



Agentic AI Certification Training Course
- 132k Enrolled Learners
- Weekend/Weekday
- Live Class
(63442)





 Copy Link!
Copy Link!Imagine entering a control room with complete control over your data ecosystem. You won’t have to deal with siloed systems, jump between tools, or write endless lines of code to make data useful. That’s how Microsoft Fabric works.
With its ability to seamlessly integrate data engineering, analytics, and business intelligence, Microsoft Fabric stands out as the all-in-one superhero in a world where data is abundant but insights are scarce. This is your approachable, non-technical road map, regardless of whether you’re a Power BI user ready to upgrade, an inquisitive novice, or someone who has heard of “Fabric” but believes it has to do with clothing.
Still doubtful? Imagine this: Mr. Rahul, the owner of a supermarket, used to have trouble managing sales reports, Excel sheets, and customer data that was dispersed throughout several systems. He now uses Microsoft Fabric to easily transform daily sales data from all his stores and obtain real-time dashboards that enable him to make decisions on pricing, promotions, and inventory in real time, all from a single platform.
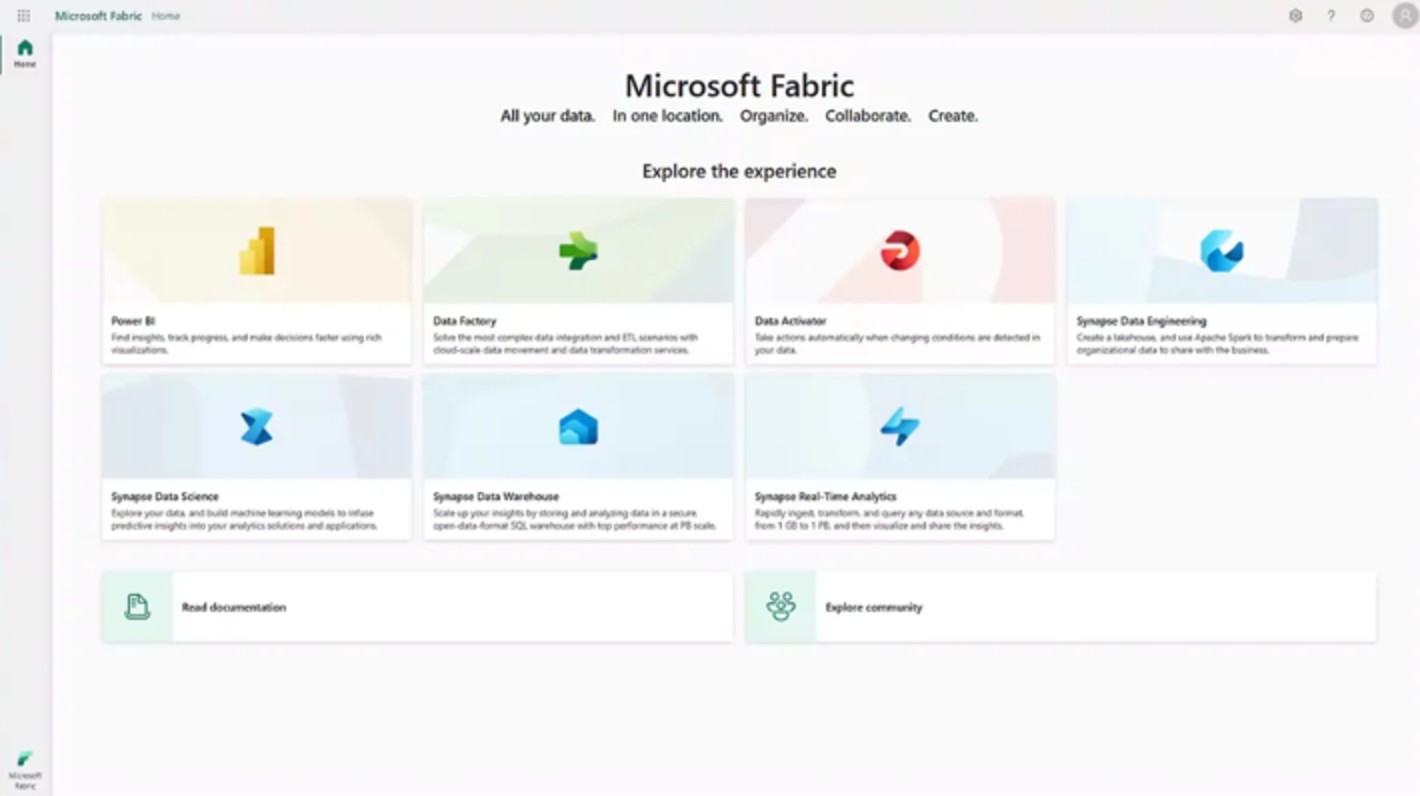
Let’s dissect it in detail and see if you can follow suit.
Welcome to Microsoft Fabric for Complete Novices, where no prior knowledge of coding or confusion is necessary.
It is a comprehensive analytics solution that integrates business intelligence, real-time analytics, data science, data engineering, data integration, and data warehousing. A single SaaS platform is intended to streamline processes and encourage cooperation among various roles, including data engineers, analysts, and business users.
Now that you understand what Microsoft Fabric is, let’s see make a career out of data engineering
Becoming a data engineer doesn’t require you to be an expert in coding or have experience with software development, especially with Microsoft Fabric. For both novices and seasoned experts, it is intended to make the data engineering approachable, simple, and cooperative.
The job of a data engineer is to gather, process, and arrange data so that it can be used for analysis and decision-making. Using robust yet approachable tools like Dataflows Gen2, Lakehouses, Pipelines, and Notebooks, you can accomplish this in Microsoft Fabric. These elements enable you to automate processes in a completely integrated setting, clean data using low-code or no-code solutions, and ingest data.
With its built-in best practices and guided interfaces, it simplifies the learning curve. Connecting data sources and constructing transformation steps are good places to start, and you can progress to more complex tasks like pipeline orchestration or the creation of reusable data models. Without the complexity of conventional systems, it’s the ideal platform for developing contemporary data engineering skills.
After that, we’ll set up Microsoft Fabric.
Admins must go to Microsoft 365 Admin Center → Fabric Settings.
Enable Microsoft Fabric preview for the organization.
Options:
Trial (free with limitations)
Pro
Go to Admin Portal → Capacity settings to allocate and monitor resources.
Choose your OneLake storage region for data locality and compliance.
 Exploring the Microsoft Fabric Interface
Exploring the Microsoft Fabric InterfaceThe Microsoft Fabric user interface is neat and cohesive. You will observe:
Comprehending Workspaces
Teams can manage all of their Fabric artifacts, including dataflows, notebooks, lakehouses, semantic models, and reports, in collaborative workspaces. Roles like Admin, Member, or Viewer can be assigned based on the situation.
Next, we’ll discuss creating data pipelines and ingesting data into the platform.
Entering data into Microsoft. The first and most important step in creating powerful analytics solutions is Fabric. Whether your data comes from files, databases, cloud services, or streaming sources, Fabric’s broad range of support makes it simple to aggregate it all in one location.
Dataflows Gen2 is a robust, low-code method for extracting, transforming, and loading (ETL) data that can be used with Microsoft Fabric. Dataflows make connecting to common sources such as SQL Server, Excel files, SharePoint lists, and REST APIs possible. Then, using well-known Power Query tools, you can clean and shape the data.
For more complex situations, Notebooks give you the ability to run code in a flexible, programmable environment to ingest, transform, and explore data using languages like Python, SQL, or Spark. Because of this, Fabric is perfect for both technical users who desire complete control and no-code users.
Your data is stored safely, conveniently, and prepared for additional processing or analysis once it has been ingested and placed in Fabric’s centralized data lake, the OneLake storage layer.
Any contemporary data platform would be incomplete without data pipelines, which automate the transfer, integration, and transformation of data from unstructured sources into insightful knowledge. Building these pipelines is made easier by user-friendly tools, which are suitable for both novice and seasoned data engineers.
Multi-step workflows that link multiple data sources, perform transformations, and load the cleaned data into Lakehouses or Warehouses for analysis can be made with Fabric Pipelines. You don’t need complicated scripting to visually design these pipelines, schedule automatic refreshes, and keep an eye on their execution thanks to the drag-and-drop interface.
Fabric pipelines are robust and scalable because they also support conditional logic, error handling, and integration with external services. Pipelines offer a streamlined, dependable way to maintain the smooth flow of your data, whether you need to combine data from various sources, prepare datasets for reporting, or refresh sales data daily.
Later on, we’ll see Microsoft Fabric’s Collaboration and Sharing feature and wrap it up.
Within a single ecosystem, Microsoft Fabric streamlines the data journey from ingestion to insight. Fabric provides a unified, low-code platform to speed up your analytics workflow, regardless of your level of experience with data or your decision to switch from traditional BI tools. It’s making data work more accessible and opening up previously unheard-of chances for cross-functional cooperation.
After that, we’ll examine FAQs.
No, both technical and non-technical users can use Microsoft Fabric. It is beginner-friendly due to its drag-and-drop capabilities, Power Query interface, and smooth integration with pre-existing Microsoft tools (Excel, Power BI, etc.).
Data engineering, real-time analytics, reporting, and visualization are all combined into a single platform for unified data analytics.
Within a few days, novices can begin creating simple workflows. A few weeks of practical experience may be required for more complex features like pipeline orchestration or lakehouse management.
This blog focuses on the features, architecture, and integration potential of Microsoft Fabric’s data pipelines. It describes how these pipelines help organizations efficiently streamline their data processes by automating data workflows and preparing data for analytics.
If you’re looking to upskill in Fabric and build a strong foundation in modern data engineering, Edureka’s Microsoft Fabric Data Engineer Associate Training (DP-700) is a great place to start. This course covers everything from working with OneLake and Lakehouse architecture to building data pipelines, managing workloads, and optimizing performance in Fabric. With hands-on labs, real-world scenarios, and guidance aligned with the official DP-700 certification, this program helps you gain the expertise needed for high-demand roles in data engineering and analytics.
Do you have any questions or need further information? Feel free to leave a comment below, and we’ll respond as soon as possible!























