
Advanced Certification in Agentic AI Engineer ...
- 66k Enrolled Learners
- Weekend
- Live Class
(45931)





 Copy Link!
Copy Link!In the previous blog you read about single artificial neuron called Perceptron. In this Neural Network tutorial we will take a step forward and will discuss about the network of Perceptrons called Multi-Layer Perceptron (Artificial Neural Network).
We will be discussing the following topics in this Neural Network tutorial:
This blog on Neural Network tutorial will include a use-case in the end. For implementing that use-case, we will be using TensorFlow.
Now, I will start by discussing what are the limitations of Single-Layer Perceptron.
Well, there are two major problems:
Let us understand this by taking an example of XOR gate. Consider the diagram below:
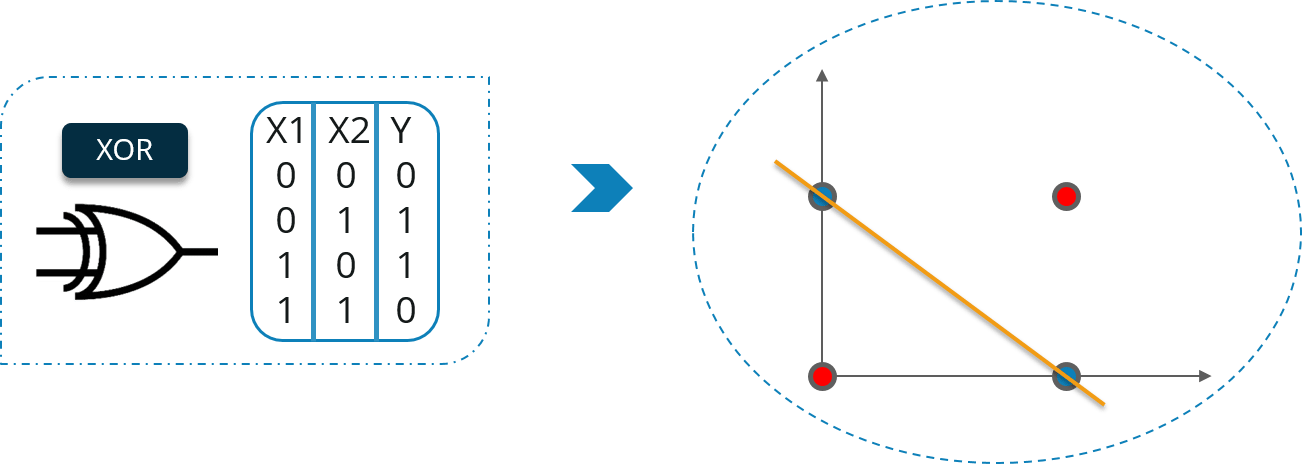
Here, you cannot separate the high and low points with a single straight line. But, we can separate it by two straight lines. Consider the diagram below:

Here also, I will explain with an example.
As an E-commerce firm, you have noticed a decline in your sales. Now, you try to form a marketing team who would market the products for increasing the sales.
The marketing team can market your product through various ways, such as:
Considering all the factors and options available, marketing team has to decide a strategy to do optimal and efficient marketing, but this task is too complex for a human to analyse, because number of parameters are quite high. This problem will have to be solved using Deep Learning. Consider the diagram below:
 They can either use just one means to market their products or use a variety of them.
They can either use just one means to market their products or use a variety of them.
Each way would have different advantages and disadvantages as well, they will have to focus on a variety of factors and options such as:
 Number of sales that would happen would be dependent on different categorical inputs, their sub categories and their parameters. However, computing and calculating from so many inputs and their sub parameters is not possible just through one neuron (Perceptron).
Number of sales that would happen would be dependent on different categorical inputs, their sub categories and their parameters. However, computing and calculating from so many inputs and their sub parameters is not possible just through one neuron (Perceptron).
That is why more than one neuron would be used to solve this problem. Consider the diagram below:

Because of all these reasons, Single-Layer Perceptron cannot be used for complex non-linear problems.
Next up, in this Neural Network tutorial I will focus on Multi-Layer Perceptrons (MLP).
As you know our brain is made up of millions of neurons, so a Neural Network is really just a composition of Perceptrons, connected in different ways and operating on different activation functions.
Consider the diagram below:

Yeah, you guessed it right, I will take an example to explain – how an Artificial Neural Network works.
Suppose we have data of a football team, Chelsea. The data contains three columns. The last column tells whether Chelsea won the match or they lost it. The other two columns are about, goal lead in the first half and possession in the second half. Possession is the amount of time for which the team has the ball in percentage. So, if I say that a team has 50% possession in one half (45 minutes), it means that, the team had ball for 22.5 minutes out of 45 minutes.
| Goal Lead in First Half | Possession in Second Half | Won or Lost (1,0)? |
| 0 | 80% | 1 |
| 0 | 35% | 0 |
| 1 | 42% | 1 |
| 2 | 20% | 0 |
| -1 | 75% | 1 |
The Final Result column, can have two values 1 or 0 indicating whether Chelsea won the match or not. For example, we can see that if there is a 0 goal lead in the first half and in next half Chelsea has 80% possession, then Chelsea wins the match.
Now, suppose, we want to predict whether Chelsea will win the match or not, if the goal lead in the first half is 2 and the possession in the second half is 32%.
This is a binary classification problem where a multi layer Perceptron can learn from the given examples (training data) and make an informed prediction given a new data point. We will see below how a multi layer perceptron learns such relationships.
The process by which a Multi Layer Perceptron learns is called the Backpropagation algorithm, I would recommend you to go through the Backpropagation blog.
Consider the diagram below:

Here, we will propagate forward, i.e. calculate the weighted sum of the inputs and add bias. In the output layer we will use the softmax function to get the probabilities of Chelsea winning or loosing.
If you notice the diagram, winning probability is 0.4 and loosing probability is 0.6. But, according to our data, we know that when goal lead in the first half is 1 and possession in the second half is 42% Chelsea will win. Our network has made wrong prediction.
If we see the error (Comparing the network output with target), it is 0.6 and -0.6.
I would recommend you to refer the Backpropagation blog.
We calculate the total error at the output nodes and propagate these errors back through the network using Backpropagation to calculate the gradients. Then we use an optimization method such as Gradient Descent to ‘adjust’ all weights in the network with an aim of reducing the error at the output layer.
Let me explain you how the gradient descent optimizer works:
Step – 1: First we calculate the error, consider the equation below:
 Step – 2: Based on the error we got, it will calculate the rate of change of error w.r.t change in the weights.
Step – 2: Based on the error we got, it will calculate the rate of change of error w.r.t change in the weights.

Step – 3: Now, based on this change in weight, we will calculate the new weight value.
If we now input the same example to the network again, the network should perform better than before since the weights have now have been adjusted to minimize the error in prediction. Consider the example below, As shown in Figure, the errors at the output nodes now reduce to [0.2, -0.2] as compared to [0.6, -0.4] earlier. This means that our network has learnt to correctly classify our first training example.

We repeat this process with all other training examples in our dataset. Then, our network is said to have learnt those examples.
Now, I can feed in the input to our network. If I feed in goal lead in the first half as 2 and possession in the second half as 32%, our network will predict whether Chelsea will win that match or not.
Now in this Neural Network Tutorial, we will some have fun with hands-on. I will be using TensorFlow to model a Multi-Layer Neural Network.
Let’s look at our problem statement:

Now, let’s look at the dataset, which we will be using to train our network.

The first four columns are features and the last column is label.
Data were extracted from images that were taken from genuine and forged banknote-like specimens. The final images have 400×400 pixels. Due to the object lens and distance to the investigated object gray-scale, pictures with a resolution of about 660 dpi were gained. Wavelet Transform tool were used to extract features from images.
To implement this use-case, we will be using the below flow diagram:

Let’s execute it now:
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
# Reading the dataset
def read_dataset():
df = pd.read_csv("C:UsersSaurabhPycharmProjectsNeural Network Tutorialbanknote.csv")
# print(len(df.columns))
X = df[df.columns[0:4]].values
y = df[df.columns[4]]
# Encode the dependent variable
Y = one_hot_encode(y)
print(X.shape)
return (X, Y)
# Define the encoder function.
def one_hot_encode(labels):
n_labels = len(labels)
n_unique_labels = len(np.unique(labels))
one_hot_encode = np.zeros((n_labels, n_unique_labels))
one_hot_encode[np.arange(n_labels), labels] = 1
return one_hot_encode
# Read the dataset
X, Y = read_dataset()
# Shuffle the dataset to mix up the rows.
X, Y = shuffle(X, Y, random_state=1)
# Convert the dataset into train and test part
train_x, test_x, train_y, test_y = train_test_split(X, Y, test_size=0.20, random_state=415)
# Inpect the shape of the training and testing.
print(train_x.shape)
print(train_y.shape)
print(test_x.shape)
# Define the important parameters and variable to work with the tensors
learning_rate = 0.3
training_epochs = 100
cost_history = np.empty(shape=[1], dtype=float)
n_dim = X.shape[1]
print("n_dim", n_dim)
n_class = 2
model_path = "C:UsersSaurabhPycharmProjectsNeural Network TutorialBankNotes"
# Define the number of hidden layers and number of neurons for each layer
n_hidden_1 = 4
n_hidden_2 = 4
n_hidden_3 = 4
n_hidden_4 = 4
x = tf.placeholder(tf.float32, [None, n_dim])
W = tf.Variable(tf.zeros([n_dim, n_class]))
b = tf.Variable(tf.zeros([n_class]))
y_ = tf.placeholder(tf.float32, [None, n_class])
# Define the model
def multilayer_perceptron(x, weights, biases):
# Hidden layer with RELU activationsd
layer_1 = tf.add(tf.matmul(x, weights['h1']), biases['b1'])
layer_1 = tf.nn.relu(layer_1)
# Hidden layer with sigmoid activation
layer_2 = tf.add(tf.matmul(layer_1, weights['h2']), biases['b2'])
layer_2 = tf.nn.relu(layer_2)
# Hidden layer with sigmoid activation
layer_3 = tf.add(tf.matmul(layer_2, weights['h3']), biases['b3'])
layer_3 = tf.nn.relu(layer_3)
# Hidden layer with RELU activation
layer_4 = tf.add(tf.matmul(layer_3, weights['h4']), biases['b4'])
layer_4 = tf.nn.sigmoid(layer_4)
# Output layer with linear activation
out_layer = tf.matmul(layer_4, weights['out']) + biases['out']
return out_layer
# Define the weights and the biases for each layer
weights = {
'h1': tf.Variable(tf.truncated_normal([n_dim, n_hidden_1])),
'h2': tf.Variable(tf.truncated_normal([n_hidden_1, n_hidden_2])),
'h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_3])),
'h4': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_4])),
'out': tf.Variable(tf.truncated_normal([n_hidden_4, n_class]))
}
biases = {
'b1': tf.Variable(tf.truncated_normal([n_hidden_1])),
'b2': tf.Variable(tf.truncated_normal([n_hidden_2])),
'b3': tf.Variable(tf.truncated_normal([n_hidden_3])),
'b4': tf.Variable(tf.truncated_normal([n_hidden_4])),
'out': tf.Variable(tf.truncated_normal([n_class]))
}
# Initialize all the variables
init = tf.global_variables_initializer()
saver = tf.train.Saver()
# Call your model defined
y = multilayer_perceptron(x, weights, biases)
# Define the cost function and optimizer
cost_function = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=y_))
training_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost_function)
sess = tf.Session()
sess.run(init)
# Calculate the cost and the accuracy for each epoch
mse_history = []
accuracy_history = []
for epoch in range(training_epochs):
sess.run(training_step, feed_dict={x: train_x, y_: train_y})
cost = sess.run(cost_function, feed_dict={x: train_x, y_: train_y})
cost_history = np.append(cost_history, cost)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# print("Accuracy: ", (sess.run(accuracy, feed_dict={x: test_x, y_: test_y})))
pred_y = sess.run(y, feed_dict={x: test_x})
mse = tf.reduce_mean(tf.square(pred_y - test_y))
mse_ = sess.run(mse)
mse_history.append(mse_)
accuracy = (sess.run(accuracy, feed_dict={x: train_x, y_: train_y}))
accuracy_history.append(accuracy)
print('epoch : ', epoch, ' - ', 'cost: ', cost, " - MSE: ", mse_, "- Train Accuracy: ", accuracy)
save_path = saver.save(sess, model_path)
print("Model saved in file: %s" % save_path)
#Plot Accuracy Graph
plt.plot(accuracy_history)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.show()
# Print the final accuracy
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print("Test Accuracy: ", (sess.run(accuracy, feed_dict={x: test_x, y_: test_y})))
# Print the final mean square error
pred_y = sess.run(y, feed_dict={x: test_x})
mse = tf.reduce_mean(tf.square(pred_y - test_y))
print("MSE: %.4f" % sess.run(mse))
Once you run this code you will get the below output:

You can notice the final accuracy is 99.6364% and mean squared error is 2.2198. We can actually make it better by increasing the number of epochs.
Below is the graph of epoch vs accuracy:

You can see that, after every iteration, the accuracy is increasing.
I hope you have enjoyed reading this Neural Network Tutorial. Check out other blogs in the series:
After this Neural Network tutorial, soon I will be coming up with separate blogs on different types of Neural Networks – Convolutional Neural Network and Recurrent Neural Network.
Check out the Deep Learning with TensorFlow Training by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. The Edureka Deep Learning with TensorFlow Certification Training course helps learners become expert in training and optimizing basic and convolutional neural networks using real time projects and assignments along with concepts such as SoftMax function, Auto-encoder Neural Networks, Restricted Boltzmann Machine (RBM).
Got a question for us? Please mention it in the comments section and we will get back to you.
















 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP



Is there anyway to have the testing code?