
Advanced Certification in Agentic AI Engineer ...
- 68k Enrolled Learners
- Weekend
- Live Class
(45931)





 Copy Link!
Copy Link!As you know a perceptron serves as a basic building block for creating a deep neural network therefore, it is quite obvious that we should begin our journey of mastering Deep Learning with perceptron and learn how to implement it using TensorFlow to solve different problems. In case you are completely new to deep learning, I would suggest you to go through the previous blog of this Deep Learning Tutorial series to avoid any confusion. Following are the topics that will be covered in this blog on Perceptron Learning Algorithm:
One can categorize all kinds of classification problems that can be solved using neural networks into two broad categories:
Basically, a problem is said to be linearly separable if you can classify the data set into two categories or classes using a single line. For example, separating cats from a group of cats and dogs. On the contrary, in case of a non-linearly separable problems, the data set contains multiple classes and requires non-linear line for separating them into their respective classes. For example, classification of handwritten digits. Let us visualize the difference between the two by plotting the graph of a linearly separable problem and non-linearly problem data set: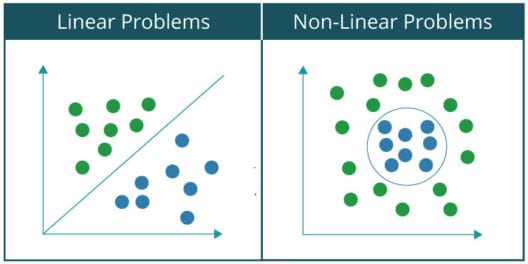 Since, you all are familiar with AND Gates, I will be using it as an example to explain how a perceptron works as a linear classifier.
Since, you all are familiar with AND Gates, I will be using it as an example to explain how a perceptron works as a linear classifier.
Note: As you move onto much more complex problems such as Image Recognition, which I covered briefly in the previous blog, the relationship in the data that you want to capture becomes highly non-linear and therefore, requires a network which consists of multiple artificial neurons, called as artificial neural network.
As you know that AND gate produces an output as 1 if both the inputs are 1 and 0 in all other cases. Therefore, a perceptron can be used as a separator or a decision line that divides the input set of AND Gate, into two classes:
The below diagram shows the above idea of classifying the inputs of AND Gate using a perceptron:
Till now, you understood that a linear perceptron can be used to classify the input data set into two classes. But, how does it actually classify the data?
Mathematically, one can represent a perceptron as a function of weights, inputs and bias (vertical offset):
Enough of the theory, let us look at the first example of this blog on Perceptron Learning Algorithm where I will implement AND Gate using a perceptron from scratch.
I will begin with importing all the required libraries. In this case, I need to import one library only i.e. TensorFlow:
#import required library import tensorflow as tf
Now, I will create variables for storing the input, output and bias for my perceptron:
#input1, input2 and bias
train_in = [
[1., 1.,1],
[1., 0,1],
[0, 1.,1],
[0, 0,1]]
#output
train_out = [
[1.],
[0],
[0],
[0]]
3. Define Weight Variable
Now, I need to define the weight variable and assign some random values to it initially. Since, I have three inputs over here (input 1, input 2 & bias), I will require 3 weight values for each input. So, I will define a tensor variable of shape 3×1 for our weights that will be initialized with random values:
#weight variable initialized with random values using random_normal() w = tf.Variable(tf.random_normal([3, 1], seed=12))
Note: In TensorFlow, variables are the only way to handle the ever changing neural network weights that are updated with the learning process.
In TensorFlow, you can specify placeholders that can accept external inputs on the run. So, I will define two placeholders – x for input and y for output. Later on, you will understand how to feed inputs to a placeholder.
#Placeholder for input and output x = tf.placeholder(tf.float32,[None,3]) y = tf.placeholder(tf.float32,[None,1])
As discussed earlier, the input received by a perceptron is first multiplied by the respective weights and then, all these weighted inputs are summed together. This summed value is then fed to activation for obtaining the final result as shown in the image below followed by the the code:
#calculate output output = tf.nn.relu(tf.matmul(x, w))
Note: In this case I have used relu as my activation function. Other important activation functions will be introduced as you proceed further in this blog on Perceptron Neural Network.
Now, I need to calculate the error value w.r.t perceptron output and the desired output. Generally, this error is calculated as Mean Squared Error which is nothing but the square of difference of perceptron output and desired output as shown below:
#Mean Squared Loss or Error loss = tf.reduce_sum(tf.square(output - y))
TensorFlow provides optimizers that slowly change each variable (weight and bias) in order to minimize the loss in successive iterations. The simplest optimizer is gradient descent which I will be using in this case.
#Minimize loss using GradientDescentOptimizer with a learning rate of 0.01 optimizer = tf.train.GradientDescentOptimizer(0.01) train = optimizer.minimize(loss)
Variables are not initialized when you call tf.Variable. So, I need to explicitly initialize all the variables in a TensorFlow program using the following code:
#Initialize all the global variables init = tf.global_variables_initializer() sess = tf.Session() sess.run(init)
9. Training Perceptron in Iterations
Now, I need to train our perceptron i.e. update values of weights and bias in successive iteration to minimize the error or loss. Here, I will train our perceptron in 1000 epochs.
#Compute output and cost w.r.t to input vector
sess.run(train, {x:train_in,y:train_out})
cost = sess.run(loss,feed_dict={x:train_in,y:train_out})
print('Epoch--',i,'--loss--',cost)
In the above code, you can observe how I am feeding train_in (input set of AND Gate) and train_out (output set of AND gate) to placeholders x and y respectively using feed_dict for calculating the cost or error.
Following is the final output obtained after my perceptron model has been trained:

Activation Functions
As discussed earlier, the activation function is applied to the output of a perceptron as shown in the image below:
In the previous example, I have shown you how to use a linear perceptron with relu activation function for performing linear classification on the input set of AND Gate. But, what if the classification that you wish to perform is non-linear in nature. In that case, you will be using one of the non-linear activation functions. Some of the prominent non-linear activation functions have been shown below:
TensorFlow library provides built-in functions for applying activation functions. The built-in functions w.r.t. above stated activation functions are listed below:
So far, you have learned how a perceptron works and how you can program it using TensorFlow. So, it’s time to move ahead and apply our understanding of a perceptron to solve an interesting use case on SONAR Data Classification.
In this use case, I have been provided with a SONAR data set which contains the data about 208 patterns obtained by bouncing sonar signals off a metal cylinder (naval mine) and a rock at various angles and under various conditions. Now, as you know, a naval mine is a self-contained explosive device placed in water to damage or destroy surface ships or submarines. So, our goal is to build a model that can predict whether the object is a naval mine or rock based on our data set. 
Now, let us have a look at our SONAR data set:

Here, the overall fundamental procedure will be same as that of AND gate with few difference which will be discussed to avoid any confusion. Let me provide you a walk-through of all the steps to perform linear classification on SONAR data set using Single Layer Perceptron:

Now that you have a good idea about all the steps involved in this use case, let us go ahead and program the model using TensorFlow:
At first, I will begin with all the required libraries as listed below:
In the previous example, I defined the input and the output variable w.r.t. AND Gate and explicitly assigned the required values to it. But, in real-life use cases like SONAR, you will be provided with the raw data set which you need to read and pre-process so that you can train your model around it.
#Read the sonar dataset
df = pd.read_csv("sonar.csv")
print(len(df.columns))
X = df[df.columns[0:60]].values
y = df[df.columns[60]]
#encode the dependent variable as it has two categorical values
encoder = LabelEncoder()
encoder.fit(y)
y = encoder.transform(y)
Y = one_hot_encode(y)
One Hot Encoder adds extra columns based on number of labels present in the column. In this case, I have two labels 0 and 1 (for Rock and Mine). Therefore, two extra columns will be added corresponding to each categorical value as shown in the image below:
#function for applying one_hot_encoder def one_hot_encode(labels): n_labels = len(labels) n_unique_labels = len(np.unique(labels)) one_hot_encode = np.zeros((n_labels,n_unique_labels)) one_hot_encode[np.arange(n_labels), labels] = 1 return one_hot_encode
While working on any deep learning project, you need to divide your data set into two parts where one of the parts is used for training your deep learning model and the other is used for validating the model once it has been trained. Therefore, in this step I will also divide the data set into two subsets:
I will be use train_test_split() function from the sklearn library for dividing the dataset:
#Divide the data in training and test subset X,Y = shuffle(X,Y,random_state=1) train_x,test_x,train_y,test_y = train_test_split(X,Y,test_size=0.20, random_state=42)
Here, I will be define variables for following entities:
Apart from variable, I will also need placeholders that can take input. So, I will create place holder for my input and feed it with the data set later on. At last, I will call global_variable_initializer() to initialize all the variables.
#define all the variables to work with the tensors learning_rate = 0.1 training_epochs = 1000 cost_history = np.empty(shape=[1],dtype=float) n_dim = X.shape[1] n_class = 2 x = tf.placeholder(tf.float32,[None,n_dim]) W = tf.Variable(tf.zeros([n_dim,n_class])) b = tf.Variable(tf.zeros([n_class])
Similar to AND Gate implementation, I will calculate the cost or error produced by our model. Instead of Mean Squared Error, I will use cross entropy to calculate the error in this case.
y_ = tf.placeholder(tf.float32,[None,n_class]) y = tf.nn.softmax(tf.matmul(x, W)+ b) cost_function = tf.reduce_mean(-tf.reduce_sum((y_ * tf.log(y)),reduction_indices=[1])) training_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost_function)
Now, I will train my model in successive epochs. In each of the epochs, the cost is calculated and then, based on this cost the optimizer modifies the weight and bias variables in order to minimize the error.
#Minimizing the cost for each epoch
for epoch in range(training_epochs):
sess.run(training_step,feed_dict={x:train_x,y_:train_y})
cost = sess.run(cost_function,feed_dict={x: train_x,y_: train_y})
cost_history = np.append(cost_history,cost)
print('epoch : ', epoch, ' - ', 'cost: ', cost)
As discussed earlier, the accuracy of a trained model is calculated based on Test Subset. Therefore, at first, I will feed the test subset to my model and get the output (labels). Then, I will compare the output obtained from the model with that of the actual or desired output and finally, will calculate the accuracy as percentage of correct predictions out of total predictions made on test subset.
#Run the trained model on test subset
pred_y = sess.run(y, feed_dict={x: test_x})
#calculate the correct predictions
correct_prediction = tf.equal(tf.argmax(pred_y,1), tf.argmax(test_y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print("Accuracy: ",sess.run(accuracy))
Following is the output that you will get once the training has been completed:

As you can see, we got an accuracy of 83.34% which is descent enough. Now, let us observe how the cost or error has been reduced in successive epochs by plotting a graph of Cost vs No. of Epochs: Complete Code for SONAR Data Classification Using Single Layer Perceptron
Complete Code for SONAR Data Classification Using Single Layer Perceptron
#import the required libraries
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
#define the one hot encode function
def one_hot_encode(labels):
n_labels = len(labels)
n_unique_labels = len(np.unique(labels))
one_hot_encode = np.zeros((n_labels,n_unique_labels))
one_hot_encode[np.arange(n_labels), labels] = 1
return one_hot_encode
#Read the sonar dataset
df = pd.read_csv("sonar.csv")
print(len(df.columns))
X = df[df.columns[0:60]].values
y=df[df.columns[60]]
#encode the dependent variable containing categorical values
encoder = LabelEncoder()
encoder.fit(y)
y = encoder.transform(y)
Y = one_hot_encode(y)
#Transform the data in training and testing
X,Y = shuffle(X,Y,random_state=1)
train_x,test_x,train_y,test_y = train_test_split(X,Y,test_size=0.20, random_state=42)
#define and initialize the variables to work with the tensors
learning_rate = 0.1
training_epochs = 1000
#Array to store cost obtained in each epoch
cost_history = np.empty(shape=[1],dtype=float)
n_dim = X.shape[1]
n_class = 2
x = tf.placeholder(tf.float32,[None,n_dim])
W = tf.Variable(tf.zeros([n_dim,n_class]))
b = tf.Variable(tf.zeros([n_class]))
#initialize all variables.
init = tf.global_variables_initializer()
#define the cost function
y_ = tf.placeholder(tf.float32,[None,n_class])
y = tf.nn.softmax(tf.matmul(x, W)+ b)
cost_function = tf.reduce_mean(-tf.reduce_sum((y_ * tf.log(y)),reduction_indices=[1]))
training_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost_function)
#initialize the session
sess = tf.Session()
sess.run(init)
mse_history = []
#calculate the cost for each epoch
for epoch in range(training_epochs):
sess.run(training_step,feed_dict={x:train_x,y_:train_y})
cost = sess.run(cost_function,feed_dict={x: train_x,y_: train_y})
cost_history = np.append(cost_history,cost)
print('epoch : ', epoch, ' - ', 'cost: ', cost)
pred_y = sess.run(y, feed_dict={x: test_x})
#Calculate Accuracy
correct_prediction = tf.equal(tf.argmax(pred_y,1), tf.argmax(test_y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print("Accuracy: ",sess.run(accuracy))
plt.plot(range(len(cost_history)),cost_history)
plt.axis([0,training_epochs,0,np.max(cost_history)])
plt.show()
In this blog on Perceptron Learning Algorithm, you learned what is a perceptron and how to implement it using TensorFlow library. You also understood how a perceptron can be used as a linear classifier and I demonstrated how to we can use this fact to implement AND Gate using a perceptron. At last, I took a one step ahead and applied perceptron to solve a real time use case where I classified SONAR data set to detect the difference between Rock and Mine. Now, in the next blog I will talk about limitations of a single layer perceptron and how you can form a multi-layer perceptron or a neural network to deal with more complex problems. There, you will also learn about how to build a multi-layer neural network using TensorFlow from scratch.
I hope you have enjoyed reading this post, I would recommend you to kindly have a look at the below blogs as well:
Check out this NLP Course by Edureka to upgrade your AI skills to the next level The Edureka Deep Learning with TensorFlow Certification Training course helps learners become expert in training and optimizing basic and convolutional neural networks using real time projects and assignments along with concepts such as SoftMax function, Auto-encoder Neural Networks, Restricted Boltzmann Machine (RBM).
Got a question for us? Please mention it in the comments section and we will get back to you.













 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP



