





This post is about the operators in Apache Pig. Apache Pig also enables you to write complex data transformations without the knowledge of Java, making it really important for the Big Data Hadoop Certification projects. Let’s take a quick look at what Pig and Pig Latin is and the different modes in which they can be operated, before heading on to Operators.
What is Apache Pig?
Apache Pig is a high-level procedural language for querying large data sets using Hadoop and the Map Reduce Platform. It is a Java package, where the scripts can be executed from any language implementation running on the JVM. This is greatly used in iterative processes.
Apache Pig simplifies the use of Hadoop by allowing SQL-like queries to a distributed dataset and makes it possible to create complex tasks to process large volumes of data quickly and effectively. The best feature of Pig is that, it backs many relational features like Join, Group and Aggregate.
I know Pig sounds a lot more like an ETL tool and it does have many features common with ETL tools. But the advantage of Pig over ETL tools is that it can run on many servers simultaneously.
What is Apache Pig Latin?
Apache Pig create a simpler procedural language abstraction over Map Reduce to expose a more Structured Query Language (SQL)-like interface for Hadoop applications called Apache Pig Latin, So instead of writing a separate Map Reduce application, you can write a single script in Apache Pig Latin that is automatically parallelized and distributed across a cluster. In simple words, Pig Latin, is a sequence of simple statements taking an input and producing an output. The input and output data are composed of bags, maps, tuples and scalar. Learn more about Big Data and its applications from the Azure Data Engineering Course in Hyderabad.
Apache Pig Execution Modes:
Apache Pig has two execution modes:
Local Mode
In ‘Local Mode’, the source data would be picked from the local directory in your computer system. The MapReduce mode can be specified using ‘pig –x local’ command.

MapReduce Mode:
To run Pig in MapReduce mode, you need access to Hadoop cluster and HDFS installation. The MapReduce mode can be specified using the ‘pig’ command.

Apache Pig Operators:
Apache Pig Operators is a high-level procedural language for querying large data sets using Hadoop and the Map Reduce Platform. A Pig Latin statement is an operator that takes a relation as input and produces another relation as output. These operators are the main tools Pig Latin provides to operate on the data. They allow you to transform it by sorting, grouping, joining, projecting, and filtering. You can get a better understanding of the Azure Data Engineering certification.
Let’s create two files to run the commands:
We have two files with name ‘first’ and ‘second.’ The first file contains three fields: user, url & id.

The second file contain two fields: url & rating. These two files are CSV files.

The Apache Pig operators can be classified as: Relational and Diagnostic.
Relational Operators:
Relational operators are the main tools Pig Latin provides to operate on the data. It allows you to transform the data by sorting, grouping, joining, projecting and filtering. This section covers the basic relational operators.
LOAD:
LOAD operator is used to load data from the file system or HDFS storage into a Pig relation.
In this example, the Load operator loads data from file ‘first’ to form relation ‘loading1’. The field names are user, url, id.
![]()
![]()
FOREACH:
This operator generates data transformations based on columns of data. It is used to add or remove fields from a relation. Use FOREACH-GENERATE operation to work with columns of data.
![]()
FOREACH Result:

FILTER:
This operator selects tuples from a relation based on a condition.
In this example, we are filtering the record from ‘loading1’ when the condition ‘id’ is greater than 8.
![]()
FILTER Result:

JOIN:
JOIN operator is used to perform an inner, equijoin join of two or more relations based on common field values. The JOIN operator always performs an inner join. Inner joins ignore null keys, so it makes sense to filter them out before the join.
In this example, join the two relations based on the column ‘url’ from ‘loading1’ and ‘loading2’.
![]()
JOIN Result:

ORDER BY:
Order By is used to sort a relation based on one or more fields. You can do sorting in ascending or descending order using ASC and DESC keywords.
In below example, we are sorting data in loading2 in ascending order on ratings field.
![]()
ORDER BY Result:

DISTINCT:
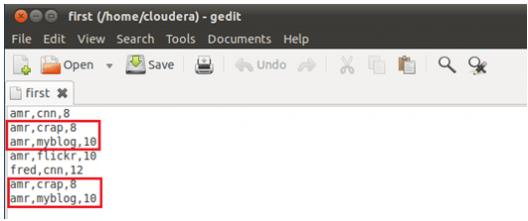
Distinct removes duplicate tuples in a relation.Lets take an input file as below, which has amr,crap,8 and amr,myblog,10 twice in the file. When we apply distinct on the data in this file, duplicate entries are removed.
![]()
DISTINCT Result:

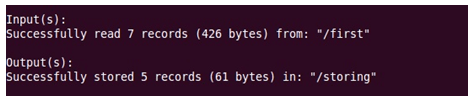
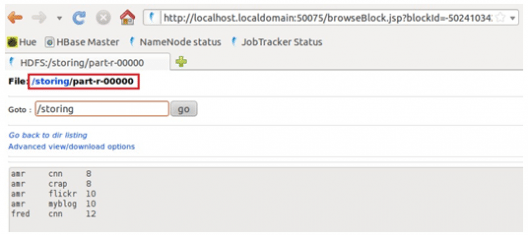
STORE:
Store is used to save results to the file system.
Here we are saving loading3 data into a file named storing on HDFS.
![]()
STORE Result:
GROUP:
The GROUP operator groups together the tuples with the same group key (key field). The key field will be a tuple if the group key has more than one field, otherwise it will be the same type as that of the group key. The result of a GROUP operation is a relation that includes one tuple per group.
In this example, group th
![]()
e relation ‘loading1’ by column url.
GROUP Result:

COGROUP:
COGROUP is same as GROUP operator. For readability, programmers usually use GROUP when only one relation is involved and COGROUP when multiple relations re involved.
In this example group the ‘loading1’ and ‘loading2’ by url field in both relations.
![]()
COGROUP Result:

CROSS:
The CROSS operator is used to compute the cross product (Cartesian product) of two or more relations.
Applying cross product on loading1 and loading2.
![]()
CROSS Result:

LIMIT:
LIMIT operator is used to limit the number of output tuples. If the specified number of output tuples is equal to or exceeds the number of tuples in the relation, the output will include all tuples in the relation.
![]()
LIMIT Result:

SPLIT:
SPLIT operator is used to partition the contents of a relation into two or more relations based on some expression. Depending on the conditions stated in the expression.
Split the loading2 into two relations x and y. x relation created by loading2 contain the fields that the rating is greater than 8 and y relation contain fields that rating is less than or equal to 8.
![]()


Got a question for us? Please mention them in the comments section and we will get back to you.
Related Posts:
Operators in Apache Pig – Diagnostic Operators





































What should be the laptop configuration(RAM capacity) for installing hadoop and its ecosystem tools.???
Hey Sudip, having 8GB of RAM would be the minimum requirement. However to run it properly, you will need to have 16GB of processing power in your system. Cheers :)
Apache Pig language is quiet technical
I am trying to search, how many relation I have created till now..Is there command ?
Within the Apache Pig Execution Modes section in the local mode it is mentioned that The MapReduce mode can be specified using ‘pig –x local’ command. Should it be Local mode can be specified using ‘pig –x local’ command.
How do we achieve the functionality of left or right joins using pig?
Well I got the answer by myself….Details of joins is available at
Hi Nice bog, but if you will add UDF also it will be a very good place to come back again and again for revision.
Thanks Sushobhit!! You read about UDF here: https://www.edureka.co/blog/apache-pig-udf-store-functions/
Thanks :)
For completeness, would like example of DISTINCT, ORDER and STORE as well
Hi Swagata thanks for visiting. We have updated the blog with the requested information.
Please add Flatten as well…
Good one