






As the need for storage increases daily and it is challenging to predict how much capacity you may require in the future, building and managing your repository becomes time-consuming and laborious. Amazon created the AWS S3 online storage solution with all these issues in mind. We will walk you through this service in this blog post for the AWS S3 lesson.

What is AWS S3?
Amazon Simple Storage Service (S3) is a storage for the internet. It is designed for large-capacity, low-cost storage provision across multiple geographical regions. Amazon S3 provides developers and IT teams with Secure, Durable and Highly Scalable object storage.
1. S3 is Secure because AWS provides:
- Encryption to the data that you store. It can happen in two ways:
- Client Side Encryption
- Server Side Encryption
- Multiple copies are maintained to enable regeneration of data in case of data corruption
- Versioning, wherein each edit is archived for a potential retrieval.
2. S3 is Durable because:
- It regularly verifies the integrity of data stored using checksums e.g. if S3 detects there is any corruption in data, it is immediately repaired with the help of replicated data.
- Even while storing or retrieving data, it checks incoming network traffic for any corrupted data packets.
3. S3 is Highly Scalable, since it automatically scales your storage according to your requirement and you only pay for the storage you use.
The next question which comes to our mind is,
What kind and how much of data one can store in AWS S3?
You can store virtually any kind of data, in any format, in S3 and when we talk about capacity, the volume and the number of objects that we can store in S3 are unlimited.
*An object is the fundamental entity in S3. It consists of data, key and metadata.
When we talk about data, it can be of two types-
- Data which is to be accessed frequently.
- Data which is accessed not that frequently.
Therefore, Amazon came up with 3 storage classes to provide its customers the best experience and at an affordable cost.
You can get a better understanding with the AWS Cloud Migration Certification.
Let’s understand the 3 storage classes with a “health-care” use case:
1.Amazon S3 Standard for frequent data access
 This is suitable for performance sensitive use cases where the latency should be kept low. e.g. in a hospital, frequently accessed data will be the data of admitted patients, which should be retrieved quickly.
This is suitable for performance sensitive use cases where the latency should be kept low. e.g. in a hospital, frequently accessed data will be the data of admitted patients, which should be retrieved quickly.
2. Amazon S3 Standard for infrequent data access
This is suitable for use cases where the data is long lived and less frequently accessed, i.e for data archival but still expects high performance. e.g. in the same hospital, people who have been discharged, their records/data will not be needed on a daily basis, but if they return with any complication, their discharge summary should be retrieved quickly.
3.Amazon Glacier Suitable for use cases where the data is to be archived, and high performance is not required, it has a lower cost than the other two services.e.g. in the hospital, patients’ test reports, prescriptions, MRI, X Ray, Scan docs etc. that are older than a year will not be needed in the daily run and even if it is required, lower latency is not needed.
Suitable for use cases where the data is to be archived, and high performance is not required, it has a lower cost than the other two services.e.g. in the hospital, patients’ test reports, prescriptions, MRI, X Ray, Scan docs etc. that are older than a year will not be needed in the daily run and even if it is required, lower latency is not needed.
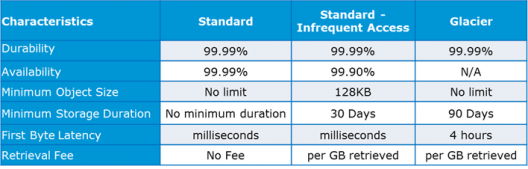
Specification Snapshot: Storage Classes
How is data organized in S3?
Data in S3 is organized in the form of buckets.
- A Bucket is a logical unit of storage in S3.
- A Bucket contains objects which contain the data and metadata.
Before adding any data in S3 the user has to create a bucket which will be used to store objects.
Where is your data stored geographically?
You can self-choose where or in which region your data should be stored. Making a decision for the region is important and therefore it should be planned well.
These are the 4 parameters to choose the optimal region –
- Pricing
- User/Customer Location
- Latency
- Service Availability
Let’s understand this through an example:
Suppose there is a company which has to launch these storage instances to host a website for the customers in the US and India.
To provide the best experience, the company has to choose a region, which best fits its requirements.

Now looking at the above parameters, we can clearly identify, that N Virginia will be the best region for this company because of the low latency and low price. Irrespective of your location, you can select any region which might suit your requirements, since you can access your S3 buckets from anywhere.
Talking about regions, let’s see about the possibility of having a backup in some other availability region or you may want to move your data to some other region. Thankfully, this feature has been recently added to the AWS S3 system and is pretty easy to use.
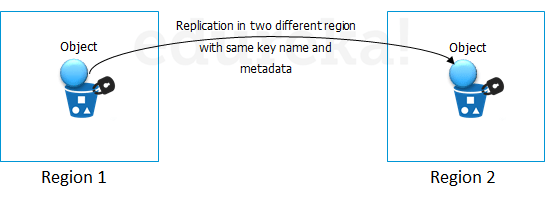
Cross-region Replication
As the name suggests, Cross-region Replication enables user to either replicate or transfer data to some other location without any hassle.
This obviously has a cost to it which has been discussed further in this article.
AWS S3 Tutorial
How is the data transferred?
Besides traditional transfer practices that is over the internet, AWS has 2 more ways to provide data transfer securely and at a faster rate:
- Transfer Acceleration
- Snowball
 Transfer Acceleration enables fast, easy and secure transfers over long distances by exploiting Amazon’s CloudFront edge technology.
Transfer Acceleration enables fast, easy and secure transfers over long distances by exploiting Amazon’s CloudFront edge technology.
CloudFront is a caching service by AWS, in which the data from client site gets transferred to the nearest edge location and from there the data is routed to your AWS S3 bucket over an optimised network path.
The Snowball is a way of transferring your data physically. In this Amazon sends an equipment to your premises, on which you can load the data. It has a kindle attached to it which has your shipping address when it is shipped from Amazon. When data transfer is complete on the Snowball,  kindle changes the shipping address back to the AWS headquarters where the Snowball has to be sent.
kindle changes the shipping address back to the AWS headquarters where the Snowball has to be sent.
The Snowball is ideal for customers who have large batches of data move. The average turnaround time for Snowball is 5-7 days, in the same time Transfer Acceleration can transfer up to 75 TB of data on a dedicated 1Gbps line. So depending on the use case, a customer can decide.
Obviously, there will be some cost around it, let’s look at the overall costing around S3.
Pricing
“Isn’t anything free on AWS?”
Yes! As a part of the AWS Free Usage Tier, you can get started with AWS S3 for free. Upon sign up, new AWS customers receive 5 GB of Amazon S3 standard storage, 20,000 Get-Requests, 2,000 Put-Requests, and 15GB of data transfer-out each month for one year.
Over this limit, there is a cost attached, let’s understand how amazon charges you:
How is S3 billed in AWS S3?
Though having so many features, AWS S3 is affordable and flexible in its costing. It works on Pay Per Use, meaning, you only pay what you use. The table below is an example for pricing of S3 for a specific region:
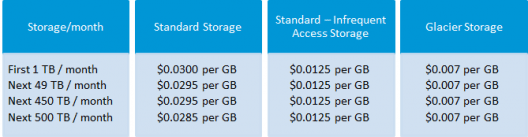
Source: aws.amazon.com for North Virginia region
Cross Region Replication is billed in the following way:
If you replicate 1,000 1 GB objects (1,000 GB) between regions you will incur a request charge of $0.005 (1,000 requests x $0.005 per 1,000 requests) for replicating 1,000 objects and a charge of $20 ($0.020 per GB transferred x 1,000 GB) for inter-region data transfer. After replication, the 1,000 GB will incur storage charges based on the destination region.
Snowball, there are 2 variants:
- Snowball 50 TB : 200$
- Snowball 80 TB: 250$
This is the fixed service fee that they charge.
Apart from this there are on-site, charges which are exclusive of shipping days, the shipping days are free.
The first 10 on-site days are also free, meaning when the Snowball reaches your premises from then, till the day it is shipped back, they are the on-site days. The day it arrives, and the day it is shipped gets counted as shipping days, therefore are free.
Transfer Acceleration pricing is shown in the following table:

AWS S3 Use case: 1
Industry “Media”
Let’s understand it through a real time use case to assimilate all what we have learnt so far: IMDb Internet Movie Database is a famous online database of information related to films, television programs and video games.
Let’s see how they exploit the AWS services:
- To get the lowest possible latency, all possible results for a search are pre-calculated with a document for every combination of letters in search. Each document is pushed to Amazon Simple Storage Service (S3) and thereby to Amazon CloudFront, putting the documents physically close to the users. The theoretical number of possible searches to calculate is mind-boggling—a 20-character search has 23 x 1030 combinations
- But in practice, using IMDb’s authority on movie and celebrity data can reduce the search space to about 150,000 documents, which Amazon S3 and Amazon CloudFront can distribute in just a few hours.
Related Learning: AWS Interview Questions and Answers about Amazon S3
AWS S3 Use case: 2
Project Statement – Hosting a Static Website on Amazon S3
Let’s first understand: What is a static website?
In short, it’s a website comprised of only HTML, CSS, and/or JavaScript. That means server-side scripts aren’t supported, so you’ll need to look elsewhere if you want to host a Rails or PHP app.
For simpler purposes, welcome to the wonderful world of hosting websites on AWS S3!
Step 1: Create a bucket
To create a bucket, navigate to S3 in the AWS Management Console and hit Create Bucket. You’ll be prompted to enter a name and a region.
If you plan on using your own domain/sub-domain, use that for your bucket name. For the region, pick the one closest to you and hit Create. With any luck, you’ll see your new bucket appear in the console.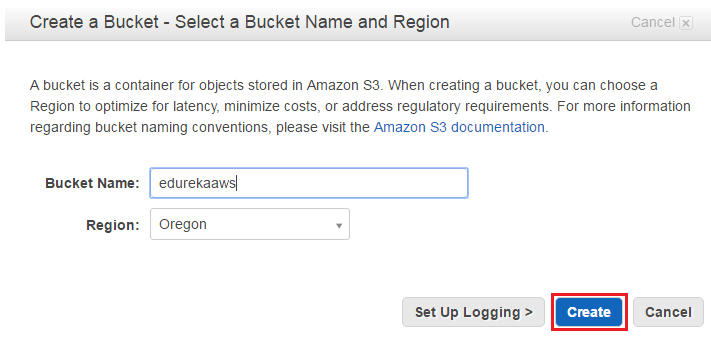
Step 2: Verify the Created Bucket

Step3: Enable Website Hosting
The only thing now left to do is, to enable Static Website Hosting. Just select it from the properties panel on the right.

Step 4: Create a Html File
Make sure you set the Index Document to index.html. You can also set an error page if you want. When you’re done, hit Save.
One nice thing about the AWS Management Console is that you can upload files to your bucket right from your browser. Let’s start by creating one called index.html. This will be the contents of the home page:
<!doctype html>
<html>
<head>
<title>
Hello, S3!
</title>
<meta name="description" content="My first S3 website">
<meta charset="utf-8">
</head>
<body>
<h2>My first S3 website</h2>
<p>I can't believe it was that easy!</p>
</body>
</html>
Step 5: Upload the File in a Bucket
To upload the file, select your new bucket and hit Start Upload button.
Once you’ve uploaded index.html, it will appear in your bucket. However, you won’t be able to see it in your browser yet because everything in AWS S3 is private by default.
Step 6: Make the Html File Public
i) To make index.html file public, right-click on index.html and select Make Public. (Remember to do this for any other files you upload to your website!)

Now that your homepage is visible to the world, it’s time to test everything out!
ii) Now, select index.html in the console and go to the Properties tab.
Step 7: Final Step to Verify the Result
Clicking the link will take you to your new homepage.

Congratulations! You have just hosted an html website in AWS using S3.
Key-value Store in AWS S3
S3 is based on objects. Among objects are the following:
Key: It is just the object’s name. As an illustration, spreadsheet.xlsx, hello.txt, etc. The key can be used to get the item back.
Value: It’s only the information made up of a series of bytes. Actually, it is a piece of data in the file.
Version ID: The object is uniquely identified by its version ID. When an object is added to an S3 bucket, S3 generates this string.
Data regarding the data you are storing is known as metadata. a collection of name-value pairs where you can store details about an object. The objects in the Amazon S3 bucket can have metadata added to them.
Subresources: Information relevant to an object is stored via the subresource technique.
Here’s a short AWS S3 tutorial Video that explains: Traditional Storage Tiers, Disadvantages of Traditional Storage over Cloud, AWS storage options: EBS, S3, Glacier, AWS Connecting Storage: Snowball & Storage Gateway, AWS Command Line Interface (CLI), Demo etc. The AWS S3 tutorial is very important service for those who want to become AWS Certified Solutions Architect.
AWS S3 Tutorial For Beginners
I hope you have enjoyed the deep dive into this AWS S3 tutorial. It is one of the most sought-after skillsets that recruiters look for in an AWS Solution Architect Professional. Here’s a collection of AWS Architect interview questions to help you prepare for your next AWS job interview.The AWS Certified Solutions Architect Associate Training will be your best option if you want to grasp AWS better.
Getting Azure-certified enhances your job prospects in cloud computing. A Microsoft Azure cloud online certification training program prepares you with real-world skills to ace the exam and excel in your career.
Got a question for us? Please mention it in the comments section of this AWS S3 Tutorial and we will get back to you.
































Recent poll shows that approximately 75% men and women are involved into web-based jobs. Internet world is simply becoming bigger and better and giving plenty of opportunities. Working at home on line tasks are becoming poplar and improving people’s lives. Exactly why it really is extremely popular? Because it lets you do the job from anywhere and any time. One gets more time to dedicate with your family members and can plan out journeys for vacations. Individuals are earning wonderful income of $45000 every week by utilizing the effective and intelligent methods.