

Advanced DevOps Certification Training with G ...
- 24k Enrolled Learners
- Weekend
- Live Class
(7990)





 Copy Link!
Copy Link!Previously, system administrators made use of shell scripts to run their servers, and this method had zero scalability. It is a daunting task to constantly modify scripts for hundreds or thousands of ever-changing servers and their system configurations.
In this article on puppet modules & manifests let’s see how we could use puppet modules for automating server setup, program installation, and system management.
This blog will cover the following topics:
Puppet is one of the popularly used DevOps tools that is widely used for configuration management. It is used to bring about consistency in the Infrastructure. Puppet can define infrastructure as code, manage multiple servers, and enforce system configuration, thus helping in automating the process of infrastructure management.
Puppet has its own configuration language, Puppet DSL. As with other DevOps programs, Puppet automates changes, eliminating manual script-driven changes. However, Puppet is not simply another shell language, nor is it a pure programming language, such as PHP. Instead, Puppet uses a declarative model-based approach to IT automation. This enables Puppet to define infrastructure as code and enforce system configuration with programs.
Before getting on with the demo, let’s look at a few core aspects of puppet programming.
Find out our Automation Testing Training in Top Cities/Countries
| India | Other Cities/Countries |
| Bangalore | UK |
| Hyderabad | USA |
| Pune | Canada |
| Chennai | Singapore |
Key terms in Puppet Programming
A puppet program is called manifest and has a filename with .pp extension. Puppet’s default main manifest is /etc/puppet/manifests/site.pp. (This defines global system configurations, such as LDAP configuration, DNS servers, or other configurations that apply to every node).
Within these manifests are code blocks called classes other modules can call. Classes configure large or medium-sized chunks of functionality, such as all the packages, configuration files, and services needed to run an application. Classes make it easier to reuse Puppet code and improve readability.
Puppet code is made up mostly of resource declarations. A resource describes a specific element about the system’s desired state. For example, it can include that a specific file should exist or a package should be installed.
Except for the main site.pp manifest, it stores manifests in modules.
All of our Puppet code is organized in modules which are the basic building blocks of puppet that we can reuse and share. Each module manages a specific task in the infrastructure, such as installing and configuring a piece of software.
Modules contain Puppet classes, defined types, tasks, task plans, capacities, resource types, and plugins, for example, custom types or facts. Install modules in the Puppet module-path. Puppet loads all content from every module in the module-path, making this code available for use.
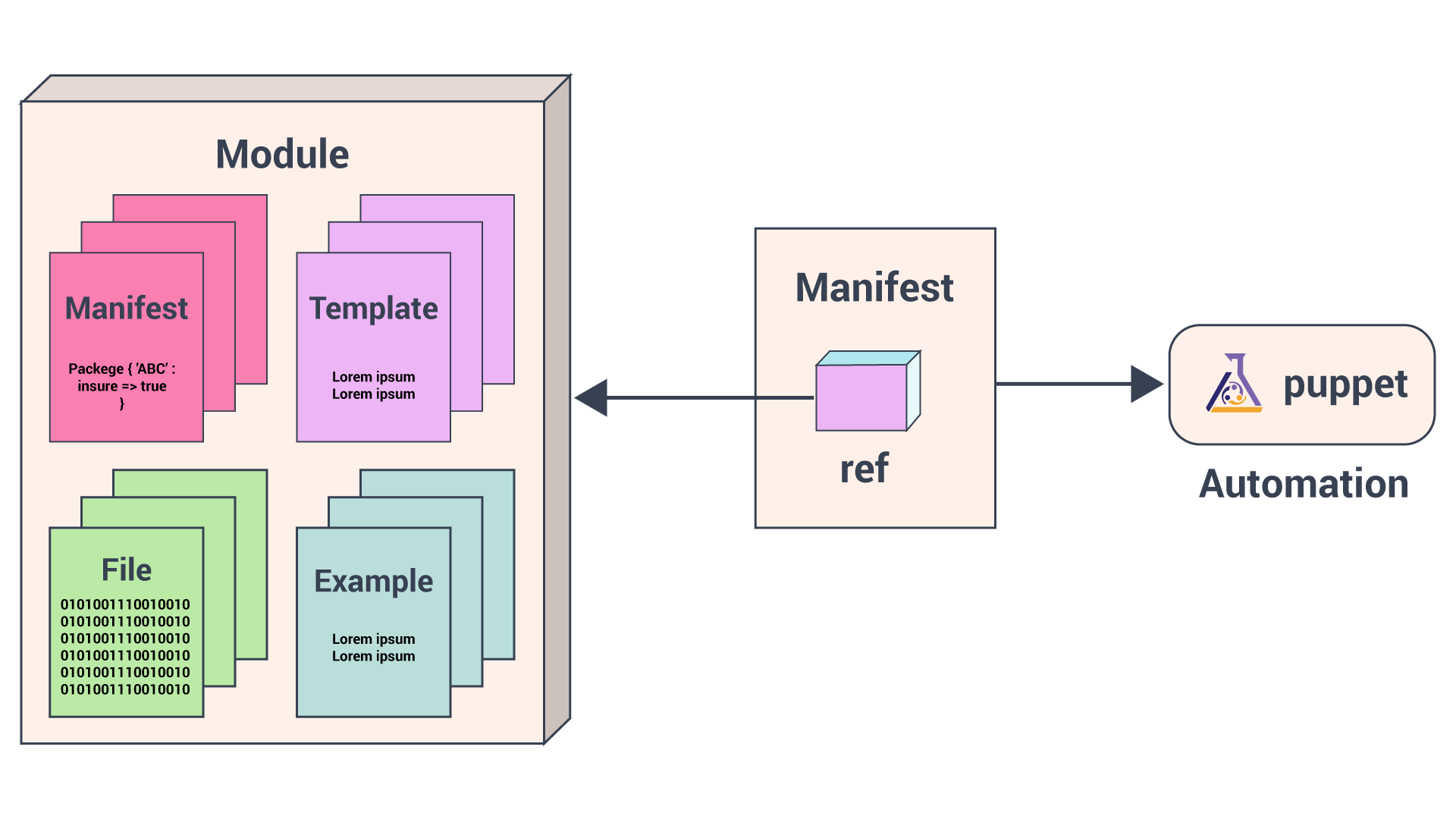 Puppetlabs has pre-defined modules that we can use instantly by downloading them from
Puppetlabs has pre-defined modules that we can use instantly by downloading them from PuppetForge. You could also create a custom puppet module to suit your requirements.
Puppet Program Workflow
We will use Puppet’s declarative language to describe the desired state of the system in files called manifests. Manifests describe how you should configure your network and operating system resources, such as files, packages, and services.

Puppet compiles manifests into catalogs and it applies each catalog to its corresponding node to ensure that configuration of the node is correct across your infrastructure.
Automation Testing Online Course: Your Gateway to a Lucrative Tech Career.
This article on puppet modules is hands-on that would show two ways of using a puppet module and also teach you how to automate the installation of a server configured with these two modules.
To begin with, ensure that you have a Puppet infrastructure set up ready that would include a puppet master server and 2 puppet agents.
Here’s an outline of what we will achieve in this hands-on:
So Let’s begin with the hands-on:
In this puppet module, we will deal with tasks such as downloading the Apache package, configuring files, and setting up virtual hosts.
cd /etc/puppet/modules sudo mkdir apache
cd apache
sudo mkdir {manifests, templates, files, examples}cd manifests
init.pp -> to download the Apache package
params.pp -> to define any variables and parameters
config.pp -> to manage any configuration files for the Apache service.
vhosts.pp -> to define the virtual hosts.
This module will also make use of Hiera (a built-in key-value configuration data lookup system, used for separating data from Puppet code) data, to store variables for each node.
Now we will create a init.pp file under manifests directory to hold the apache package.
As we have 2 different OS (ubuntu and CentOS7) that use different package names for Apache, we will have to use a variable $apachename.
/etc/puppetlabs/code/environments/production/modules/apache/manifests/init.pp
class apache {
package { 'apache':
name => $apachename,
ensure => present,
}
}
package resource allows for the management of a package. This is used to add, remove, or ensure a package is present.
In most cases, the name of the resource (apache, above) should be the name of the package being managed. Because of the different naming conventions, we call the actual name of the package upon with the name reference. So name, calls for the yet-undefined variable $apachename.
ensure reference ensures that the package is present.
The params.pp file will define the needed variables. While we could define these variables within the init.pp file, since more variables will need to be used outside of the resource type itself, using a params.pp file allows for variables to be defined in if statements and used across multiple classes.
Create a params.pp file and the following code.
/etc/puppetlabs/code/environments/production/modules/apache/manifests/params.pp
class apache::params {
if $::osfamily == 'RedHat' {
$apachename = 'httpd'
}
elsif $::osfamily == 'Debian' {
$apachename = 'apache2'
}
else {
fail('this is not a supported distro.')
}
}
Outside of the original init.pp class, each class name needs to branch off from apache. We call this class as apache::params. The name after the double colon should share a name with the file. An if statement is used to define the parameters, pulling from information provided by Facter, Puppet has facter installation as a part of its installation itself. Here, Facter will pull down the operating system family (osfamily), to discern if it is Red Hat or Debian-based.
With the parameters finally defined, we need to call the params.pp file and the parameters into init.pp. To do this, we need to add the parameters after the class name, but before the opening curly bracket ( { ).
So the init.pp that we created earlier should look something like this:
class apache ( $apachename = $::apache::params::apachename,) inherits ::apache::params
{
package { 'apache':
name => $apachename,
ensure => present,
}
}
The value string $::apache::params::value tells Puppet to pull the values from the apache modules, params class, followed by the parameter name. The fragment inherits ::apache::params allows for init.pp to inherit these values.
The Apache configuration file will be different depending on whether you are working on a Red Hat- or Debian-based system.
You can find the following dependency files at the end of this demo: httpd.conf (Red Hat), apache2.conf (Debian).
httpd.conf and apache2.conf in separate files and save them in the files directory at /etc/puppetlabs/code/environments/production/modules/apache/files.httpd.conf file. If you do not want to change this setting, we should add a comment to the top of each file:/etc/puppetlabs/code/environments/production/modules/apache/files/httpd.conf#This file is managed by puppet
Add these files to the init.pp file, so Puppet will know the location of these files on both the master server and agent nodes. To do this, we use the file resource.
/etc/puppetlabs/code/environments/production/modules/apache/manifests/init.pp
file { 'configuration-file':
path =>$conffile,
ensure =>file,
source =>$confsource,
}
Because we have the configuration files in two different locations, we give the resource the generic name configuration-file with the file path defined as a parameter with the path attribute.
ensure ensures that it is a file.
source provides the location on the Puppet master of the files created above.
Open the params.pp file.
We define the $conffile and $confsource variables within the if statement:
/etc/puppetlabs/code/environments/production/modules/apache/manifests/params.pp
if $::osfamily == 'RedHat' {
...
$conffile = '/etc/httpd/conf/httpd.conf'
$confsource = 'puppet:///modules/apache/httpd.conf'
}
elsif $::osfamily == 'Debian' {
...
$conffile = '/etc/apache2/apache2.conf'
$confsource = 'puppet:///modules/apache/apache2.conf'
}
else {
...
We need to add the parameters to the beginning of the apache class declaration in the init.pp file, similar to the previous example.
When the configuration file changes, Apache needs to restart. To automate this, we can use the service resource in combination with the notify attribute, which will call the resource to run whenever the configuration file is changed:
/etc/puppetlabs/code/environments/production/modules/apache/manifests/init.pp
file { 'configuration-file':
path =>$conffile,
ensure =>file,
source =>$confsource,
notify => Service['apache-service'],
}
service { 'apache-service':
name =>$apachename,
hasrestart => true,
}
service resource uses the already-created parameter that defined the Apache name on Red Hat and Debian systems.
hasrestart attribute is used to trigger a restart of the defined service.
Depending on your system’s distribution the virtual host’s files will be managed differently. Because of this, we will encase the code for virtual hosts in an if statement, similar to the one used in the params.pp class but containing actual Puppet resources.
vhosts.pp file. Add the skeleton of the if statement:/etc/puppetlabs/code/environments/production/modules/apache/manifests/vhosts.pp
class apache::vhosts {
if $::osfamily == 'RedHat' {
}
elsif $::osfamily == 'Debian' {
}
else {}
}
The location of the virtual host file on our CentOS 7 server is /etc/httpd/conf.d/vhost.conf. You need to create the file as a template on the Puppet master. Do the same for the Ubuntu virtual hosts file, which is located at /etc/apache2/sites-available/example.com.conf, replacing example.com with the server’s FQDN.
For Red Hat systems:
/etc/puppetlabs/code/environments/production/modules/apache/templates/vhosts-rh.conf.erb
<VirtualHost *:80>
ServerAdmin <%= @adminemail %>
ServerName <%= @servername %>
ServerAlias www.<%= @servername %>
DocumentRoot /var/www/<%= @servername -%>/public_html/
ErrorLog /var/www/<%- @servername -%>/logs/error.log
CustomLog /var/www/<%= @servername -%>/logs/access.log combined
</Virtual Host>
For Debian systems:
/etc/puppet/modules/apache/templates/vhosts-deb.conf.erb
<VirtualHost *:80>
ServerAdmin <%= @adminemail %>
ServerName <%= @servername %>
ServerAlias www.<%= @servername %>
DocumentRoot /var/www/html/<%= @servername -%>/public_html/
ErrorLog /var/www/html/<%- @servername -%>/logs/error.log
CustomLog /var/www/html/<%= @servername -%>/logs/access.log combined
<Directory /var/www/html/<%= @servername -%>/public_html>
Require all granted
</Directory>
</Virtual Host>
We use only two variables in these files: adminemail and servername. We will define these on a node-by-node basis, within the site.pp file.
vhosts.pp file. The templates created can now be referenced in the code:/etc/puppetlabs/code/environments/production/modules/apache/manifests/vhosts.pp
class apache::vhosts {
if $::osfamily == 'RedHat' {
file { '/etc/httpd/conf.d/vhost.conf':
ensure => file,
content => template('apache/vhosts-rh.conf.erb'),
}
} elsif $::osfamily == 'Debian' {
file { "/etc/apache2/sites-available/$servername.conf":
ensure => file,
content => template('apache/vhosts-deb.conf.erb'),
}
} else {
fail('This is not a supported distro.')
}
}
Both distribution families call to the file resource and take on the title of the virtual host’s location on the respective distribution. For Debian, this once more means referencing the $servername value. The content attribute calls the respective templates.
vhosts.conf file should resemble:/etc/puppetlabs/code/environments/production/modules/apache/manifests/vhosts.pp
class apache::vhosts {
if $::osfamily == 'RedHat' {
file { '/etc/httpd/conf.d/vhost.conf':
ensure => file,
content => template('apache/vhosts-rh.conf.erb'),
}
file { [ '/var/www/$servername',
'/var/www/$servername/public_html',
'/var/www/$servername/log', ]:
ensure => directory,
}
} elsif $::osfamily == 'Debian' {
file { "/etc/apache2/sites-available/$servername.conf":
ensure => file,
content => template('apache/vhosts-deb.conf.erb'),
}
file { [ '/var/www/$servername',
'/var/www/$servername/public_html',
'/var/www/$servername/logs', ]:
ensure => directory,
}
} else {
fail ( 'This is not a supported distro.')
}
}
apache/manifests/ directory, run the puppet parser on all files to ensure the Puppet coding is without error:sudo /opt/puppetlabs/bin/puppet parser validate init.pp params.pp vhosts.pp
It should return empty, with no issues.

init.pp file and include the created classes. Replace the values for $servername and $adminemail with your own:/etc/puppetlabs/code/environments/production/modules/apache/examples/init.pp
serveremail = 'webmaster@example.com' $servername = 'puppet.example.com' include apache include apache::vhosts
sudo /opt/puppetlabs/bin/puppet apply --noop init.pp
It should return no errors and output that it will trigger refreshes from events. To install and configure apache on the Puppet master, run again without –noop, if so desired.
cd /etc/puppetlabs/code/environments/production/manifests
Create a site.pp file, and include the Apache module for each agent node. Also input the variables for the adminemail and servername parameters. Your site.pp should resemble the following:
/etc/puppetlabs/code/environments/production/manifests/site.pp
node 'puppet-agent-ubuntu.example.com' {
$adminemail = 'webmaster@example.com'
$servername = 'puppet.example.com'
include apache
include apache::vhosts
}
node 'puppet-agent-centos.example.com' {
$adminemail = 'webmaster@example.com'
$servername = 'puppet.example.com'
include apache
include apache::vhosts
}
By default, the Puppet agent service on your managed nodes will automatically check with the master once every 30 minutes and apply any new configurations from the master. You can also manually invoke the Puppet agent process in-between automatic agent runs. To manually run the new module on your agent nodes, log in to the nodes and run:
sudo /opt/puppetlabs/bin/puppet agent -t
Now that we have learned how to create a module from scratch, let’s learn how to use a pre-existing module from the puppet forge of puppetlabs.
Puppet Forge already has many modules for the server to run. We can configure these just as extensively as a module you created and can save time since we need not create the module from scratch.
Ensure you are in the /etc/puppetlabs/code/environments/production/modules directory and install the Puppet Forge’s MySQL module by PuppetLabs. This will also install any prerequisite modules.
cd /etc/puppetlabs/code/environments/production/modules
sudo /opt/puppetlabs/bin/puppet module install puppetlabs-mysql
Before you create the configuration files for the MySQL module, consider that you may not want to use the same values across all agent nodes. To supply Puppet with the correct data per node, we use Hiera. You will use a different root password per node, thus creating different MySQL databases.
/etc/puppet and create Hiera’s configuration file hiera.yaml in the main puppet directory. You will use Hiera’s default values:/etc/puppetlabs/code/environments/production/hiera.yaml
---
version: 5
hierarchy:
- name: Common
path: common.yaml
defaults:
data_hash: yaml_data
datadir: data
common.yaml. It will define the default root password for MySQL:/etc/puppetlabs/code/environments/production/common.yaml
mysql::server::root_password: 'password'
We use the common.yaml file when a variable is not defined elsewhere. This means all servers will share the same MySQL root password. These passwords can also be hashed to increase security.
site.pp file. However, in this example, you will override some of the module’s defaults to create a database for each of your nodes.Edit the site.pp file with the following values:
node 'Puppetagent-ubuntu.example.com' {
$adminemail = 'webmaster@example.com'
$servername = 'hostname.example.com'
include apache
include apache::vhosts
include mysql::server
mysql::db { "mydb_${fqdn}":
user => 'myuser',
password => 'mypass',
dbname => 'mydb',
host => $::fqdn,
grant => ['SELECT', 'UPDATE'],
tag => $domain,
}
}
node 'Puppetagent-centos.example.com' {
$adminemail = 'webmaster@example.com'
$servername = 'hostname.example.com'
include apache
include apache::vhosts
include mysql::server
mysql::db { "mydb_${fqdn}":
user => 'myuser',
password => 'mypass',
dbname => 'mydb',
host => $::fqdn,
grant => ['SELECT', 'UPDATE'],
tag => $domain,
}
}
sudo /opt/puppetlabs/bin/puppet agent -t


Thus, the entire installation gets automated on the agent nodes by just applying the catalog. The code files and dependencies used for this demo can be found here.
I hope this demo has helped you in getting a clear idea of puppet modules and manifests and their usage for automating the IT infrastructure. In this case, your work becomes so easy, just specify the configurations in Puppet Master and Puppet agents will automatically evaluate the main manifest and apply the module that specifies Apache and MySQL setup. If you are stuck with any queries, please feel free to post them on Edureka Community.
Edureka is a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. This training will help you gain deep knowledge in Robotic Process Automation and hands-on experience in Automation Anywhere. Take your automation skills to new heights by earning your Automation Anywhere Certification to validate your expertise in RPA and boost your career prospects.





























 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP