





Pig Programming: Create Your First Apache Pig Script
In our Hadoop Tutorial Series, we will now learn how to create an Apache Pig script. Apache Pig scripts are used to execute a set of Apache Pig commands collectively. This helps in reducing the time and effort invested in writing and executing each command manually while doing this in Pig programming. It is also an integral part of the Hadoop course curriculum. This blog is a step by step guide to help you create your first Apache Pig script.
Apache Pig script Execution Modes
Local Mode: In ‘local mode’, you can execute the pig script in local file system. In this case, you don’t need to store the data in Hadoop HDFS file system, instead you can work with the data stored in local file system itself.
MapReduce Mode: In ‘MapReduce mode’, the data needs to be stored in HDFS file system and you can process the data with the help of pig script.
Apache Pig Script in MapReduce Mode
Let us say our task is to read data from a data file and to display the required contents on the terminal as output.
The sample data file contains following data:
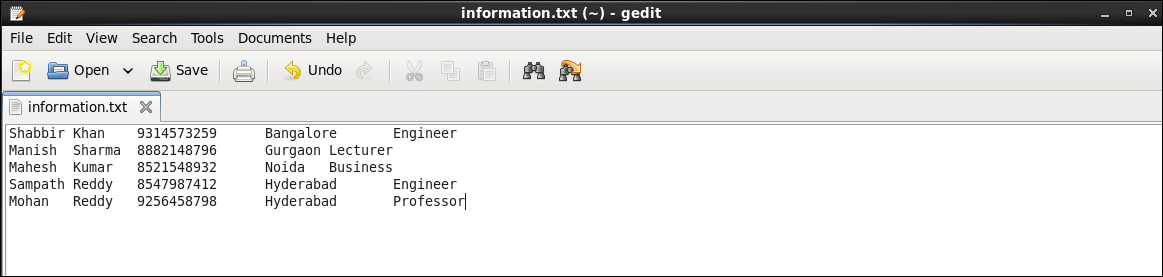
Save the text file with the name ‘information.txt’
The sample data file contains five columns FirstName, LastName, MobileNo, City, and Profession separated by tab key. Our task is to read the content of this file from the HDFS and display all the columns of these records.
To process this data using Pig, this file should be present in Apache Hadoop HDFS.
Command: hadoop fs –copyFromLocal /home/edureka/information.txt /edureka

Step 1: Writing a Pig script
Create and open an Apache Pig script file in an editor (e.g. gedit).
Command: sudo gedit /home/edureka/output.pig
This command will create a ‘output.pig’ file inside the home directory of edureka user.

Let’s write few PIG commands in output.pig file.
A = LOAD ‘/edureka/information.txt’ using PigStorage (‘ ’) as (FName: chararray, LName: chararray, MobileNo: chararray, City: chararray, Profession: chararray); B = FOREACH A generate FName, MobileNo, Profession; DUMP B;
Save and close the file.
- The first command loads the file ‘information.txt’ into variable A with indirect schema (FName, LName, MobileNo, City, Profession).
- The second command loads the required data from variable A to variable B.
- The third line displays the content of variable B on the terminal/console.
Step 2: Execute the Apache Pig Script
To execute the pig script in HDFS mode, run the following command:
Command: pig /home/edureka/output.pig

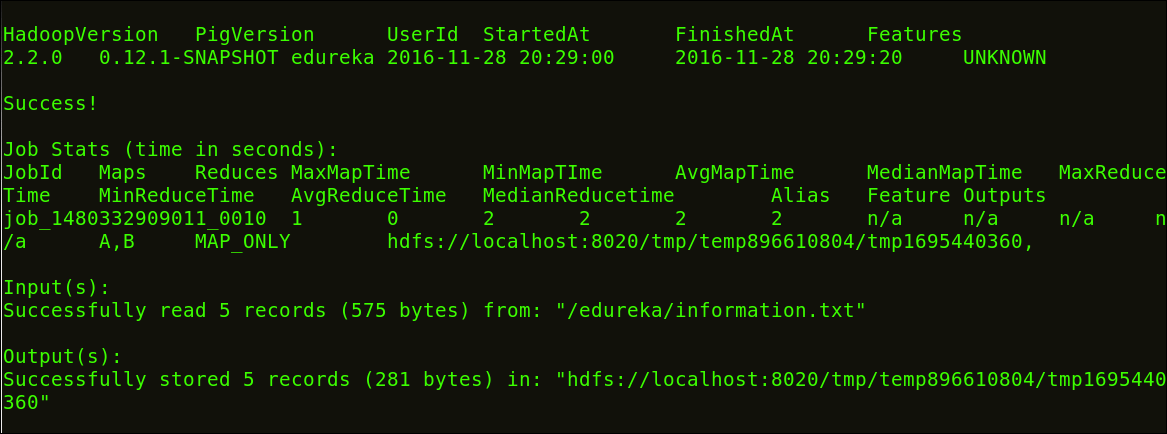
After the execution finishes, review the result. These below images show the results and their intermediate map and reduce functions.
Below image shows that the Script executed successfully.
Below image shows the result of our script.
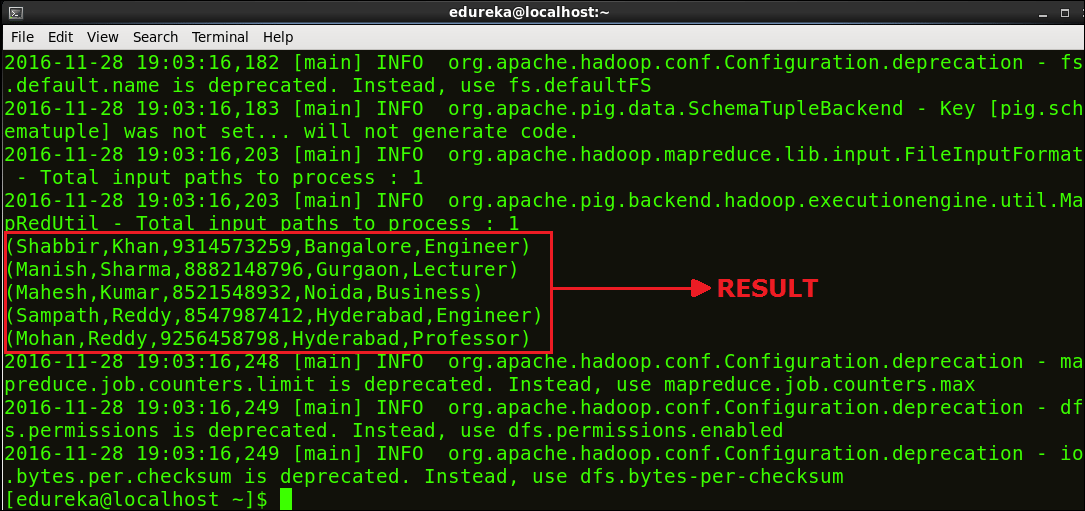
Congratulations on executing your first Apache Pig script successfully!
Now you know, how to create and execute Apache Pig script. Hence, our next blog in Hadoop Tutorial Series will be covering how to create UDF (User Defined Functions) in Apache Pig and execute it in MapReduce/HDFS mode.
Now that you have created and executed Apache Pig Script, check out the Hadoop training by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. The Edureka Big Data Hadoop Certification Training course helps learners become expert in HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume and Sqoop using real-time use cases on Retail, Social Media, Aviation, Tourism, Finance domain.
Got a question for us? Please mention it in the comments section and we will get back to you.








































Hi,
The second variable B is loaded with only the required data which does not include the LName and city. But the results highlighted shows all the fields.
Good example. Its helped me a lot