


SQL Essentials Training
- 13k Enrolled Learners
- Weekend/Weekday
- Self Paced
(4800)





 Copy Link!
Copy Link!_1648288684.jpg)
Data in Database is stored in terms of enormous quantity. Retrieving certain data will be a tedious task if the data is not organized correctly. With the help of Normalization, we can organize this data and also reduce the redundant data. Through the medium of this article, I will give you a complete insight of Normalization in SQL. You can even check out the details of relational databases, functions, queries, variables, etc with the SQL Server Training.
What is Normalization in a Database?
It is the processes of reducing the redundancy of data in the table and also improving the data integrity. So why is this required? without Normalization in SQL, we may face many issues such as
In brief, normalization is a way of organizing the data in the database. Normalization entails organizing the columns and tables of a database to ensure that their dependencies are properly enforced by database integrity constraints.
It usually divides a large table into smaller ones, so it is more efficient. In 1970 the First Normal Form was defined by Edgar F Codd and eventually, other Normal Forms were defined.
One question that arises in between is, what does SQL have to do with Normalization. Well SQL is the language that is used to interact with the database. To initiate any interaction, the data present in the database has to be of Normalized Form. Else we cannot proceed further as it results in anomalies.
Normalization in SQL will enhance the distribution of data. Now let’s understand each and every Normal Form with examples.
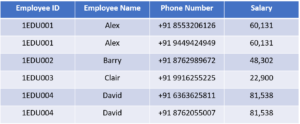
In this Normal Form, we tackle the problem of atomicity. Here atomicity means values in the table should not be further divided. In simple terms, a single cell cannot hold multiple values. If a table contains a composite or multi-valued attribute, it violates the First Normal Form.
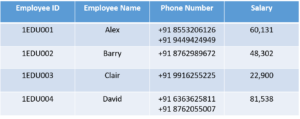
In the above table, we can clearly see that the Phone Number column has two values. Thus it violated the 1st NF. Now if we apply the 1st NF to the above table we get the below table as the result.
By this, we have achieved atomicity and also each and every column have unique values.
The first condition in the 2nd NF is that the table has to be in 1st NF. The table also should not contain partial dependency. Here partial dependency means the proper subset of candidate keys determines a non-prime attribute. To understand in a better way lets look at the below example.
Consider the table
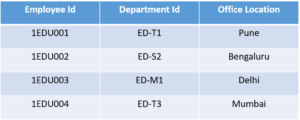
This table has a composite primary key Emplyoee ID, Department ID. The non-key attribute is Office Location. In this case, Office Location only depends on Department ID, which is only part of the primary key. Therefore, this table does not satisfy the second Normal Form.
To bring this table to Second Normal Form, we need to break the table into two parts. Which will give us the below tables:
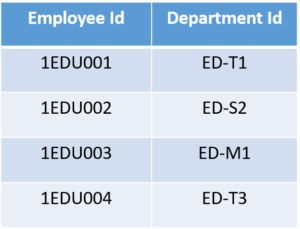
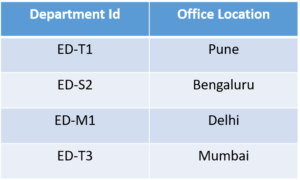
As you can see we have removed the partial functional dependency that we initially had. Now, in the table, the column Office Location is fully dependent on the primary key of that table, which is Department ID.
Now that we have learnt 1st and 2nd normal forms lets head to the next part of this Normalization in SQL article.
The same rule applies as before i.e, the table has to be in 2NF before proceeding to 3NF. The other condition is there should be no transitive dependency for non-prime attributes. That means non-prime attributes (which doesn’t form a candidate key) should not be dependent on other non-prime attributes in a given table. So a transitive dependency is a functional dependency in which X → Z (X determines Z) indirectly, by virtue of X → Y and Y → Z (where it is not the case that Y → X)
Let’s understand this more clearly with the help of an example:
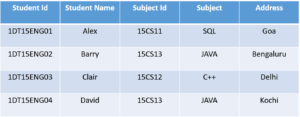
In the above table, Student ID determines Subject ID, and Subject ID determines Subject. Therefore, Student ID determines Subject via Subject ID. This implies that we have a transitive functional dependency, and this structure does not satisfy the third normal form.
Now in order to achieve third normal form, we need to divide the table as shown below:
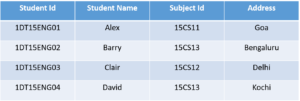
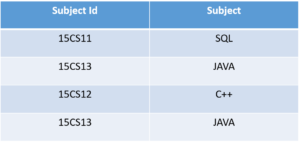
As you can see from the above tables all the non-key attributes are now fully functional dependent only on the primary key. In the first table, columns Student Name, Subject ID and Address are only dependent on Student ID. In the second table, Subject is only dependent on Subject ID.
This is also known as 3.5 NF. Its the higher version 3NF and was developed by Raymond F. Boyce and Edgar F. Codd to address certain types of anomalies which were not dealt with 3NF.
Before proceeding to BCNF the table has to satisfy 3rd Normal Form.
In BCNF if every functional dependency A → B, then A has to be the Super Key of that particular table.
Consider the below table:
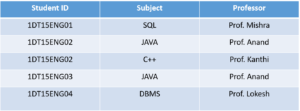
In this table, all the normal forms are satisfied except BCNF. Why?
As you can see Student ID, and Subject form the primary key, which means the Subject column is a prime attribute. But, there is one more dependency, Professor → Subject.
And while Subject is a prime attribute, Professor is a non-prime attribute, which is not allowed by BCNF.
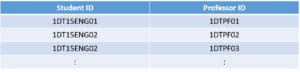
Now in order to satisfy the BCNF, we will be dividing the table into two parts. One table will hold Student ID which already exists and newly created column Professor ID.
And in the second table, we will have the columns Professor ID, Professor and Subject.
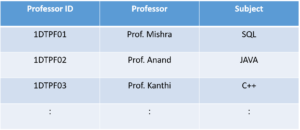
By doing this we are satisfied the Boyce Codd Normal Form.
Thus this brings us to the end of Normalization in SQL article. I hope now you have a clear idea about Normalization concepts.
If you wish to learn more about MySQL and get to know this open-source relational database, then check out our MySQL DBA Certification Training which comes with instructor-led live training and real-life project experience. This training will help you understand MySQL in-depth and help you achieve mastery over the subject.



















 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP