Apache Spark is one of the best frameworks when it comes to Big Data analytics. No sooner this powerful technology integrates with a simple yet efficient language like Python, it gives us an extremely handy and easy to use API called PySpark. In this article, I am going to throw some light on one of the building blocks of PySpark called Resilient Distributed Dataset or more popularly known as PySpark RDD.
By the end of this PySpark RDD tutorial, you would have an understanding of the below topics:
Why RDDs?
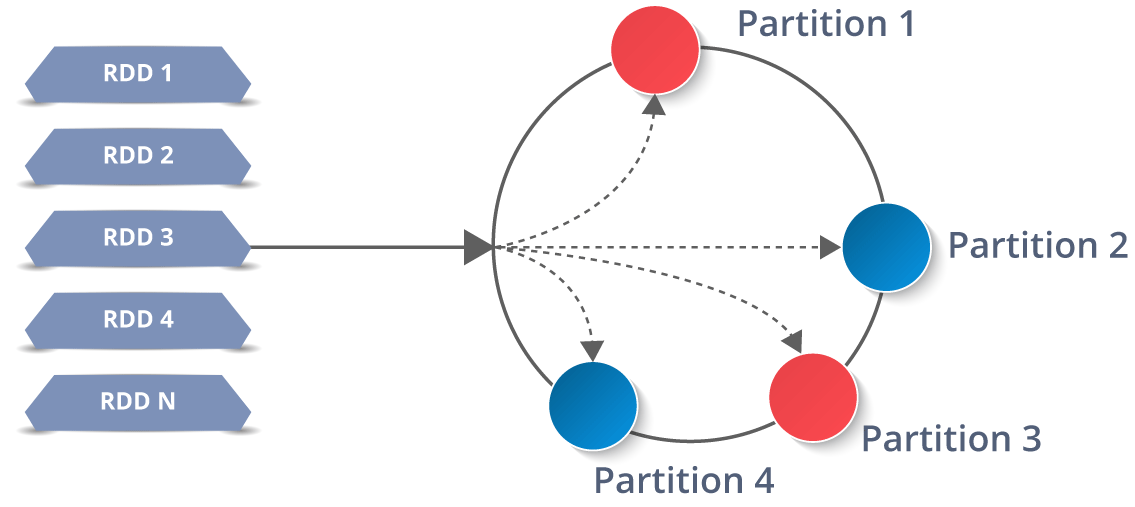
Iterative distributed computing, i.e., processing of data over multiple jobs requires reusing and sharing of data among them. Before RDDs came into the picture, frameworks like Hadoop faced difficulty in processing multiple operations/jobs. Also, a stable and distributed intermediate data store was needed, like HDFS or Amazon S3. These media for Data sharing helped in performing various computations like Logistic Regression, K-means clustering, Page rank algorithms, ad-hoc queries etc. But nothing comes for free, data sharing leads to slow data processing because of multiple I/O operation like replication and serialization. This scenario is depicted below:

Thus, there was a need for something which can overcome the issue of multiple I/O operations through data sharing and reduce its number. This is where RDDs exactly fit into the picture.
You may go through the webinar recording of PytSpark RDDs where our instructor has explained the topics in a detailed manner with various examples.
PySpark RDD Tutorial | PySpark Online Training | Edureka
This video will provide you with detailed and comprehensive knowledge of RDD, which are considered the backbone of Apache Spark.
What are PySpark RDDs?
Resilient Distributed Datasets (RDDs) are a distributed memory abstraction that helps a programmer to perform in-memory computations on large clusters that too in a fault-tolerant manner.
RDDs are considered to be the backbone of PySpark. It’s one of the pioneers in the fundamental schema-less data structure, that can handle both structured and unstructured data. The in-memory data sharing makes RDDs 10-100x faster than network and disk sharing.
 Now you might be wondering about its working. Well, the data in an RDD is split into chunks based on a key. RDDs are highly resilient, i.e, they are able to recover quickly from any issues as the same data chunks are replicated across multiple executor nodes. Thus, even if one executor node fails, another will still process the data. This allows you to perform your functional calculations against your dataset very quickly by harnessing the power of multiple nodes.
Now you might be wondering about its working. Well, the data in an RDD is split into chunks based on a key. RDDs are highly resilient, i.e, they are able to recover quickly from any issues as the same data chunks are replicated across multiple executor nodes. Thus, even if one executor node fails, another will still process the data. This allows you to perform your functional calculations against your dataset very quickly by harnessing the power of multiple nodes.
 Moreover, once you create an RDD it becomes immutable. By immutable I mean, an object whose state cannot be modified after it is created, but they can surely be transformed.
Moreover, once you create an RDD it becomes immutable. By immutable I mean, an object whose state cannot be modified after it is created, but they can surely be transformed.
Before I move ahead with this PySpark RDD Tutorial, let me lay down few more intriguing features of PySpark.
Features Of RDDs

- In-Memory Computations: It improves the performance by an order of magnitudes.
- Lazy Evaluation: All transformations in RDDs are lazy, i.e, doesn’t compute their results right away.
- Fault Tolerant: RDDs track data lineage information to rebuild lost data automatically.
- Immutability: Data can be created or retrieved anytime and once defined, its value can’t be changed.
- Partitioning: It is the fundamental unit of parallelism in PySpark RDD.
- Persistence: Users can reuse PySpark RDDs and choose a storage strategy for them.
- Coarse-Grained Operations: These operations are applied to all elements in data sets through maps or filter or group by operation.
In the next section of PySpark RDD Tutorial, I will introduce you to the various operations offered by PySpark RDDs.
RDD Operations in PySpark
RDD supports two types of operations namely:
- Transformations: These are the operations which are applied to an RDD to create a new RDD. Transformations follow the principle of Lazy Evaluations (which means that the execution will not start until an action is triggered). This allows you to execute the operations at any time by just calling an action on the data. Few of the transformations provided by RDDs are:
- map
- flatMap
- filter
- distinct
- reduceByKey
- mapPartitions
- sortBy
- Actions: Actions are the operations which are applied on an RDD to instruct Apache Spark to apply computation and pass the result back to the driver. Few of the actions include:
- collect
- collectAsMap
- reduce
- countByKey/countByValue
- take
- first
Let me help you to create an RDD in PySpark and apply few operations on them.
Creating and displaying an RDD
myRDD = sc.parallelize([('JK', 22), ('V', 24), ('Jimin',24), ('RM', 25), ('J-Hope', 25), ('Suga', 26), ('Jin', 27)])
myRDD.take(7)

Reading data from a text file and displaying the first 4 elements
New_RDD = sc.textFile("file:///home/edureka/Desktop/Sample")
New_RDD.take(4)

Changing minimum number of partitions and mapping the data from a list of strings to list of lists
CSV_RDD = (sc.textFile("file:///home/edureka/Downloads/fifa_players.csv", minPartitions= 4).map(lambda element: element.split(" ")))
CSV_RDD.take(3)

Counting the total number of rows in RDD
CSV_RDD.count()
![]()
Creating a function to convert the data into lower case and splitting it
def Func(lines): lines = lines.lower() lines = lines.split() return lines Split_rdd = New_RDD.map(Func) Split_rdd.take(5)

Creating a new RDD with flattened data and filtering out the ‘stopwords’ from the entire RDD
stopwords = ['a','all','the','as','is','am','an','and','be','been','from','had','I','I’d','why','with'] RDD = New_RDD.flatMap(Func) RDD1 = RDD.filter(lambda x: x not in stopwords) RDD1.take(4)
![]()
Filtering the words starting with ‘c’
import re
filteredRDD = RDD.filter(lambda x: x.startswith('c'))
filteredRDD.distinct().take(50)
Grouping the data by key and then sorting it
rdd_mapped = RDD.map(lambda x: (x,1)) rdd_grouped = rdd_mapped.groupByKey() rdd_frequency = rdd_grouped.mapValues(sum).map(lambda x: (x[1],x[0])).sortByKey(False) rdd_frequency.take(10)

Creating RDDs with key-value pair
a = sc.parallelize([('a',2),('b',3)])
b = sc.parallelize([('a',9),('b',7),('c',10)])Performing Join operation on the RDDs
c = a.join(b) c.collect()
![]()
Creating an RDD and performing a lambda function to get the sum of elements in the RDD
num_rdd = sc.parallelize(range(1,5000)) num_rdd.reduce(lambda x,y: x+y)
 Using ReduceByKey transformation to reduce the data
Using ReduceByKey transformation to reduce the data
data_keydata_key = sc.parallelize([('a', 4),('b', 3),('c', 2),('a', 8),('d', 2),('b', 1),('d', 3)],4)
data_keydata_key.reduceByKey(lambda x, y: x + y).collect()![]()
Saving the data in a text file
RDD3.saveAsTextFile("file:///home/edureka/Desktop/newoutput.txt")Sorting the data based on a key
test = [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
sc.parallelize(test).sortByKey(True, 1).collect()![]()
Performing Set Operations
##Creating two new RDDs rdd_a = sc.parallelize([1,2,3,4]) rdd_b = sc.parallelize([3,4,5,6])
- Intersection
rdd_a.intersection(rdd_b).collect()
![]()
- Subtraction
rdd_a.subtract(rdd_b).collect()
![]()
- Cartesian
rdd_a.cartesian(rdd_b).collect()

- Union
rdd_a.union(rdd_b).collect()
![]()
Subscribe to our YouTube channel to learn more..!
I hope you are familiar with PySpark RDDs by now. So let’s dive deeper and see how you can use these RDDs to solve a real-life use case.
PySpark RDD Use Case

Problem Statement
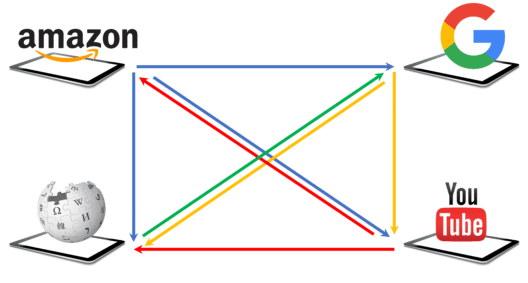
You have to calculate the page rank of a set of web pages based on the illustrated webpage system. Below is a diagram representing four web pages, Amazon, Google, Wikipedia, and Youtube, in our system. For the ease of access, let’s name them a,b,c, and d respectively. Here, the web page ‘a’ has outbound links to pages b, c, and d. Similarly, page ‘b’ has an outbound link to pages d and c. Web page ‘c’ has an outbound link to page b, and page ‘d’ has an outbound link to pages a and c.
Solution
To solve this, we will be implementing the page-rank algorithm that was developed by Sergey Brin and Larry Page. This algorithm helps in determining the rank of a particular web page within a group of web pages. Higher the page rank, higher it will appear in a search result list. Thus, will hold more relevance.
The contribution to page rank is given by the following formula:
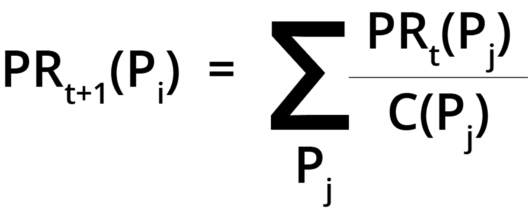
Let me break it down for you:
PRt+1(Pi) = Page rank of a site
PRt(Pj) = Page rank of an inbound link
C(Pj) = Number of links on that page
In our problem statement, it is shown that the web page ‘a’ has three outbound links. So, according to the algorithm, the contribution to page rank of page d by page a is PR(a) / 3. Now we have to calculate the contribution of page b to page d. Page b has two outbound links: the first to page c, and the second to page d. Hence, the contribution by page b is PR(b) / 2.
So the page rank of page d will be updated as follows, where s is known as the damping factor :
PR(d) = 1 – s + s × (PR(a)/3 + PR(b)/2)
Let’s now execute this using PySpark RDDs.
##Creating Nested Lists of Web Pages with Outbound Links pageLinks = [['a', ['b','c','d']], ['c', ['b']],['b', ['d','c']],['d', ['a','c']]] ##Initializing Rank #1 to all the webpages pageRanks = [['a',1],['c',1],['b',1],['d',1]] ##Defining the number of iterations for running the page rank ###It will return the contribution to the page rank for the list of URIs def rankContribution(uris, rank): numberOfUris = len(uris) rankContribution = float(rank) / numberOfUris newrank =[] for uri in uris: newrank.append((uri, rankContribution)) return newrank ##Creating paired RDDs of link data pageLinksRDD = sc.parallelize(pageLinks, 2) pageLinksRDD.collect()
![]()
##Creating the paired RDD of our rank data pageRanksRDD = sc.parallelize(pageRanks, 2) pageRanksRDD.collect()
![]()
##Defining the number of iterations and the damping factor, s numIter = 20 s = 0.85 ##Creating a Loop for Updating Page Rank for i in range(numIter): linksRank = pageLinksRDD.join(pageRanksRDD) contributedRDD = linksRank.flatMap(lambda x : rankContribution(x[1][0],x[1][1])) sumRanks = contributedRDD.reduceByKey(lambda v1,v2 : v1+v2) pageRanksRDD = sumRanks.map(lambda x : (x[0],(1-s)+s*x[1])) pageRanksRDD.collect()

This gives us the result that ‘c’ has the highest page rank followed by ‘a’, ‘d’ and ‘b’.
With this, we come to an end of this PySpark RDD. Hope it helped in adding some value to your knowledge.