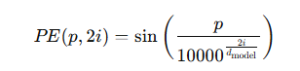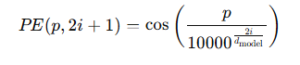Nidhi JhaMERN stack web developer with expertise in full-stack development. Skilled in React,...MERN stack web developer with expertise in full-stack development. Skilled in React, Node.js, Express, and MongoDB, building scalable web solutions.
Transformers have changed Natural Language Processing (NLP) by letting models understand the connections and background of data patterns. In contrast to standard models, which process data one piece at a time, transformers process whole sequences at once. There is a problem with this parallel processing, though: how does the model know the order of the tokens? In this case, positional decoding is used.
Table of Content
What is Positional Encoding in Transformers?
Positional Encoding is a way to add information about where tokens are in a series in the world of Transformers. Due to their simultaneous processing, Transformers don’t know how to put tokens in order by themselves. Positional Encoding adds sequence order to the model.
The first Transformer model, which was created by Vaswani et al., uses sinusoidal functions to create location encodes. These functions make patterns that are unique for each place. This lets the model tell the difference between positions in a sequence.
Why are positional encodings important?
Tasks like language translation, text summarization, and question-answering require an understanding of the token order. Because of word order, the sentences “The cat sat on the mat” and “On the mat sat the cat” have the same words but distinct meanings.
Positional Encodings enable Transformers to:
Capture Sequential Information: By adding positional information to token embeddings, the model can discern the order of tokens.
Facilitate Learning of Relationships: The model can learn relationships between tokens based on their positions, enhancing its understanding of context.
Generalize to Longer Sequences: Sinusoidal encodings allow the model to handle sequences longer than those encountered during training.
Example of Positional Encoding
For example, “Birds fly above clouds.”
An embedding layer is used to first transform each word in the phrase into a dense vector representation. Although the meaning of the phrases is captured by these embeddings, the sequence of the words in the sentence is not apparent. Positional encoding can help with that.
Each word in the phrase is turned into a token before it is fed into the Transformer model. Let us say that the tokens in this line are:
[“Birds”, “fly”, “above”, “the”, “clouds”]
After that, an embedding layer maps each word to a high-dimensional vector representation. These embeddings store information about the meaning of the words in the text. They don’t know anything about the order of the words, though.
Embeddings = {E₁, E₂, E₃, E₄, E₅}
Where each Eᵢ is a 4-dimensional vector. This is where positional encoding plays an important role. To help the model understand the order of words in a sequence, positional encodings are added to the word embeddings. They assign each token a unique representation based on its position in the sentence.
The Transformer can efficiently interpret and comprehend the entire sentence structure by integrating the positional context and the semantic meaning from the embedding.
Positional Encoding Layer in Transformers
Understanding the order of words is critical in Transformers, but because these models process all tokens at once (in parallel), they do not automatically know which word comes first, second, or last. The Positional Encoding layer fills that need.
It helps the model understand the general structure of the input sequence by giving each token more details about where it appears in the sentence. Unlike other weights in the network, this layer is independent of learning position.
Rather, it generates distinct patterns for every position using a set mathematical technique. To help the model distinguish between the first and the fifth word—even when the words are identical—these patterns are appended to the word embeddings.
For even-numbered dimensions in the vector (like the 0th, 2nd, 4th…):
For odd-numbered dimensions (like the 1st, 3rd, 5th…):
Here:
p is the position of the word in the sentence,
i is the dimension index,
and d_model is the total number of dimensions in the embedding.
Why apply sine and cosine? Repeating wave patterns are produced by these functions, and as position increases, they alter gradually and distinctively. Even for lengthy sequences, the model can determine the placement of each token due to the sufficient variance created by alternating sine for even indices and cosine for odd indices.
As a result, the Transformer gains an innate sense of sequence rather than having to memorize placements, which makes it easier to identify patterns and relationships.
Code Implementation of Positional Encoding in Transformers
Two well-known Python libraries, NumPy and TensorFlow, will be used to implement positional encoding. These enable us to construct layers that work with Transformer models and carry out mathematical operations effectively.
Let’s dissect the calculation’s main concept before moving on to the complete code:
position = 50 This indicates the number of places (or time steps) that we wish to encode. For instance, we provide 50 positional encodings for a text with 50 tokens.
d_model equals 512. Each word embedding has this size. It specifies the number of features that each word will have in the model.
Angle calculation The method figures out a set of angles for each place and dimension of embedding. To make the final positional encoding, these angle values are then put through sine or cosine functions, based on whether the dimension index is even or odd.
We are going to make a code that makes positional encodings, which add information about position to token embeddings. This lets the Transformer model figure out the order of words without having to use convolution or recursion.
import numpy as np
import tensorflow as tf
def generate_positional_encoding(seq_length, embed_dim):
"""
Generates positional encoding for a given sequence length and embedding dimension.
Args:
seq_length (int): Number of positions in the sequence (e.g., number of tokens).
embed_dim (int): Dimensionality of each word vector.
Returns:
Tensor of shape (1, seq_length, embed_dim) with positional encodings.
"""
positions = np.arange(seq_length)[:, np.newaxis]
dims = np.arange(embed_dim)[np.newaxis, :]
angle_rates = 1 / np.power(10000, (2 * (dims // 2)) / np.float32(embed_dim))
angle_radians = positions * angle_rates
# Apply sine to even indices (0, 2, 4, ...)
angle_radians[:, 0::2] = np.sin(angle_radians[:, 0::2])
# Apply cosine to odd indices (1, 3, 5, ...)
angle_radians[:, 1::2] = np.cos(angle_radians[:, 1::2])
# Add a batch dimension
positional_encoding = angle_radians[np.newaxis, ...]
return tf.cast(positional_encoding, dtype=tf.float32)
# Example usage
sequence_length = 60 # Number of tokens in the sequence
embedding_size = 256 # Dimensionality of each token embedding
position_encodings = generate_positional_encoding(sequence_length, embedding_size)
print("Shape of Positional Encoding:", position_encodings.shape)
Output : Shape of Positional Encoding: (1, 60, 256)
The array shows positional encodings for a sequence of length 60 with a model dimension of 256. Each row represents a token’s position, and each column represents a dimension in the embedding space.
Conclusion
Positional encoding is needed for Transformer models to understand the order of words in a string. Because transformers process input data all at once and don’t naturally know what comes next, adding positional information makes sure the model can catch the flow and structure of language.
By combining position-based patterns with semantic information from embeddings using sine and cosine functions, transformers can quickly do jobs like translating, summarizing, and answering questions while having a better understanding of the context.
If you want to build your own Transformer or just learn how it works, you need to understand Positional Encoding in order to understand how these models read and deal with sequential data.