







Java is an effective programming language in Software development and Scala is the dominant programming used in big-data development. The collaboration of both can yield a powerful combination. In this Spark Java tutorial, we shall work with Spark programs in Java environment. I have lined up the docket for our topic as below.
What is Spark-Java?


In simple terms, Spark-Java is a combined programming approach to Big-data problems. Spark is written in Java and Scala uses JVM to compile codes written in Scala. Spark supports many programming languages like Pig, Hive, Scala and many more. Scala is one of the most prominent programming languages ever built for Spark applications.
The Need for Spark-Java


Now we have a brief understanding of Spark Java, Let us now move on to our next stage where we shall learn about setting up the environment for Spark Java. I have lined up the procedure in the form of steps.
Setting up Spark-Java environment
Step 1:


Step 2:
- Install the latest version of WinUtils.exe


Step 3:
- Install the latest version of Apache Spark.

Step 4:
- Install the latest version of Apache Maven.

Step 5:
- Install the latest version of Eclipse Installer.


Step 6:
- Install the latest version of Scala IDE.

Step 7:
- Set home and path for the following:
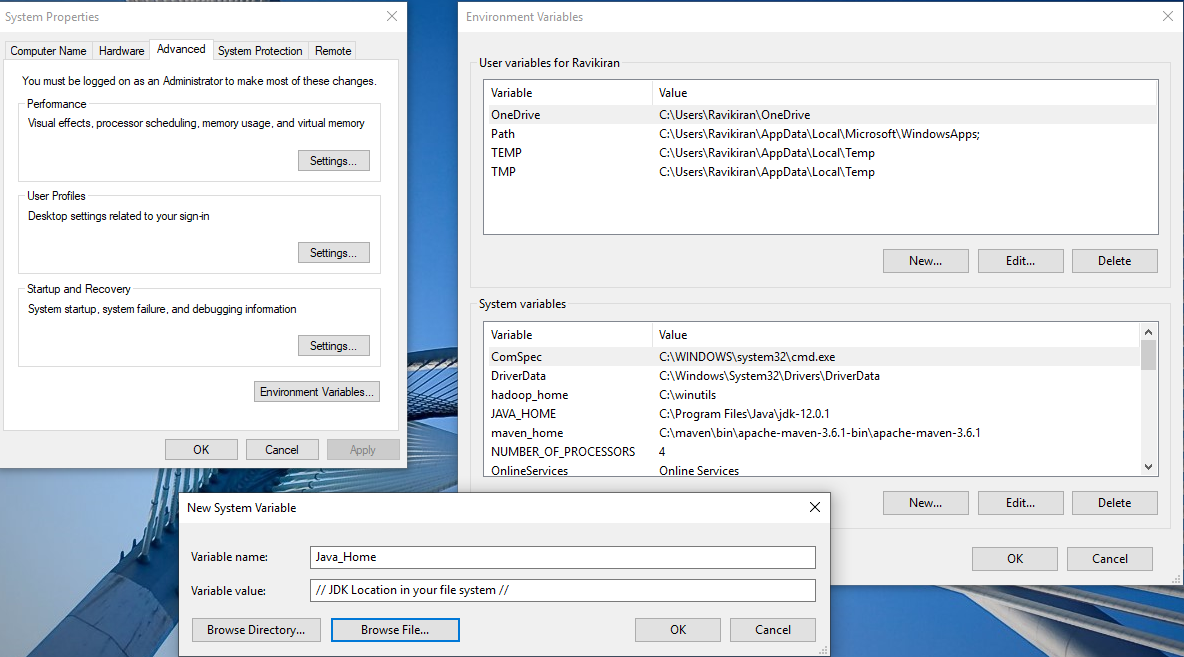
- Java
- Set a new Java_Home as shown below.

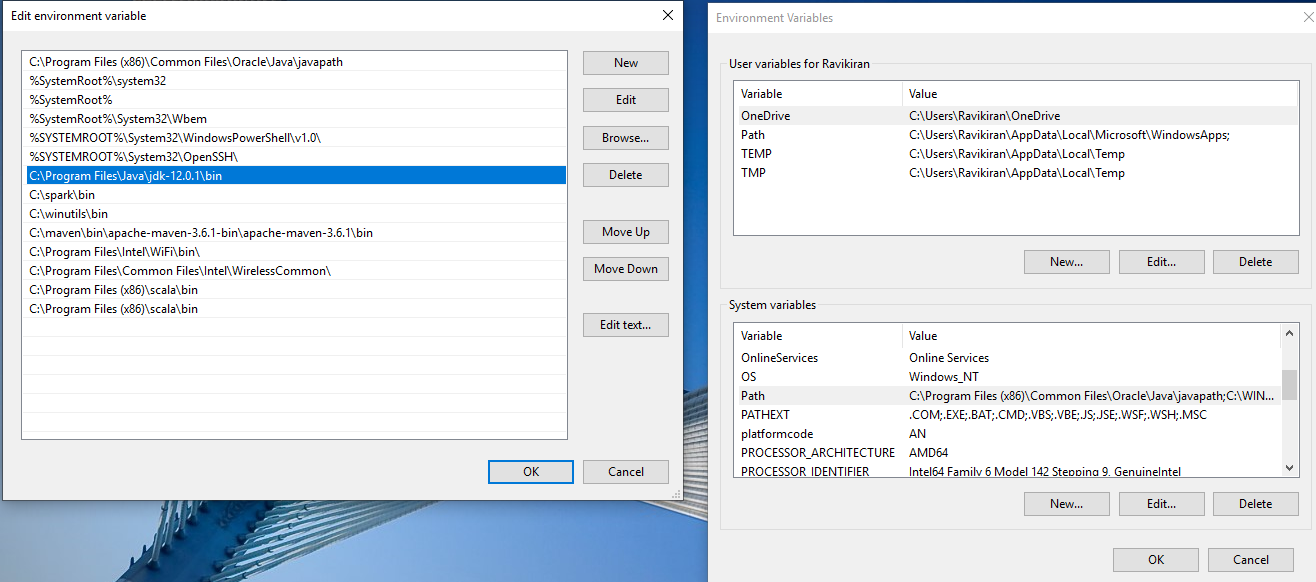
- Similarly, Set Path for Java Home by editing Path variables

- Hadoop
- Set a new Hadoop_Home as shown below.
- Hadoop
![]()

- Similarly, Set Path for Hadoop Home by editing Path variables
![]()

- Spark
- Set a new Spark_Home as shown below.
- Spark
![]()

- Similarly, Set Path for Spark Home by editing Path variables
![]()

- Maven
- Set a new Maven_Home as shown below.
- Maven
![]()

- Similarly, Set Path for Maven Home by editing Path variables
![]()

- Scala
- Set a new Scala_Home as shown below.
- Scala
![]()

- Similarly, Set Path for Scala Home by editing Path variables
![]()

Redefine your data analytics workflow and unleash the true potential of big data with Pyspark Course.
Now you are set with all the requirements to run Apache Spark on Java. Let us try an example of a Spark program in Java.
Examples in Spark-Java
Before we get started with actually executing a Spark example program in a Java environment, we need to achieve some prerequisites which I’ll mention below as steps for better understanding of the procedure.
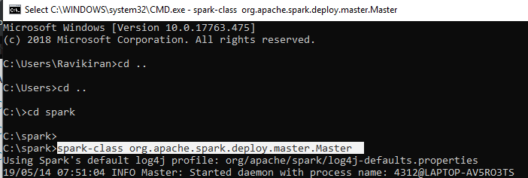
Step 1:
- Open the command prompt and start Spark in command prompt as a master.

Step 2:
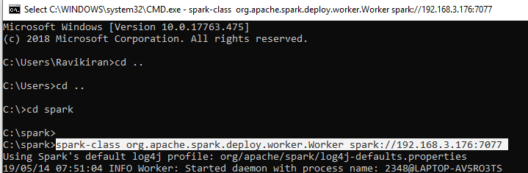
- Open a new command prompt and start Spark again in the command prompt and this time as a Worker along with the master’s IP Address.
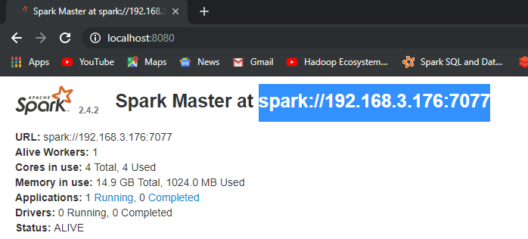

- The IP Address is available at Localhost:8080.

Step 3:
- Open a new command prompt and now you can start up the Spark shell along with the master’s IP Address.
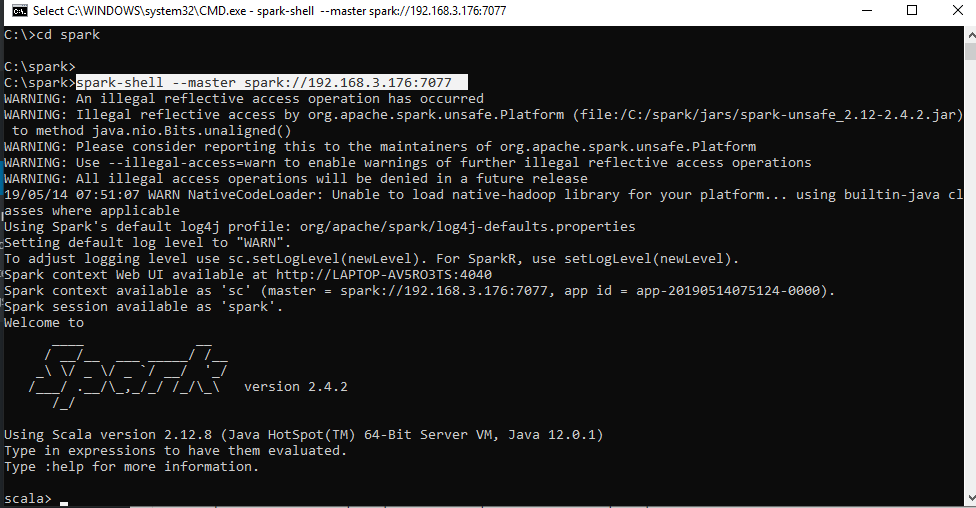

Step 4:
- Now you can open up the Eclipse Enterprise IDE and set up your workplace and start with your project.
Step 5:
- Set Scala nature on your Eclipse IDE and create a new maven project.
- First, we shall begin with POM.XML
- The following code is the pom.xml file
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>Edureka</groupId>
<artifactId>ScalaExample</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.2</version>
</dependency>
</dependencies>
</project>
Step 6:
- Begin with your Scala application.
- The following code is for the Scala application file.
package ScalaExample
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.SQLContext
import org.apache.spark.sql._
import org.apache.spark.sql.types.{StructType, StructField, StringType, IntegerType};
object EdurekaApp {
def main(args: Array[String]) {
val logFile = "C:/spark/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("EdurekaApp").setMaster("local[*]")
val sc = new SparkContext(conf)
val spark = SparkSession.builder.appName("Simple Application").getOrCreate()
val logData = spark.read.textFile(logFile).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println(s"Lines with a: $numAs, Lines with b: $numBs")
spark.stop()
}
}
Output:
Lines with a: 62, Lines with b: 31
Now that we have a brief understanding of Spark Java, Let us move into our use case on Students academic performance so as to learn Spark Java in a much better way.
Students Performance in the Examination: Use Case
Similar to our previous example Let us set up our prerequisites and then, we shall begin with our Use Case. Our use case will about Students performance in the examinations conducted on a few important subjects.


This is how our code looks like, now let us perform one by one operation upon our use case.
- The following code is the pom.xml file
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>ScalaExample3</groupId>
<artifactId>Edureka3</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>2.4.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.databricks/spark-csv -->
<dependency>
<groupId>com.databricks</groupId>
<artifactId>spark-csv_2.11</artifactId>
<version>1.5.0</version>
</dependency>
</dependencies>
</project>
- The following code is for the Scala application file.
package ScalaExample
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.SQLContext
import org.apache.spark.sql._
import org.apache.spark.sql.types.{StructType, StructField, StringType, IntegerType};
object EdurekaApp {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("EdurekaApp3").setMaster("local[*]")
val sc = new SparkContext(conf)</pre>
val sqlContext = new SQLContext(sc)
val spark = SparkSession.builder.appName("Simple Application").getOrCreate()
val customizedSchema = StructType(Array(StructField("gender", StringType, true),StructField("race", StringType, true),StructField("parentalLevelOfEducation", StringType, true),StructField("lunch", StringType, true),StructField("testPreparationCourse", StringType, true),StructField("mathScore", IntegerType, true),StructField("readingScore", IntegerType, true),StructField("writingScore", IntegerType, true)))
val pathToFile = "C:/Users/Ravikiran/Downloads/students-performance-in-exams/StudentsPerformance.csv"
val DF = sqlContext.read.format("com.databricks.spark.csv").option("header", "true").schema(customizedSchema).load(pathToFile)
print("We are starting from here...!")
DF.rdd.cache()
DF.rdd.foreach(println)
println(DF.printSchema)
DF.registerTempTable("Student")
sqlContext.sql("SELECT * FROM Student").show()
sqlContext.sql("SELECT gender, race, parentalLevelOfEducation, mathScore FROM Student WHERE mathScore > 75").show()
sqlContext.sql("SELECT race, count(race) FROM Student GROUP BY race").show()
sqlContext.sql("SELECT gender, race, parentalLevelOfEducation, mathScore, readingScore FROM Student").filter("readingScore>90").show()
sqlContext.sql("SELECT race, parentalLevelOfEducation FROM Student").distinct.show()
sqlContext.sql("SELECT gender, race, parentalLevelOfEducation, mathScore, readingScore FROM Student WHERE mathScore> 75 and readingScore>90").show()
sqlContext<span>("SELECT gender, race, parentalLevelOfEducation, mathScore, readingScore").dropDuplicates().show()</span>
println("We have finished here...!")
spark.stop()
}
}
The Output for the SparkSQL statements executed above are as follows:
- Printing out data using println function.
DF.rdd.foreach(println)
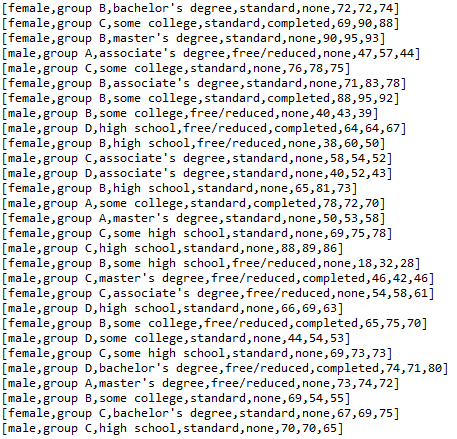

- Printing the schema that we designed for our data.
println(DF.printSchema)


- Printing our Dataframe using the select command.
sqlContext.sql("SELECT * FROM Student").show()
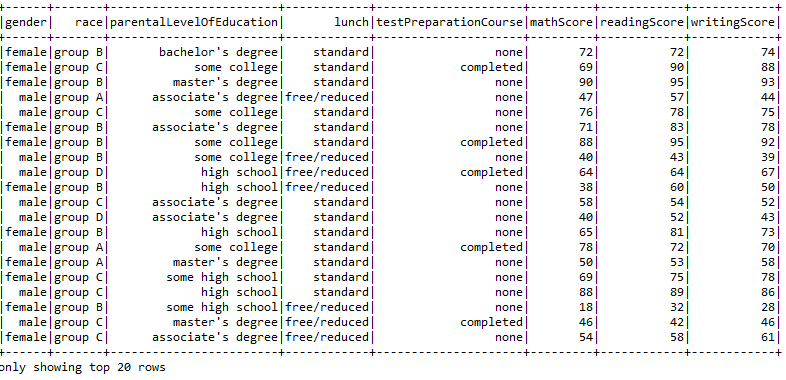

- Applying the function WHERE to print the data of the students who scored more than 75 in maths.
sqlContext.sql("SELECT gender, race, parentalLevelOfEducation, mathScore FROM Student WHERE mathScore > 75").show()

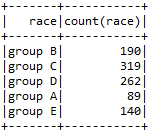
- Using Group By and Count operation to find out the number of students in each group.
sqlContext.sql("SELECT race, count(race) FROM Student GROUP BY race").show()

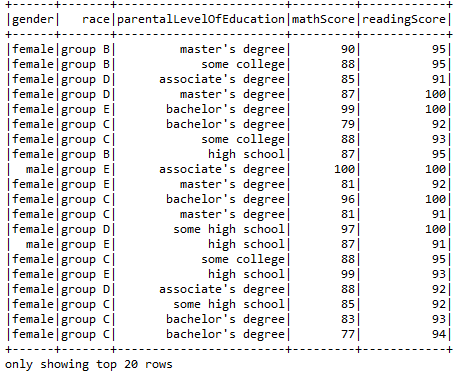
- Using filter operation to find out the students who are proven to be the best in reading.
sqlContext.sql("SELECT gender, race, parentalLevelOfEducation, mathScore, readingScore FROM Student").filter("readingScore>90").show()

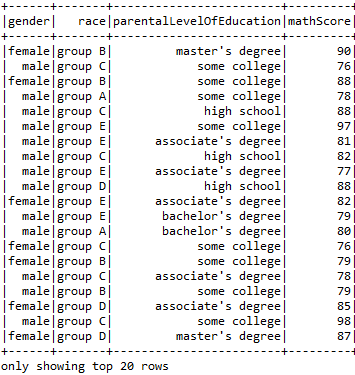
- Using Distinct function to find out the distinct values in our data.
sqlContext.sql("SELECT race, parentalLevelOfEducation FROM Student").distinct.show()


- Using And function to compare multiple entities.
sqlContext.sql("SELECT gender, race, parentalLevelOfEducation, mathScore, readingScore FROM Student WHERE mathScore> 75 and readingScore>90").show()
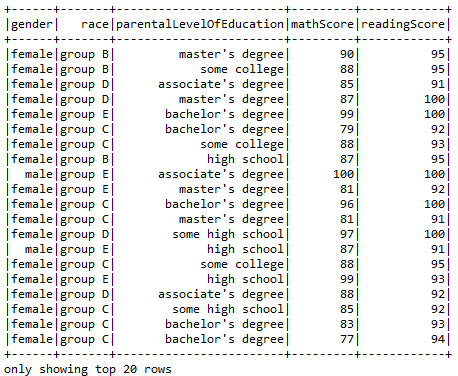

- Using DropDuplicates function to remove duplicate entries.
sqlContext("SELECT gender, race, parentalLevelOfEducation, mathScore, readingScore").dropDuplicates().show()
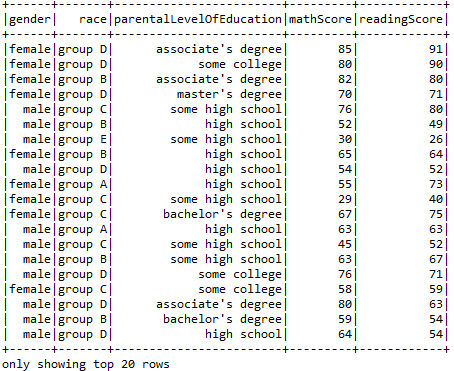

So, with this, we come to an end of this Spark Java Tutorial article. I hope we sparked a little light upon your knowledge about Spark, Java and Eclipse their features and the various types of operations that can be performed using them.
For details, You can even check out tools and systems used by Big Data experts and its concepts with the Masters in data engineering.
This article based on Apache Spark and Scala Certification Training is designed to prepare you for the Cloudera Hadoop and Spark Developer Certification Exam (CCA175). You will get in-depth knowledge on Apache Spark and the Spark Ecosystem, which includes Spark RDD, Spark SQL, Spark MLlib and Spark Streaming. You will get comprehensive knowledge on Scala Programming language, HDFS, Sqoop, Flume, Spark GraphX and Messaging System such as Kafka.Upskill your data engineering skills with our Microsoft fabric certification course