
Data Science with Python Certification Course
- 131k Enrolled Learners
- Weekend
- Live Class
(49300)





 Copy Link!
Copy Link!In this OpenCV Python Tutorial blog, we will be covering various aspects of Computer Vision using OpenCV in Python. OpenCV has been a vital part in the development of software for a long time. Learning OpenCV is a good asset to the developer to improve aspects of coding and also helps in building a software development career! Get yourself enrolled in Edureka’s Python course to learn really cool applications of Python.
We will be checking out the following concepts:
This video explains all the basics of OpenCV.
To simplify the answer to this – Let us consider a scenario.
We all use Facebook, correct? Let us say you and your friends went on a vacation and you clicked a lot of pictures and you want to upload them on Facebook and you did. But now, wouldn’t it take so much time just to find your friends faces and tag them in each and every picture? Well, Facebook is intelligent enough to actually tag people for you.
So, how do you think the auto tag feature works? In simple terms, it works on computer vision.
Computer Vision is an interdisciplinary field that deals with how computers can be made to gain a high-level understanding from digital images or videos.
The idea here is to automate tasks that the human visual systems can do. So, a computer should be able to recognize objects such as that of a face of a human being or a lamppost or even a statue.
Consider the below image:
 We can figure out that it is an image of the New York Skyline. But, can a computer find this out all on its own? The answer is no!
We can figure out that it is an image of the New York Skyline. But, can a computer find this out all on its own? The answer is no!
The computer reads any image as a range of values between 0 and 255.
For any color image, there are 3 primary channels – Red, green and blue. How it works is pretty simple.
A matrix is formed for every primary color and later these matrices combine to provide a Pixel value for the individual R, G, B colors.
Each element of the matrices provide data pertaining to the intensity of brightness of the pixel.
Consider the following image:
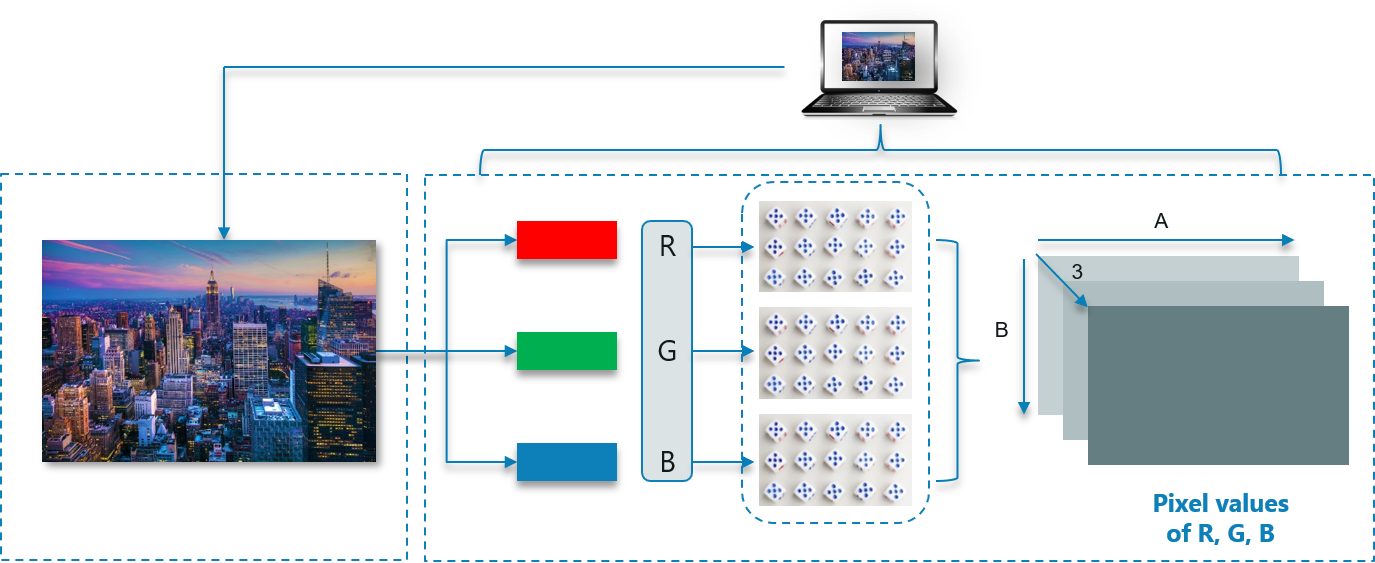
As shown, the size of the image here can be calculated as B x A x 3.
Note: For a black-white image, there is only one single channel.
Next up on this OpenCV Python Tutorial blog, let us look at what OpenCV actually is.
OpenCV is a Python library which is designed to solve computer vision problems. OpenCV was originally developed in 1999 by Intel but later it was supported by Willow Garage.
OpenCV supports a wide variety of programming languages such as C++, Python, Java etc. Support for multiple platforms including Windows, Linux, and MacOS.
OpenCV Python is nothing but a wrapper class for the original C++ library to be used with Python. Using this, all of the OpenCV array structures gets converted to/from NumPy arrays.
This makes it easier to integrate it with other libraries which use NumPy. For example, libraries such as SciPy and Matplotlib.
Next up on this OpenCV Python Tutorial blog, let us look at some of the basic operations that we can perform with OpenCV.
Let us look at various concepts ranging from loading images to resizing them and so on.
Import cv2 # colored Image Img = cv2.imread (“Penguins.jpg”,1) # Black and White (gray scale) Img_1 = cv2.imread (“Penguins.jpg”,0)
As seen in the above piece of code, the first requirement is to import the OpenCV module.
Later we can read the image using imread module. The 1 in the parameters denotes that it is a color image. If the parameter was 0 instead of 1, it would mean that the image being imported is a black and white image. The name of the image here is ‘Penguins’. Pretty straightforward, right?
We can make use of the shape sub-function to print out the shape of the image. Check out the below image:
Import cv2 # Black and White (gray scale) Img = cv2.imread (“Penguins.jpg”,0) Print(img.shape)
By shape of the image, we mean the shape of the NumPy array. As you see from executing the code, the matrix consists of 768 rows and 1024 columns.
Displaying an image using OpenCV is pretty simple and straightforward. Consider the below image:
import cv2 # Black and White (gray scale) Img = cv2.imread (“Penguins.jpg”,0) cv2.imshow(“Penguins”, img) cv2.waitKey(0) # cv2.waitKey(2000) cv2.destroyAllWindows()
As you can see, we first import the image using imread. We require a window output to display the images, right?
We use the imshow function to display the image by opening a window. There are 2 parameters to the imshow function which is the name of the window and the image object to be displayed.
Later, we wait for a user event. waitKey makes the window static until the user presses a key. The parameter passed to it is the time in milliseconds.
And lastly, we use destroyAllWindows to close the window based on the waitForKey parameter.
Similarly, resizing an image is very easy. Here’s another code snippet:
import cv2 # Black and White (gray scale) img = cv2.imread (“Penguins.jpg”,0) resized_image = cv2.resize(img, (650,500)) cv2.imshow(“Penguins”, resized_image) cv2.waitKey(0) cv2.destroyAllWindows()
Here, resize function is used to resize an image to the desired shape. The parameter here is the shape of the new resized image.
Later, do note that the image object changes from img to resized_image, because of the image object changes now.
Rest of the code is pretty simple to the previous one, correct?
I am sure you guys are curious to look at the penguins, right? This is the image we were looking to output all this while!

There is another way to pass the parameters to the resize function. Check out the following representation:
Resized_image = cv2.resize(img, int(img.shape[1]/2), int(img.shape[0]/2)))
Here, we get the new image shape to be half of that of the original image.
Next up on this OpenCV Python Tutorial blog, let us look at how we perform face detection using OpenCV.
This seems complex at first but it is very easy. Let me walk you through the entire process and you will feel the same.
Step 1: Considering our prerequisites, we will require an image, to begin with. Later we need to create a cascade classifier which will eventually give us the features of the face.
Step 2: This step involves making use of OpenCV which will read the image and the features file. So at this point, there are NumPy arrays at the primary data points.
All we need to do is to search for the row and column values of the face NumPy ndarray. This is the array with the face rectangle coordinates.
Step 3: This final step involves displaying the image with the rectangular face box.
Check out the following image, here I have summarized the 3 steps in the form of an image for easier readability:
Pretty straightforward, correct?
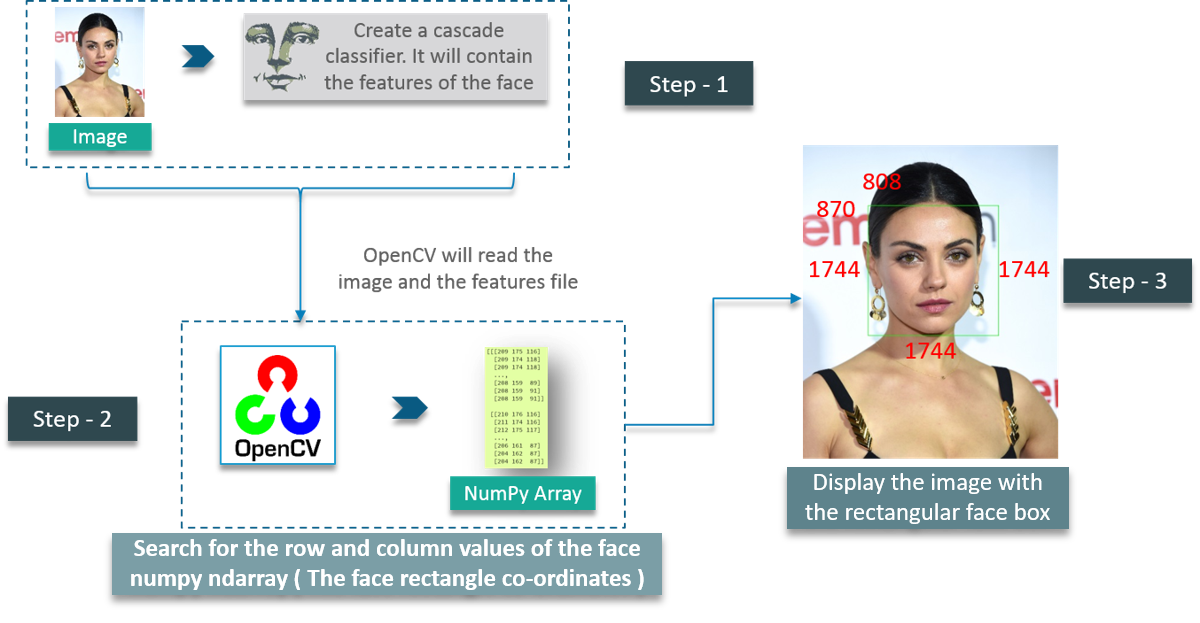
First, we create a CascadeClassifier object to extract the features of the face as explained earlier. The path to the XML file which contains the face features is the parameter here.
The next step would be to read an image with a face on it and convert it into a black and white image using COLOR_BGR2GREY. Followed by this, we search for the coordinates for the image. This is done using detectMultiScale.
What coordinates, you ask? It’s the coordinates for the face rectangle. The scaleFactor is used to decrease the shape value by 5% until the face is found. So, on the whole – Smaller the value, greater is the accuracy.
Finally, the face is printed on the window.
This logic is very simple – As simple as making use of a for loop statement. Check out the following image
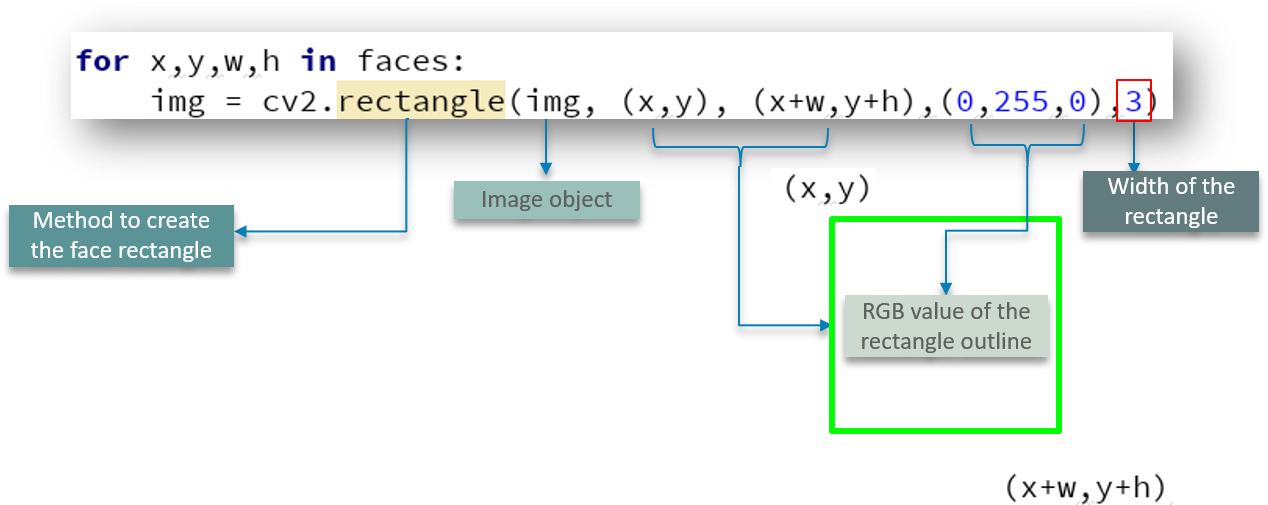 We define the method to create a rectangle using cv2.rectangle by passing parameters such as the image object, RGB values of the box outline and the width of the rectangle.
We define the method to create a rectangle using cv2.rectangle by passing parameters such as the image object, RGB values of the box outline and the width of the rectangle.
Let us check out the entire code for face detection:
import cv2
# Create a CascadeClassifier Object
face_cascade = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")
# Reading the image as it is
img = cv2.imread("photo.jpg")
# Reading the image as gray scale image
gray_img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# Search the co-ordintes of the image
faces = face_cascade.detectMultiScale(gray_img, scaleFactor = 1.05,
minNeighbors=5)
for x,y,w,h in faces:
img = cv2.rectangle(img, (x,y), (x+w,y+h),(0,255,0),3)
resized = cv2.resize(img, (int(img.shape[1]/7),int(img.shape[0]/7)))
cv2.imshow("Gray", resized)
cv2.waitKey(0)
cv2.destroyAllWindows()
Next up on this OpenCV Python Tutorial blog, let us look at how to use OpenCV to capture video with the computer webcam.
Capturing videos using OpenCV is pretty simple as well. the following loop will give you a better idea. Check it out:
The images are read one-by-one and hence videos are produced due to fast processing of frames which makes the individual images move.
Check out the following image:
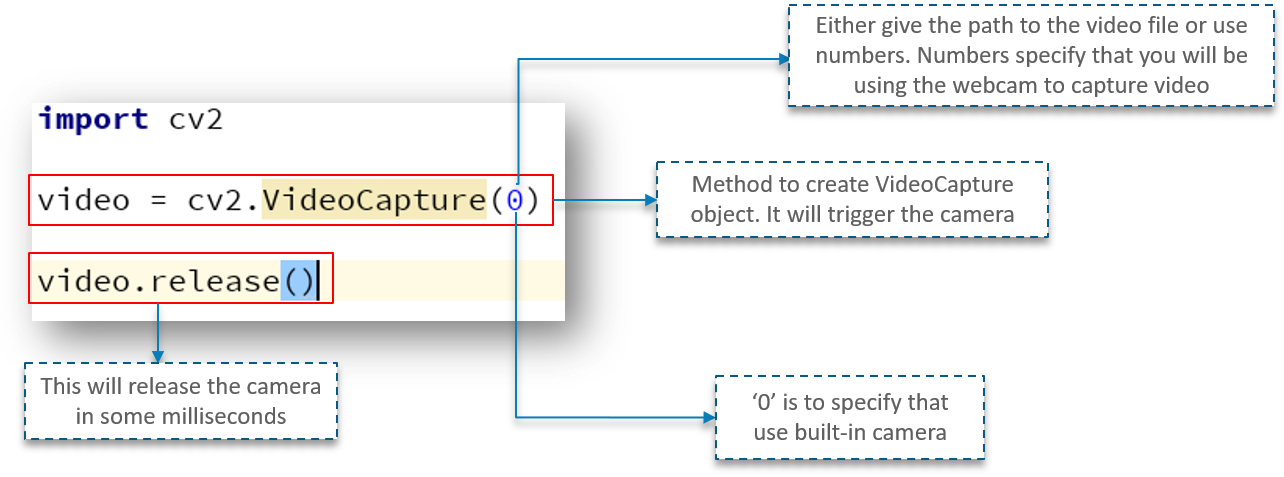
First, we import the OpenCV library as usual. Next, we have a method called VideoCapture which is used to create the VideoCapture object. This method is used to trigger the camera on the user’s machine. The parameter to this function denotes if the program should make use of the built-in camera or an add-on camera. ‘0’ denotes the built-in camera in this case.
And lastly, the release method is used to release the camera in a few milliseconds.
When you go ahead and type in and try to execute the above code, you will notice that the camera light switches on for a split second and turns off later. Why does this happen?
This happens because there is no time delay to keep the camera functional.
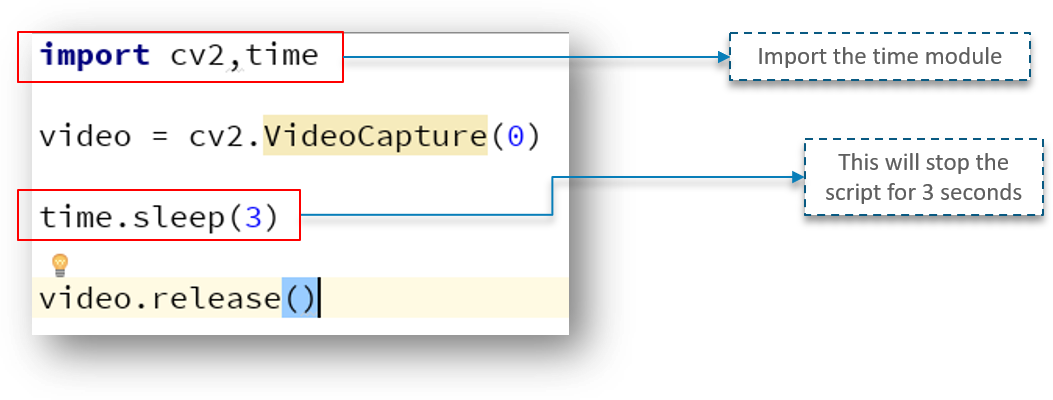
Looking at the above code, we have a new line called time.sleep(3) – This makes the script to stop for 3 seconds. Do note that the parameter passed is the time in seconds. So, when the code is executed, the webcam will be turned on for 3 seconds.
Adding a window to show the video output is pretty simple and can be compared to the same methods used for images. However, there is a slight change. Check out the following code:
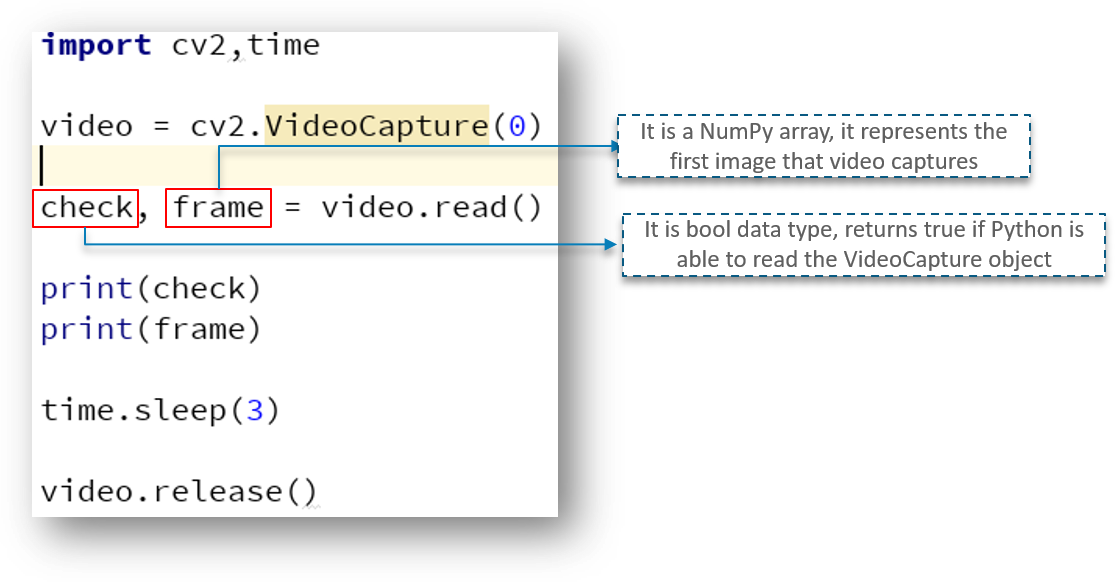
I am pretty sure you can make the most sense from the above code apart from one or two lines.
Here, we have defined a NumPy array which we use to represent the first image that the video captures – This is stored in the frame array.
We also have check – This is a boolean datatype which returns True if Python is able to access and read the VideoCapture object.
Check out the output below:
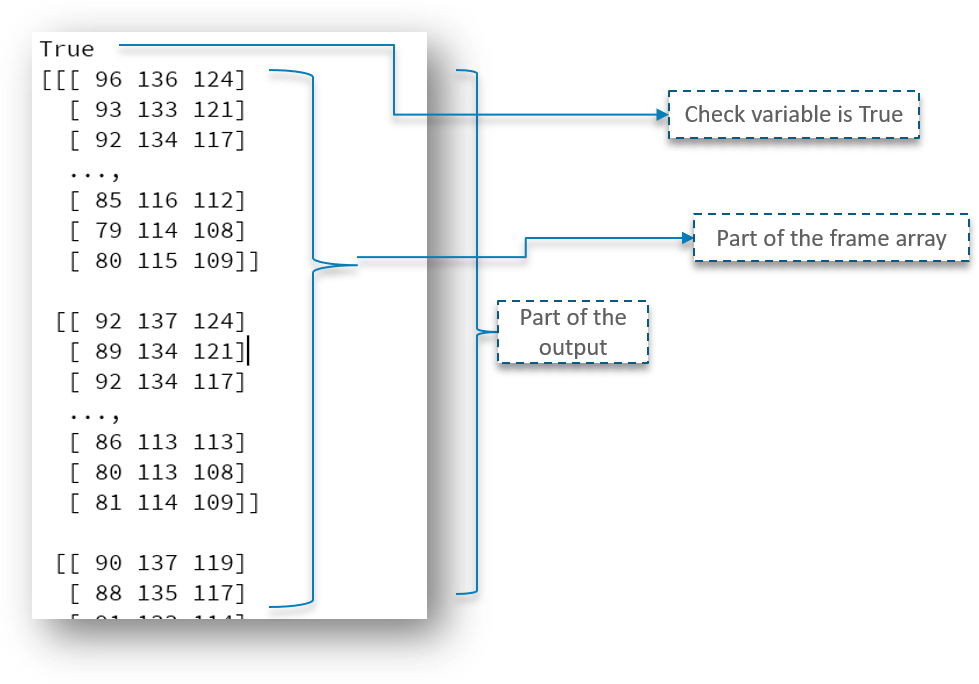
As you can check out, we got the output as True and the part of the frame array is printed.
But we need to read the first frame/image of the video to begin, correct?
To do exactly that, we need to first create a frame object which will read the images of the VideoCapture object.
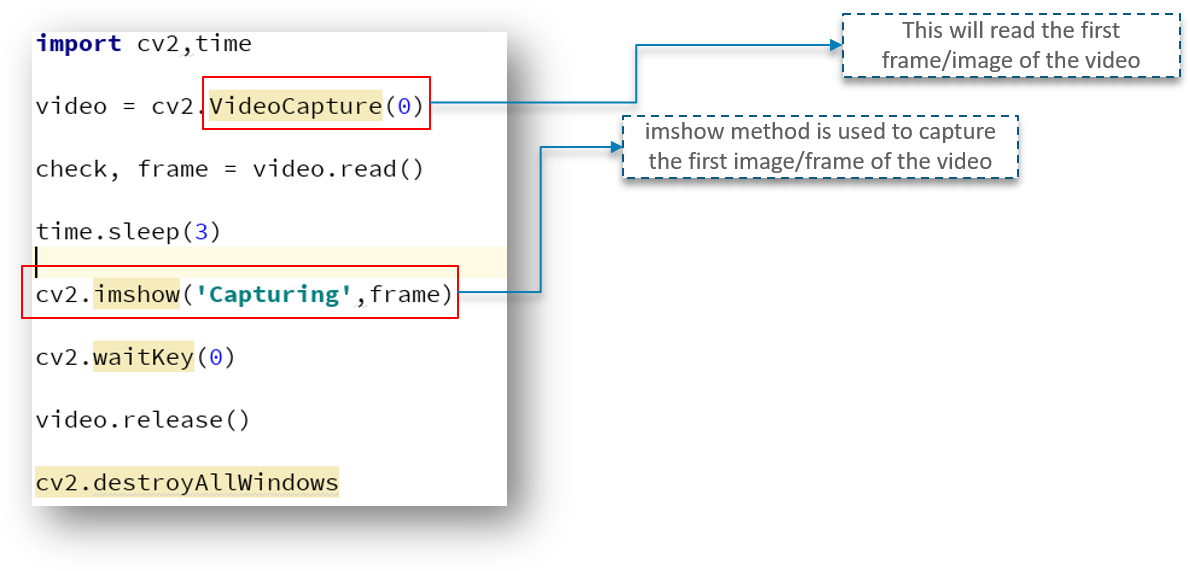
As seen above, the imshow method is used to capture the first frame of the video.
All this while, we have tried to capture the first image/frame of the video but directly capturing the video.
So how do we go about capturing the video instead of the first image in OpenCV?
In order to capture the video, we will be using the while loop. While condition will be such that, until unless ‘check’ is True. If it is, then Python will display the frames.
Here’s the code snippet image:
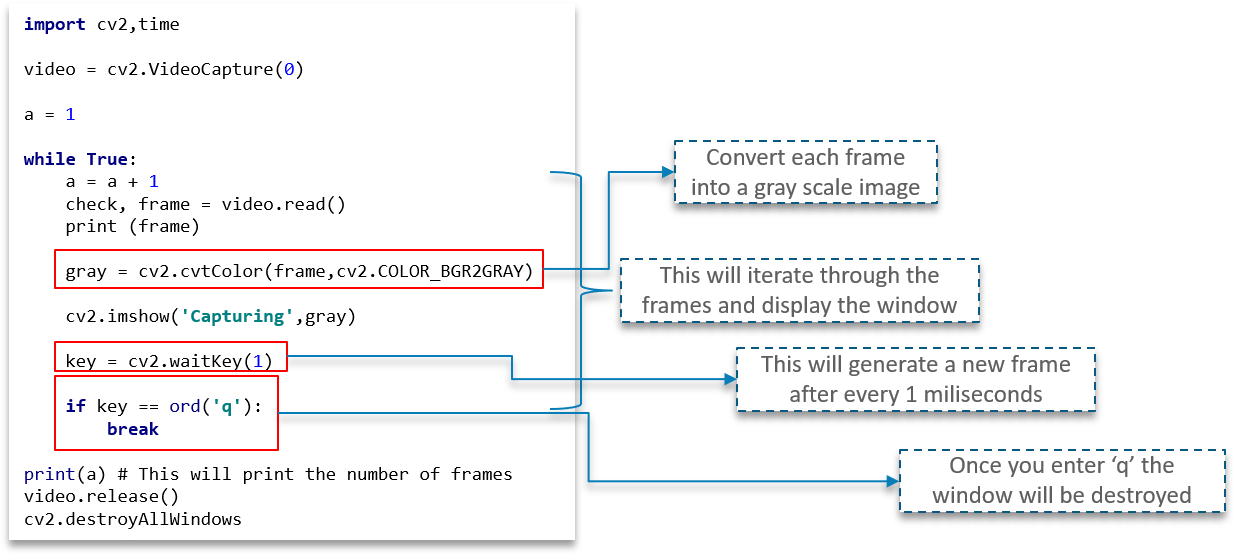
We make use of the cvtColor function to convert each frame into a grey-scale image as explained earlier.
waitKey(1) will make sure to generate a new frame after every millisecond of a gap.
It is important here that you note that the while loop is completely in play to help iterate through the frames and eventually display the video.
There is a user event trigger here as well. Once the ‘q’ key is pressed by the user, the program window closes.
OpenCV is pretty easy to grasp, right? I personally love how good the readability is and how quickly a beginner can get started working with OpenCV.
Next up on this OpenCV Python Tutorial blog, let us look at how to use a very interesting motion detector use case using OpenCV.
You have been approached by a company that is studying human behavior. Your task is to give them a webcam, that can detect the motion or any movement in front of it. This should return a graph, this graph should contain how long the human/object was in front of the camera.
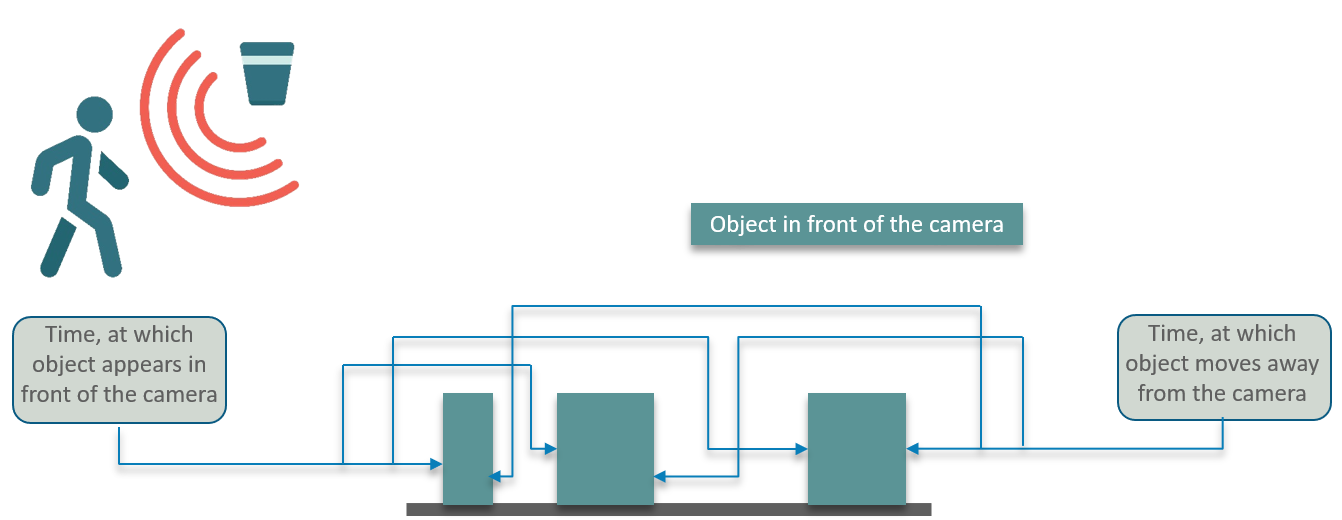
So, now that we have defined our problem statement, we need to build a solution logic to approach the problem in a structured way.
Consider the below diagram:
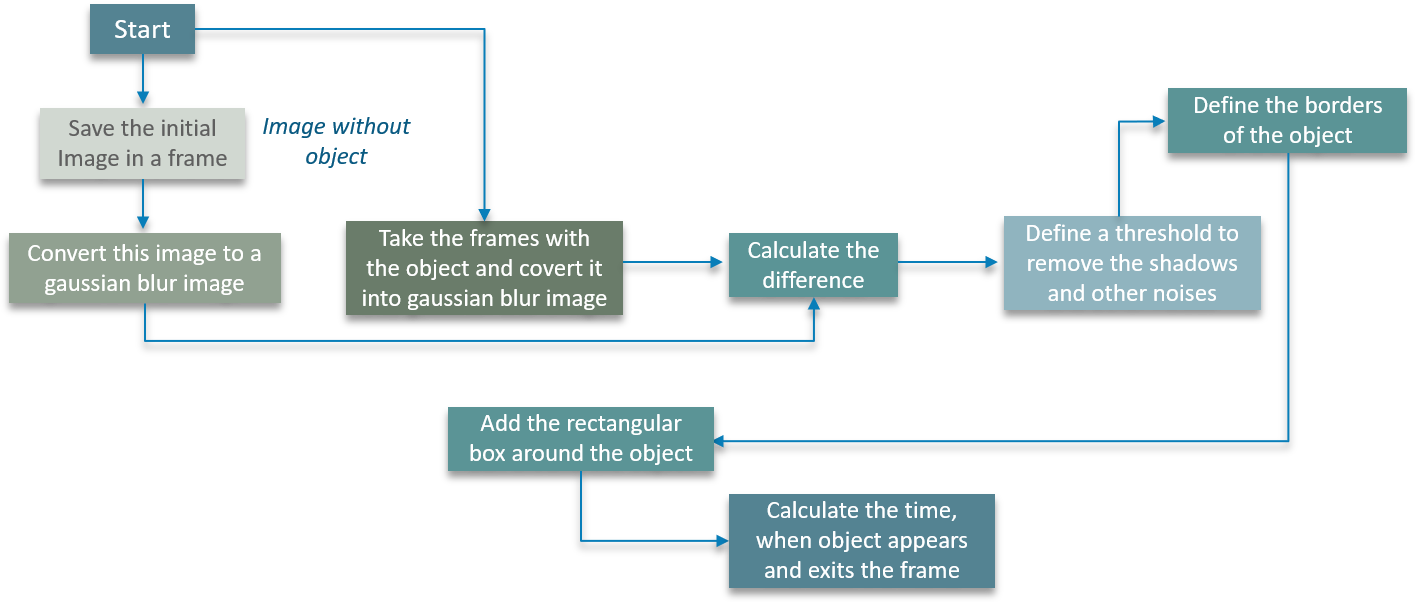
Initially, we save the image in a particular frame.
The next step involves converting the image to a Gaussian blur image. This is done so as to ensure we calculate a palpable difference between the blurred image and the actual image.
At this point, the image is still not an object. We define a threshold to remove blemishes such as shadows and other noises in the image.
Borders for the object are defined later and we add a rectangular box around the object as we discussed earlier on the blog.
Lastly, we calculate the time at which the object appears and exits the frame.
Pretty easy, right?
Here’s the code snippet:
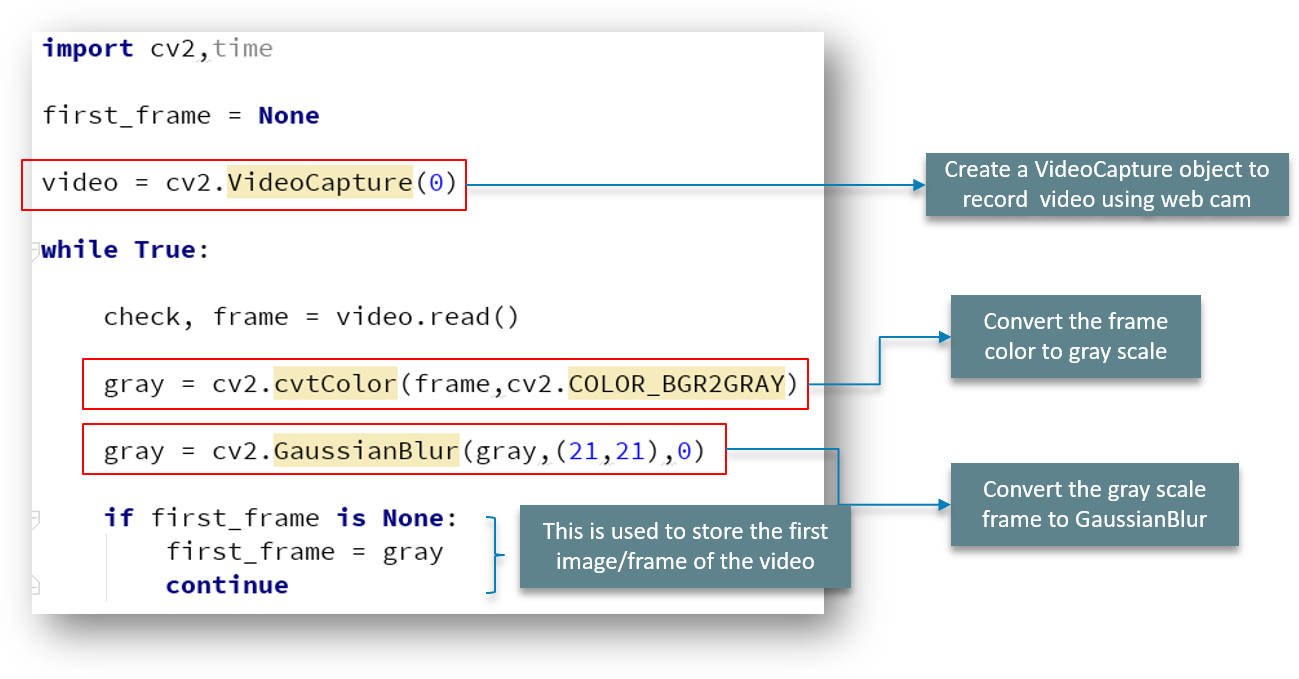
The same principle follows through here as well. We first import the package and create the VideoCapture object to ensure we capture video using the webcam.
The while loop iterates through the individual frames of the video. We convert the color frame to a grey-scale image and later we convert this grey-scale image to Gaussian blur.
We need to store the first image/frame of the video, correct? We make use of the if statement for this purpose alone.
Now, let us dive into a little more code:
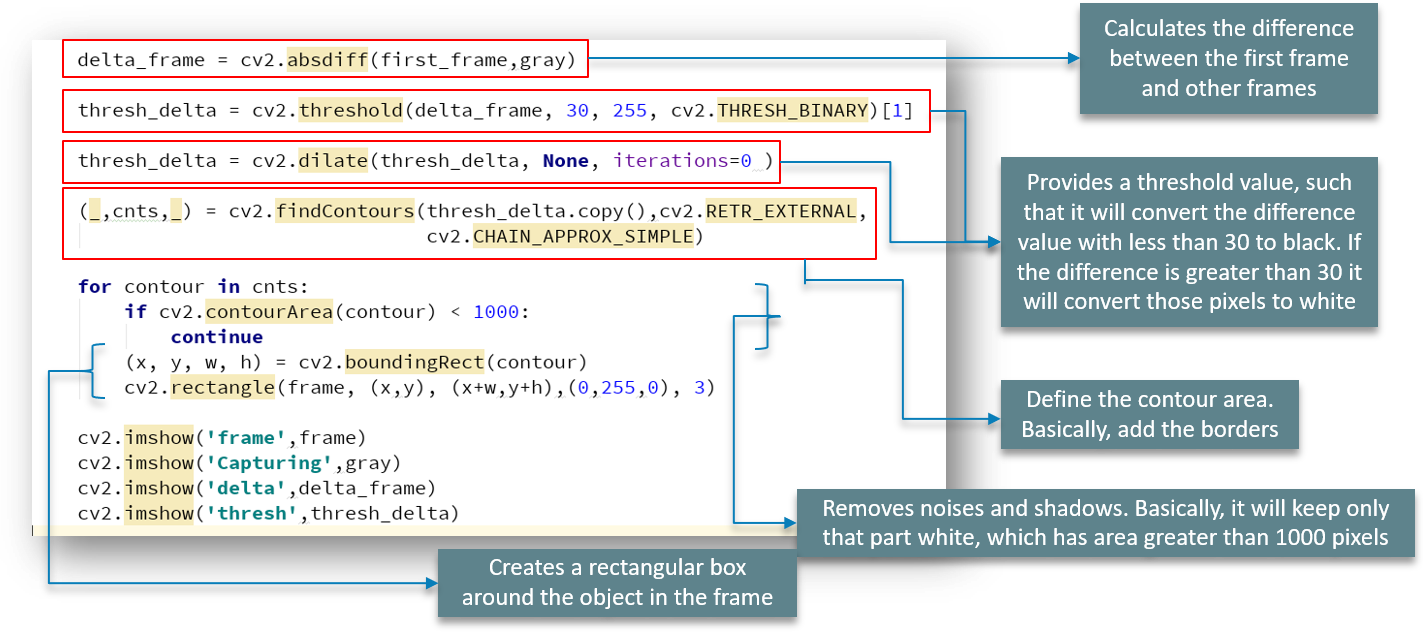
We make use of the absdiff function to calculate the difference between the first occurring frame and all the other frames.
The threshold function provides a threshold value, such that it will convert the difference value with less than 30 to black. If the difference is greater than 30 it will convert those pixels to white color. THRESH_BINARY is used for this purpose.
Later, we make use of the findContours function to define the contour area for our image. And we add in the borders at this stage as well.
The contourArea function, as previously explained, removes the noises and the shadows. To make it simple, it will keep only that part white, which has an area greater than 1000 pixels as we’ve defined for that.
Later, we create a rectangular box around our object in the working frame.
And followed by this is this simple code:
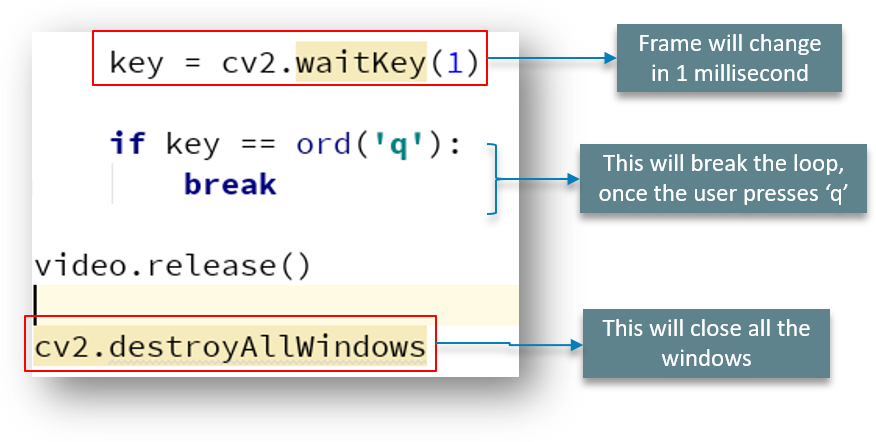
As discussed earlier, the frame changes every 1 millisecond and when the user enters ‘q’, the loop breaks and the window closes.
We’ve covered all of the major details on this OpenCV Python Tutorial blog. One thing that remains with our use-case is that we need to calculate the time for which the object was in front of the camera.
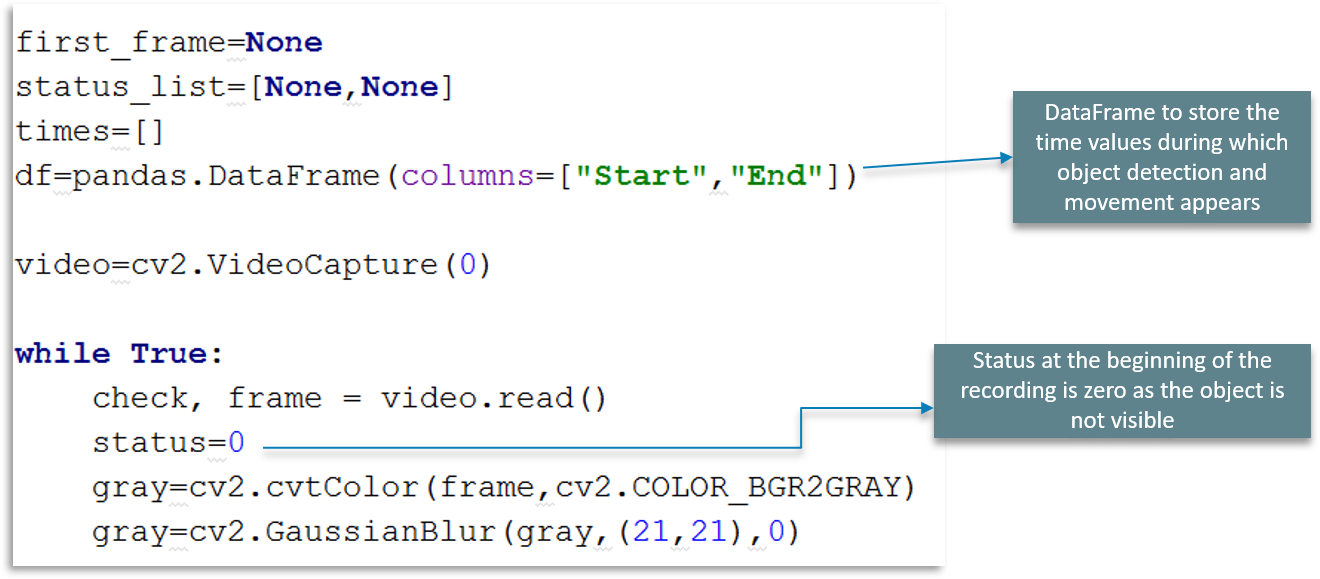
We make use of DataFrame to store the time values during which object detection and movement appear in the frame.
Followed by that is VideoCapture function as explained earlier. But here, we have a flag bit we call status. We use this status at the beginning of the recording to be zero as the object is not visible initially.
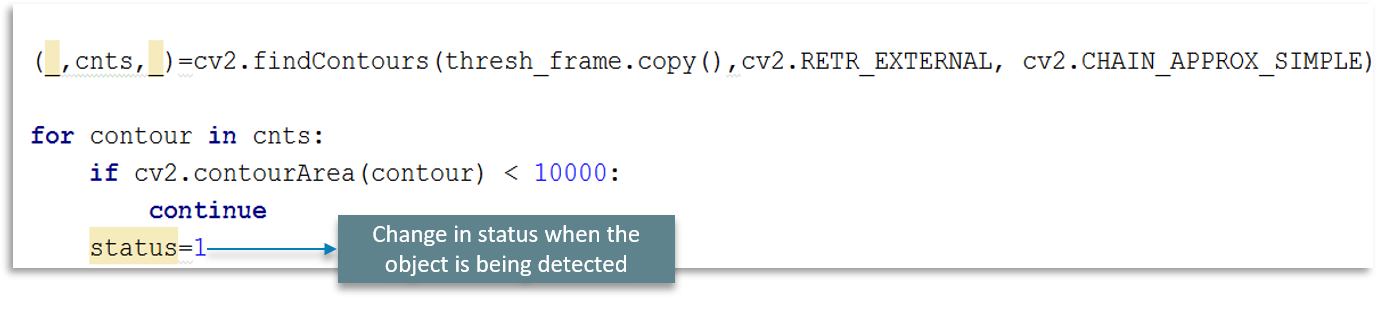
We will change the status flag to 1 when the object is being detected as shown in the above figure. Pretty simple, right?
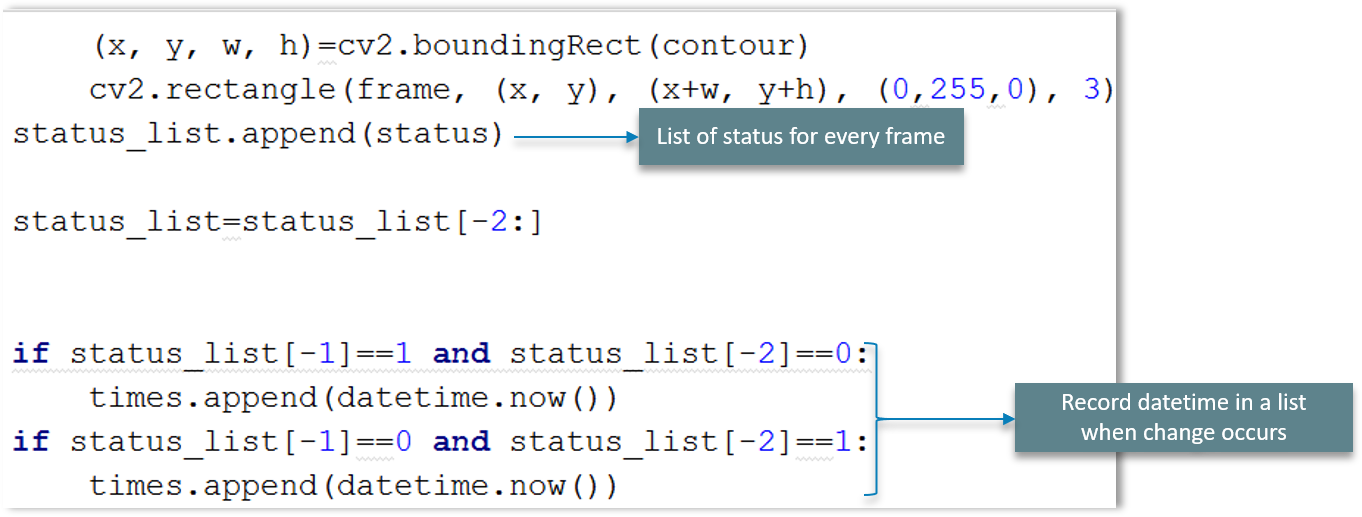
We are going to make a list of the status for every scanned frame and later record the date and time using datetime in a list if and where a change occurs.

And we store the time values in a DataFrame as shown in the above explanatory diagram. We’ll conclude by writing the DataFrame to a CSV file as shown.
The final step in our use-case to display the results. We are displaying the graph which denotes the motion on 2-axes. Consider the below code:
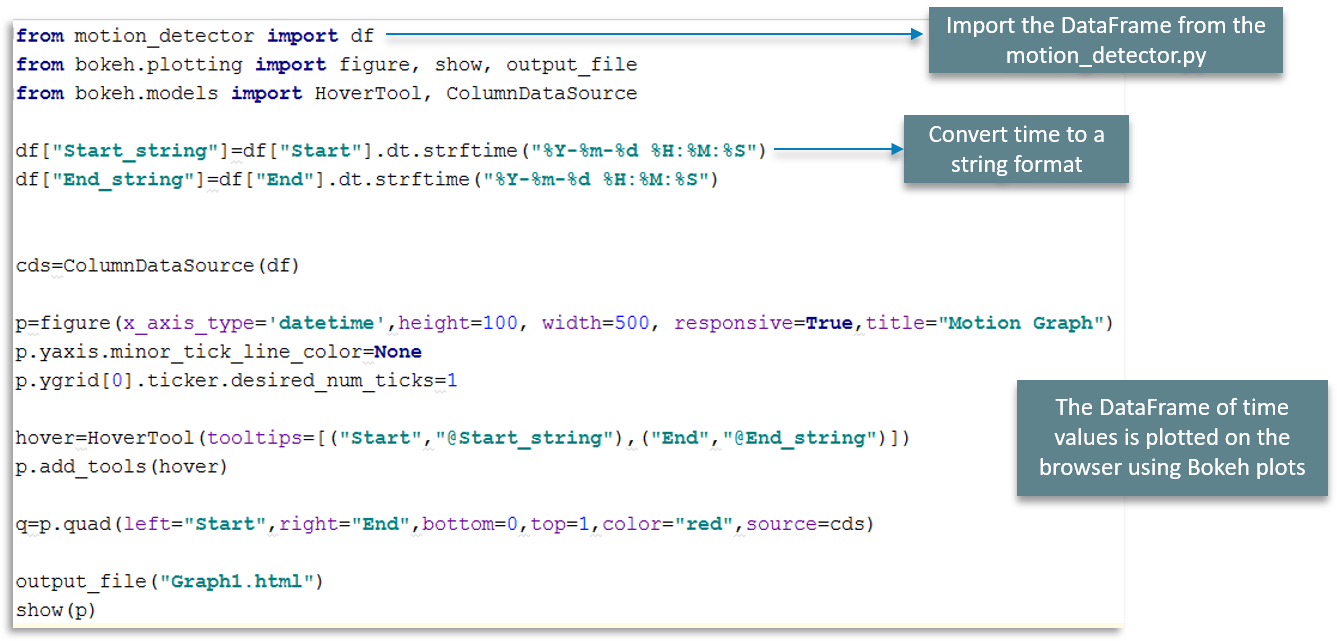
To begin with, we import the DataFrame from the motion_detector.py file.
The next step involves converting time to a readable string format which can be parsed.
Lastly, the DataFrame of time values is plotted on the browser using Bokeh plots.
Output:
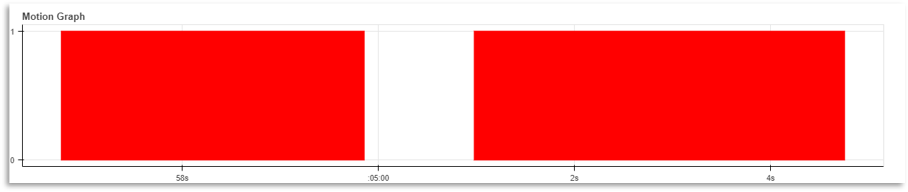
I hope this OpenCV Python tutorial helps you in learning all the fundamentals needed to get started with OpenCV using Python.
This will be very handy when you are trying to develop applications that require image recognition and similar principles. Now, you should also be able to use these concepts to develop applications easily with the help of OpenCV in Python.
After reading this blog on OpenCV Python tutorial, I am pretty sure you want to know more about Python. To know more about Python you can refer the following blogs:
To get in-depth knowledge on Python along with its various applications, you can enroll here for live online training with 24/7 support and lifetime access.
Got a question? Please mention it in the comments section of this “OpenCV Python Tutorial” blog and I will get back to you as soon as possible.







































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP