-get install python-software-properties sudo apt-add-repository ppa:webupd8team/java sudo apt-get update sudo apt-get install oracle-java8-installer
- Download the latest Scala version from Scala Lang Official page. Once installed, set the scala path in
~/.bashrcfile as shown below.export SCALA_HOME=Path_Where_Scala_File_Is_Located export PATH=$SCALA_HOME/bin:PATH
- Download Spark 2.1.0 from the Apache Spark Downloads page. You can also choose to download a previous version.
- Extract Spark tar using below command.
tar -xvf spark-2.1.0-bin-hadoop2.7.tgz
- Set the Spark_Path in
~/.bashrcfile.export SPARK_HOME=Path_Where_Spark_Is_Installed export PATH=$PATH:$SPARK_HOME/bin
Before we move further, let us start up Apache Spark on our systems and get used to the main concepts of Spark like Spark Session, Data Sources, RDDs, DataFrames and other libraries.
Spark Shell:
Spark’s shell provides a simple way to learn the API, as well as a powerful tool to analyze data interactively.
Spark Session:
In earlier versions of Spark, Spark Context was the entry point for Spark. For every other API, we needed to use different contexts. For streaming, we needed StreamingContext, for SQL sqlContext and for hive HiveContext. To solve this issue, SparkSession came into the picture. It is essentially a combination of SQLContext, HiveContext and future StreamingContext.
Data Sources:
The Data Source API provides a pluggable mechanism for accessing structured data though Spark SQL. Data Source API is used to read and store structured and semi-structured data into Spark SQL. Data sources can be more than just simple pipes that convert data and pull it into Spark.
RDD:
Resilient Distributed Dataset (RDD) is a fundamental data structure of Spark. It is an immutable distributed collection of objects. Each dataset in RDD is divided into logical partitions, which may be computed on different nodes of the cluster. RDDs can contain any type of Python, Java, or Scala objects, including user-defined classes.
Dataset:
A Dataset is a distributed collection of data. A Dataset can be constructed from JVM objects and then manipulated using functional transformations (map, flatMap, filter, etc.). The Dataset API is available in Scala and Java.
DataFrames:
A DataFrame is a Dataset organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases or existing RDDs.
Spark Tutorial: Using Spark with Hadoop
The best part of Spark is its compatibility with Hadoop. As a result, this makes for a very powerful combination of technologies. Here, we will be looking at how Spark can benefit from the best of Hadoop.
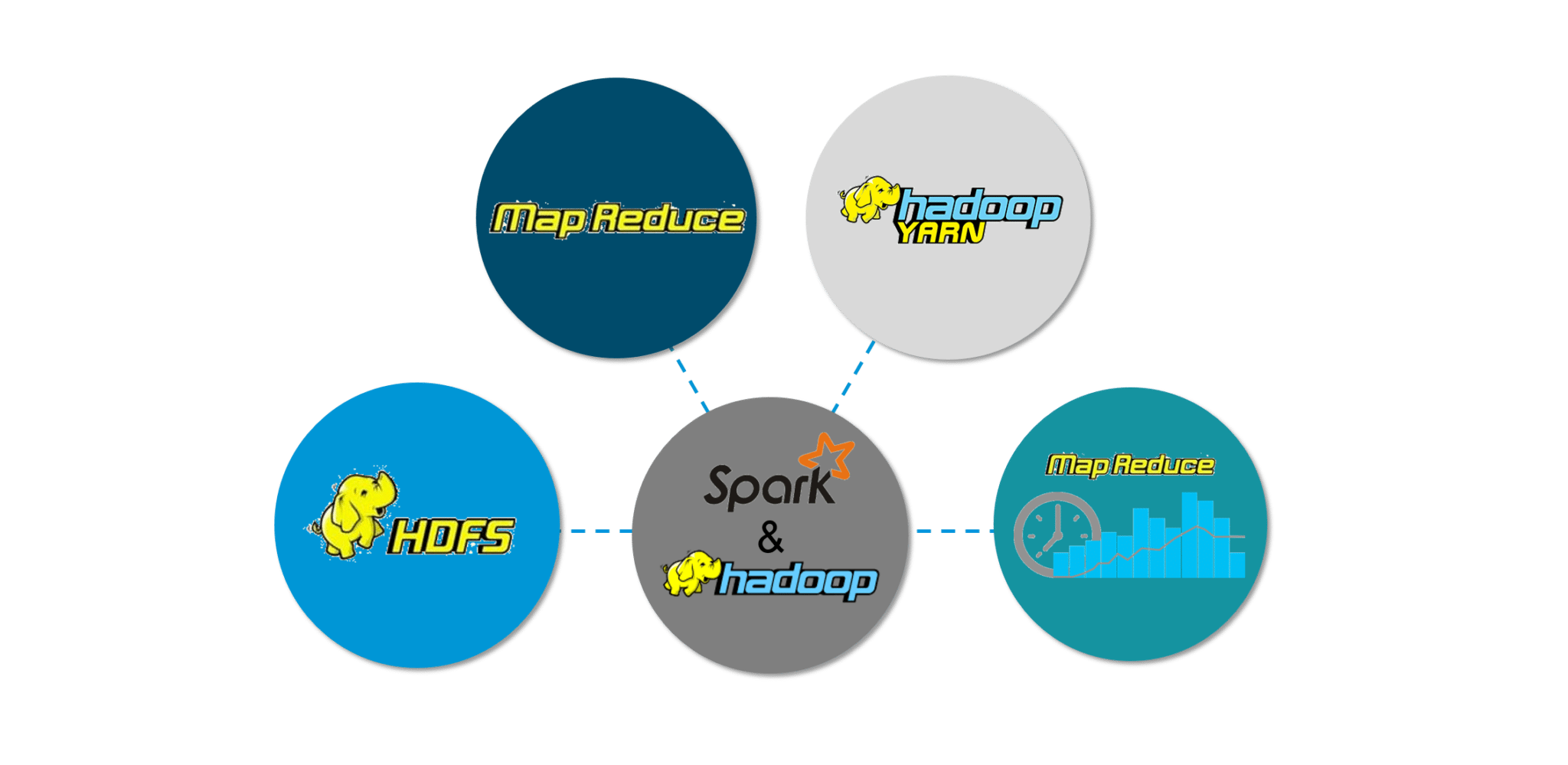 Figure: Spark Tutorial – Spark Features
Figure: Spark Tutorial – Spark Features
Hadoop components can be used alongside Spark in the following ways:
- HDFS: Spark can run on top of HDFS to leverage the distributed replicated storage.
- MapReduce: Spark can be used along with MapReduce in the same Hadoop cluster or separately as a processing framework.
- YARN: Spark applications can be made to run on YARN (Hadoop NextGen).
- Batch & Real Time Processing: MapReduce and Spark are used together where MapReduce is used for batch processing and Spark for real-time processing.
Spark Tutorial: Spark Components
Spark components are what make Apache Spark fast and reliable. A lot of these Spark components were built to resolve the issues that cropped up while using Hadoop MapReduce. Apache Spark has the following components:
- Spark Core
- Spark Streaming
- Spark SQL
- GraphX
- MLlib (Machine Learning)
Spark Core
Spark Core is the base engine for large-scale parallel and distributed data processing. The core is the distributed execution engine and the Java, Scala, and Python APIs offer a platform for distributed ETL application development. Further, additional libraries which are built atop the core allow diverse workloads for streaming, SQL, and machine learning. It is responsible for:
- Memory management and fault recovery
- Scheduling, distributing and monitoring jobs on a cluster
- Interacting with storage systems
Spark Streaming
Spark Streaming is the component of Spark which is used to process real-time streaming data. Thus, it is a useful addition to the core Spark API. It enables high-throughput and fault-tolerant stream processing of live data streams. The fundamental stream unit is DStream which is basically a series of RDDs (Resilient Distributed Datasets) to process the real-time data.
 Figure: Spark Tutorial – Spark Streaming
Figure: Spark Tutorial – Spark Streaming
Spark SQL
Spark SQL is a new module in Spark which integrates relational processing with Spark’s functional programming API. It supports querying data either via SQL or via the Hive Query Language. For those of you familiar with RDBMS, Spark SQL will be an easy transition from your earlier tools where you can extend the boundaries of traditional relational data processing.
Spark SQL integrates relational processing with Spark’s functional programming. Further, it provides support for various data sources and makes it possible to weave SQL queries with code transformations thus resulting in a very powerful tool.
The following are the four libraries of Spark SQL.
- Data Source API
- DataFrame API
- Interpreter & Optimizer
- SQL Service
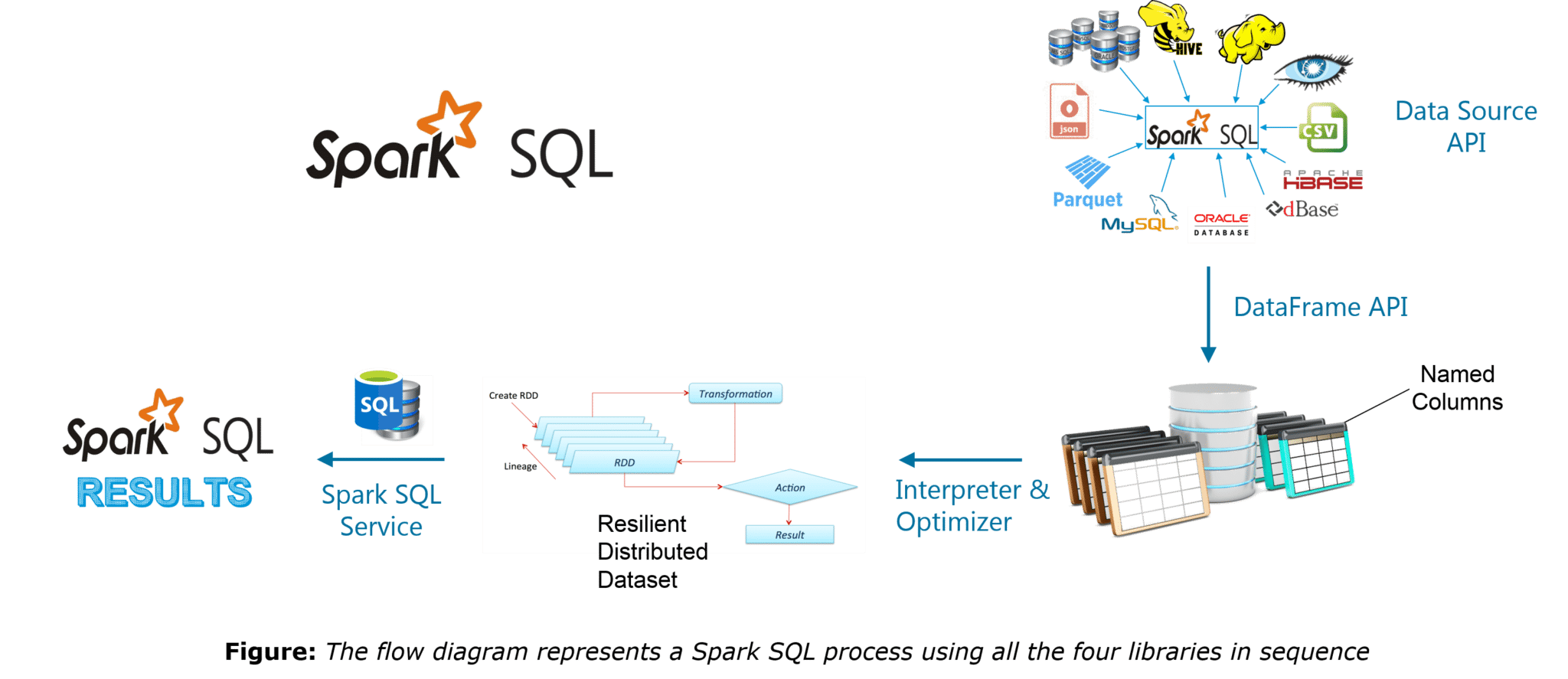
A complete tutorial on Spark SQL can be found in the given blog: Spark SQL Tutorial Blog
GraphX
GraphX is the Spark API for graphs and graph-parallel computation. Thus, it extends the Spark RDD with a Resilient Distributed Property Graph.
The property graph is a directed multigraph which can have multiple edges in parallel. Every edge and vertex have user defined properties associated with it. Here, the parallel edges allow multiple relationships between the same vertices. At a high-level, GraphX extends the Spark RDD abstraction by introducing the Resilient Distributed Property Graph: a directed multigraph with properties attached to each vertex and edge.
To support graph computation, GraphX exposes a set of fundamental operators (e.g., subgraph, joinVertices, and mapReduceTriplets) as well as an optimized variant of the Pregel API. In addition, GraphX includes a growing collection of graph algorithms and builders to simplify graph analytics tasks.
MlLib (Machine Learning)
MLlib stands for Machine Learning Library. Spark MLlib is used to perform machine learning in Apache Spark.
 Use Case: Earthquake Detection using Spark
Use Case: Earthquake Detection using Spark
Now that we have understood the core concepts of Spark, let us solve a real-life problem using Apache Spark. This will help give us the confidence to work on any Spark projects in the future.
Problem Statement: To design a Real Time Earthquake Detection Model to send life saving alerts, which should improve its machine learning to provide near real-time computation results.
Use Case – Requirements:
- Process data in real-time
- Handle input from multiple sources
- Easy to use system
- Bulk transmission of alerts
We will use Apache Spark which is the perfect tool for our requirements.
Use Case – Dataset:
 Figure: Use Case – Earthquake Dataset
Figure: Use Case – Earthquake Dataset
Before moving ahead, there is one concept we have to learn that we will be using in our Earthquake Detection System and it is called Receiver Operating Characteristic (ROC). An ROC curve is a graphical plot that illustrates the performance of a binary classifier system as its discrimination threshold is varied. We will use the dataset to obtain an ROC value using Machine Learning in Apache Spark.
Use Case – Flow Diagram:
The following illustration clearly explains all the steps involved in our Earthquake Detection System.
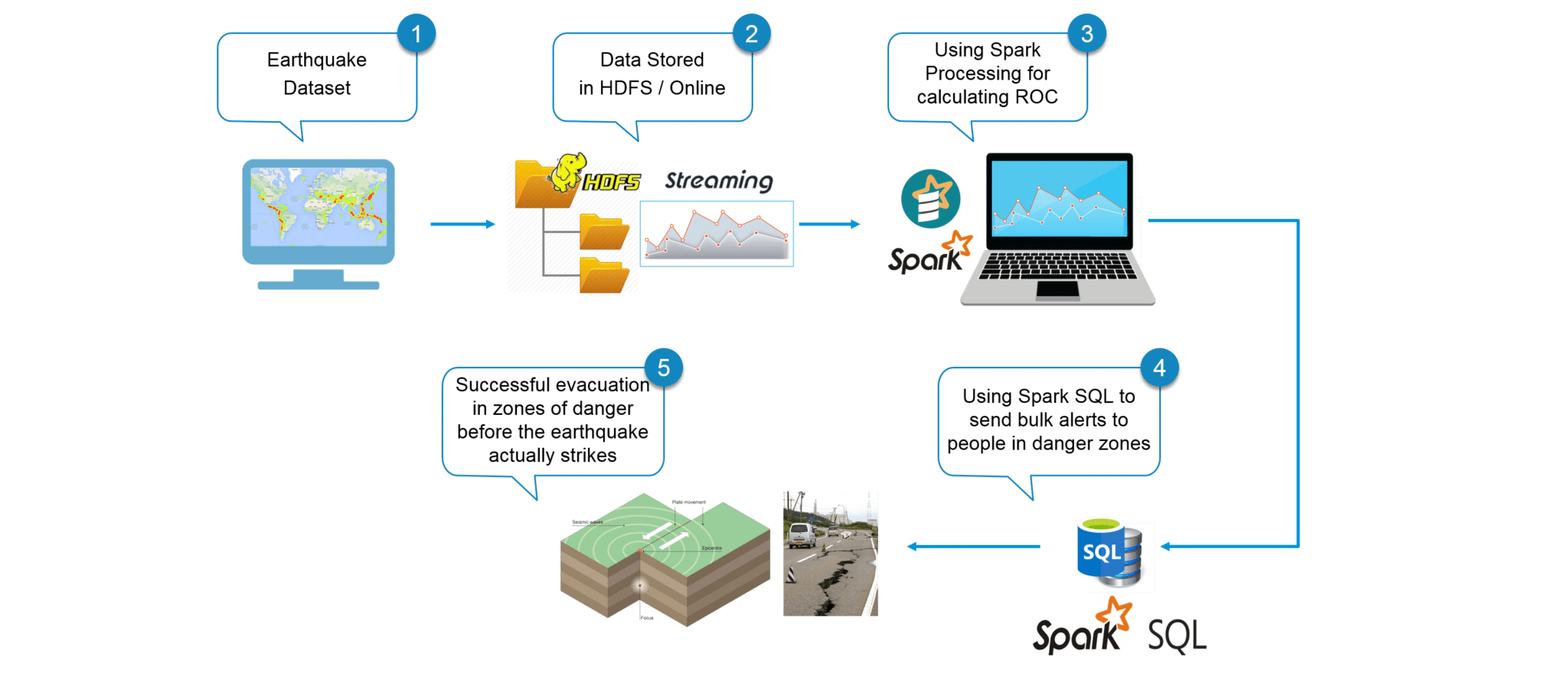 Figure: Use Case – Flow diagram of Earthquake Detection using Apache Spark
Figure: Use Case – Flow diagram of Earthquake Detection using Apache Spark
Use Case – Spark Implementation:
Moving ahead, now let us implement our project using Eclipse IDE for Spark.
Find the Pseudo Code below:
//Importing the necessary classes
import org.apache.spark._
...
//Creating an Object earthquake
object earthquake {
def main(args: Array[String]) {
//Creating a Spark Configuration and Spark Context
val sparkConf = new SparkConf().setAppName("earthquake").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
//Loading the Earthquake ROC Dataset file as a LibSVM file
val data = MLUtils.loadLibSVMFile(sc, *Path to the Earthquake File* )
//Training the data for Machine Learning
val splits = data.randomSplit( *Splitting 60% to 40%* , seed = 11L)
val training = splits(0).cache()
val test = splits(1)
//Creating a model of the trained data
val numIterations = 100
val model = *Creating SVM Model with SGD* ( *Training Data* , *Number of Iterations* )
//Using map transformation of model RDD
val scoreAndLabels = *Map the model to predict features*
//Using Binary Classification Metrics on scoreAndLabels
val metrics = * Use Binary Classification Metrics on scoreAndLabels *(scoreAndLabels)
val auROC = metrics. *Get the area under the ROC Curve*()
//Displaying the area under Receiver Operating Characteristic
println("Area under ROC = " + auROC)
}
}
From our Spark program, we obtain the ROC value to be 0.088137. We will be transforming this value to get the area under the ROC curve.
Use Case – Visualizing Results:
We will plot the ROC curve and compare it with the specific earthquake points. Where ever the earthquake points exceed the ROC curve, such points are treated as major earthquakes. As per our algorithm to calculate the Area under the ROC curve, we can assume that these major earthquakes are above 6.0 magnitude on the Richter scale.
 Figure: Earthquake ROC Curve
Figure: Earthquake ROC Curve
The above image shows the Earthquake line in orange. The area in blue is the ROC curve that we have obtained from our Spark program. Let us zoom into the curve to get a better picture.
 Figure: Visualizing Earthquake Points
Figure: Visualizing Earthquake Points
We have plotted the earthquake curve against the ROC curve. At points where the orange curve is above the blue region, we have predicted the earthquakes to be major, i.e., with magnitude greater than 6.0. Thus armed with this knowledge, we could use Spark SQL and query an existing Hive table to retrieve email addresses and send people personalized warning emails. Thus we have used technology once more to save human life from trouble and make everyone’s life better.
Now, this concludes the Apache Spark blog. I hope you enjoyed reading it and found it informative. By now, you must have acquired a sound understanding of what Apache Spark is. The hands-on examples will give you the required confidence to work on any future projects you encounter in Apache Spark. Practice is the key to mastering any subject and I hope this blog has created enough interest in you to explore learning further on Apache Spark.
Got a question for us? Please mention it in the comments section and we will get back to you at the earliest.
If you wish to learn Spark and build a career in domain of Spark to perform large-scale Data Processing using RDD, Spark Streaming, SparkSQL, MLlib, GraphX and Scala with Real Life use-cases, check out our interactive, live-online Apache Spark Certification Training here, that comes with 24*7 support to guide you throughout your learning period.







































hi , can anyone please help me to do mapreduce on live streaming data collected from arduino uno. i can do with the collected stored data but i want to process at live such that at dynamic
please go through the below code for word count program on streaming data in spark
package org.apache.spark.examples.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
/**
* Counts words cumulatively in UTF8 encoded, ‘n’ delimited text received from the network every
* second starting with initial value of word count.
* Usage: StatefulNetworkWordCount
* and describe the TCP server that Spark Streaming would connect to receive
* data.
*
* To run this on your local machine, you need to first run a Netcat server
* `$ nc -lk 9999`
* and then run the example
* `$ bin/run-example
* org.apache.spark.examples.streaming.StatefulNetworkWordCount localhost 9999`
*/
object StatefulNetworkWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: StatefulNetworkWordCount “)
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val sparkConf = new SparkConf().setAppName(“StatefulNetworkWordCount”)
// Create the context with a 1 second batch size
val ssc = new StreamingContext(sparkConf, Seconds(1))
ssc.checkpoint(“.”)
// Initial state RDD for mapWithState operation
val initialRDD = ssc.sparkContext.parallelize(List((“hello”, 1), (“world”, 1)))
// Create a ReceiverInputDStream on target ip:port and count the
// words in input stream of n delimited test (eg. generated by ‘nc’)
val lines = ssc.socketTextStream(args(0), args(1).toInt)
val words = lines.flatMap(_.split(” “))
val wordDstream = words.map(x => (x, 1))
// Update the cumulative count using mapWithState
// This will give a DStream made of state (which is the cumulative count of the words)
val mappingFunc = (word: String, one: Option[Int], state: State[Int]) => {
val sum = one.getOrElse(0) + state.getOption.getOrElse(0)
val output = (word, sum)
state.update(sum)
output
}
val stateDstream = wordDstream.mapWithState(
StateSpec.function(mappingFunc).initialState(initialRDD))
stateDstream.print()
ssc.start()
ssc.awaitTermination()
}
}
// scalastyle:on println
Hope this helps :)
Hi.. If anyone has full Hadoop & Apache Spark self learning videos and projects.. Pls msg me
Great Post
Thanks a lot it helped me a lot
I am also going to share it to my friends and over my social media.
Also,
Hackr.io is a great platform to find and share the best tutorials and they have a specific page for Apache spark
nice post,, this is really a very useful content about spark..
keep sharing
You have not discussed the Spark Architecture Diagram. Why? Please add the topic over here in this Spark blog.
Thanks & Regards
how can we show spark streaming data in and as web application?? Is there any tool/ Service for this please do suggest
Hey Pradeep, thanks for checking out our blog.
1.Spark is an analytics platform, not a web framework.
2.Yes, it’s true that you can bind Spark Streaming to a port, you cannot use logic in Spark to “serve” pages, which is the classic role of a Web Application.
3.Typically those who are using Spark for real time analytics have a separate web application that feeds it. In this case one might create a classic web stack, like Tomcat and MySQL or LAMP, and have a certain action in the user interface that passes data to a listening Spark Streaming application.
4.If you wanted your Spark Streaming to have real time effects on a web front end then it is certainly possible to create an architecture whereby you feed it data from the client, and then Spark submits the data to a service in your application or writes to your web app db at some point during its processing.
Hope this helps. Cheers!