





A Brief Introduction to Pig
Pig is an open-source high level data flow system, which provides a simple language called Pig Latin, for queries and data manipulation.
Pig is being utilized by companies like Yahoo, Google and Microsoft for collecting huge amounts of data sets in the form of click streams, search logs and web crawls. Pig is also used in some form of ad-hoc processing and analysis of all the information.
Need for Pig
- Easy to learn, especially if you’re familiar with SQL.
- Multi-query approach decreases the number of times data is scanned. This means 1/20th the lines of code and 1/16th the development time when compared to writing raw MapReduce.
- Performance is in par with raw MapReduce
- Provides data operations like filters, joins, ordering, etc. and nested data types like tuples, bags, and maps, that are missing from MapReduce.
- Easy to write and read.
Take your data analysis skills to the next level with our cutting-edge Big Data Course.
Purpose of Pig’s Creation
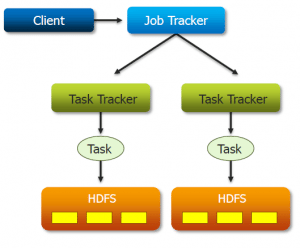
Pig was formerly developed by Yahoo in 2006, for researchers to have an ad-hoc way of creating and executing MapReduce jobs on very large data sets. It was created to reduce the development time through its multi-query approach.
Introduction to Hive
Hive was initially found by Jeff Hammerbacher while he was still with Facebook. Facebook was receiving humongous amount of data every day. As a result, they wanted to look for different ways to store, mine and analyze data. Hive was born as a result of this search.
With Hive being implemented by Facebook, the data is now collected by nightly cronjobs and then stored in to OracleDB. The ETL is done through hardcoded Python. With the help of Hive, Facebook is now able to handle from 10’s of GB of data in 2006 to 10s of TB of data at the moment. The best way to become a Data Engineer is by getting the Azure Data Engineering Training in Washington.
What is Hive?

Hive is Data warehousing package built on top of Hadoop for performing data analysis. Hive is targeted for users who are comfortable with SQL. Hive has a programming language called ‘HiveQL’ which is similar to SQL. The Hive is used for managing and querying structured data. Please note that the Hive can be used in places where the data is ‘Structured’.
The Hive abstracts complexity of Hadoop, i.e. you don’t have to write a mapreduce program. With Hive, there is also no need for the user to learn Java and Hadoop APIs. With Hive’s incredible features, Facebook is now able to analyze several Terabytes of data every day. Learn more about Big Data and its applications from the Azure Data Engineer Associate.
Pig Vs Hive
Here are some basic difference between Hive and Pig which gives an idea of which to use depending on the type of data and purpose.

Why Go for Hive When Pig is There?
So why go for Hive when Pig is there. The tabular column below gives a comprehensive comparision between the two. The Hive can be used in places where partitions are necessary and when it is essential to define and create cross-language services for numerous languages.

Embark on a transformative journey into the world of data engineering and unlock the power of data with our Data Engineering Courses.
Got a question for us? Mention them in the comments section and we will get back to you.
Related Posts:



































pig Latin is data flow language But hive is a query processing language.