In today’s market, Microservices have become the go-to solution, to build an application. They are known to solve various challenges, but yet, skilled professionals often face challenges while using this architecture. So, instead, developers can explore the common patterns in these problems, and can create reusable solutions to improve the performance of the application. Thus, in this article on Microservices Design Patterns, I will discuss the top patterns necessary to build a successful Microservices.
 What are Microservices?
What are Microservices?
 What are Microservices?
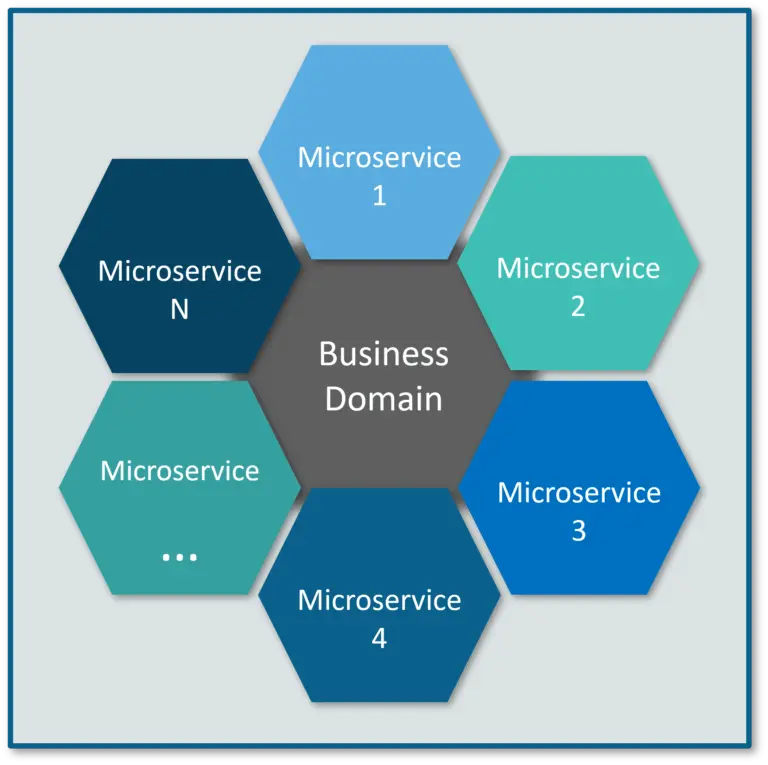
What are Microservices?Microservices, aka microservice architecture, is an architectural style that structures an application as a collection of small autonomous services, modeled around a business domain. In a Microservice Architecture, each service is self-contained and implements a single business capability. If you want a detailed understanding on Microservices, you can refer to my article on Microservices Architecture.
 Principles Used to Design Microservice Architecture
Principles Used to Design Microservice Architecture
 Principles Used to Design Microservice Architecture
Principles Used to Design Microservice ArchitectureThe principles used to design Microservices are as follows:
- Independent & Autonomous Services
- Scalability
- Decentralization
- Resilient Services
- Real-Time Load Balancing
- Availability
- Continuous delivery through DevOps Integration
- Seamless API Integration and Continuous Monitoring
- Isolation from Failures
- Auto -Provisioning
Design Patterns of Microservices
Aggregator Pattern
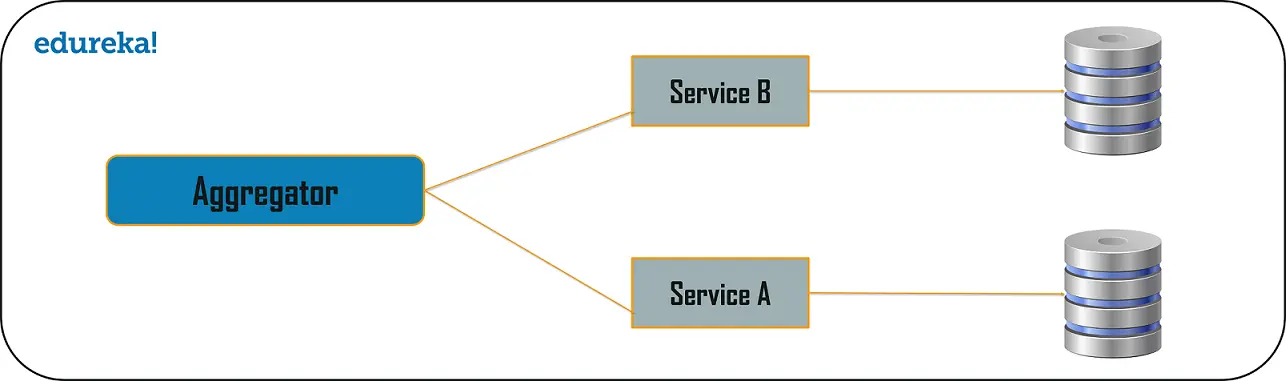
Aggregator in the computing world refers to a website or program that collects related items of data and displays them. So, even in Microservices patterns, Aggregator is a basic web page which invokes various services to get the required information or achieve the required functionality.
Also, since the source of output gets divided on breaking the monolithic architecture to microservices, this pattern proves to be beneficial when you need an output by combining data from multiple services. So, if we have two services each having their own database, then an aggregator having a unique transaction ID, would collect the data from each individual microservice, apply the business logic and finally publish it as a REST endpoint. Later on, the data collected can be consumed by the respective services which require that collected data.
The Aggregate Design Pattern is based on the DRY principle. Based on this principle, you can abstract the logic into a composite microservices and aggregate that particular business logic into one service.
So, for example, if you consider two services: Service A and B, then you can individually scale these services simultaneously by providing the data to the composite microservice.
 API Gateway Design Pattern
API Gateway Design Pattern
 API Gateway Design Pattern
API Gateway Design PatternMicroservices are built in such a way that each service has its own functionality. But, when an application is broken down into small autonomous services, then there could be few problems that a developer might face. The problems could be as follows:
- How can I request information from multiple microservices?
- Different UI require different data to respond to the same backend database service
- How to transform data according to the consumer requirement from reusable Microservices
- How to handle multiple protocol requests?
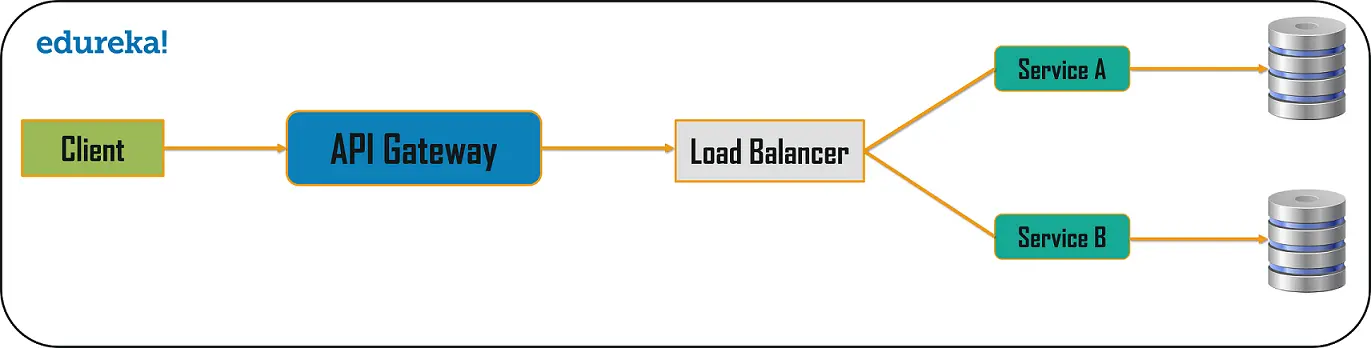
Well, the solution to these kinds of problems could be the API Gateway Design Pattern. The API Gateway Design Pattern address not only the concerns mentioned above but it solves many other problems. This microservice design pattern can also be considered as the proxy service to route a request to the concerned microservice. Being a variation of the Aggregator service, it can send the request to multiple services and similarly aggregate the results back to the composite or the consumer service. API Gateway also acts as the entry point for all the microservices and creates fine-grained APIs’ for different types of clients.
With the help of the API Gateway design pattern, the API gateways can convert the protocol request from one type to other. Similarly, it can also offload the authentication/authorization responsibility of the microservice.
So, once the client sends a request, these requests are passed to the API Gateway which acts as an entry point to forward the clients’ requests to the appropriate microservices. Then, with the help of the load balancer, the load of the request is handled and the request is sent to the respective services. Microservices use Service Discovery which acts as a guide to find the route of communication between each of them. Microservices then communicate with each other via a stateless server i.e. either by HTTP Request/Message Bus.
 Chained or Chain of Responsibility Pattern
Chained or Chain of Responsibility Pattern
 Chained or Chain of Responsibility Pattern
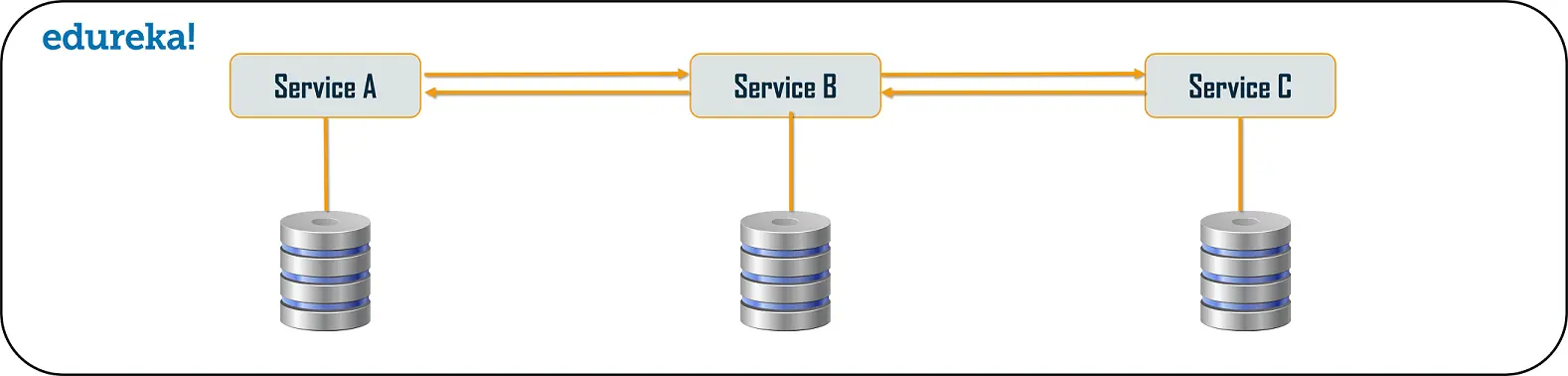
Chained or Chain of Responsibility PatternChained or Chain of Responsibility Design Patterns produces a single output which is a combination of multiple chained outputs. So, if you have three services lined up in a chain, then, the request from the client is first received by Service A. Then, this service communicates with the next Service B and collects data. Finally, the second service communicates with the third service to generate the consolidated output. All these services use synchronous HTTP request or response for messaging. Also, until the request passes through all the services and the respective responses are generated, the client doesn’t get any output. So, it is always recommended to not to make a long chain, as the client will wait until the chain is completed
One more important aspect which you need to understand, is that the request from Service A to Service B may look different from Service B to Service C. Similarly the response from Service C to Service B may look completely different from Service B to Service A.
Asynchronous Messaging Design Pattern
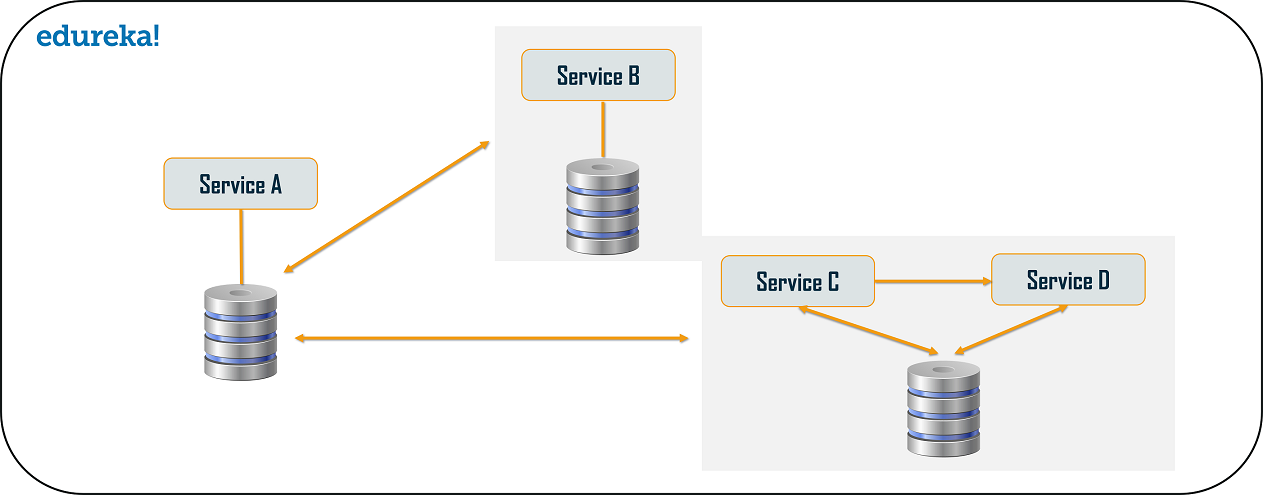
From the above pattern, it is quite obvious that the client gets blocked or has to wait for a long time in synchronous messaging. But, if you do not want the consumer, to wait for a long time, then you can opt for the Asynchronous Messaging. In this type of microservices design pattern, all the services can communicate with each other, but they do not have to communicate with each other sequentially. So, if you consider 3 services: Service A, Service B, and Service C. The request from the client can be directly sent to the Service C and Service B simultaneously. These requests will be in a queue. Apart from this, the request can also be sent to Service A whose response need not have to be sent to the same service through which request has come.

Database or Shared Data Pattern
For every application, there is humongous amount of data present. So, when we break down an application from its monolithic architecture to microservices, it is very important to note that each microservice has sufficient amount of data to process a request. So, either the system can have a database per each service or it can have shared database per service. You can use database per service and shared database per service to solve various problems. The problems could be as follows:
- Duplication of data and inconsistency
- Different services have different kinds of storage requirements
- Few business transactions can query the data, with multiple services
- De-normalization of data
Well, to solve the first three problems, I think you can go for database per service, as it will be then accessed by the microservice API itself. So, each microservice will have its own database ID, which thereafter prevents the other services in the system to use that particular database. Apart from this, to solve the issue of de-normalization, you can choose shared databases per service, to align more than one database for each microservice. This will help you gather data, for the monolithic applications which are broken down into microservices. But, you have to keep in mind that, you have to limit these databases to 2-3 microservices; else, scaling these services will be a problem.
Event Sourcing Design Pattern
The event sourcing design pattern creates events regarding the changes in the application state. Also, these events are stored as a sequence of events to help the developers track which change was made when. So, with the help of this, you can always adjust the application state to cope up with the past changes. You can also query these events, for any data change and simultaneously publish these events from the event store. Once the events are published, you can see the changes of the application state on the presentation layer.
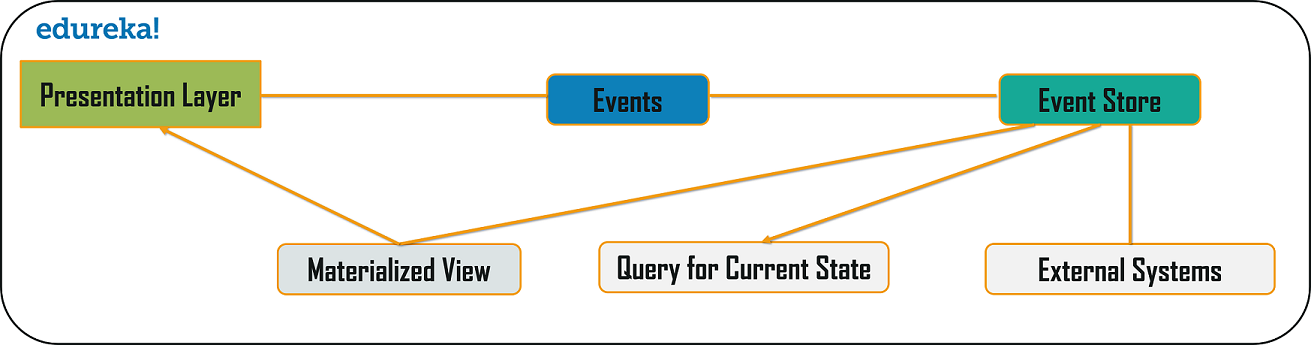
Branch Pattern
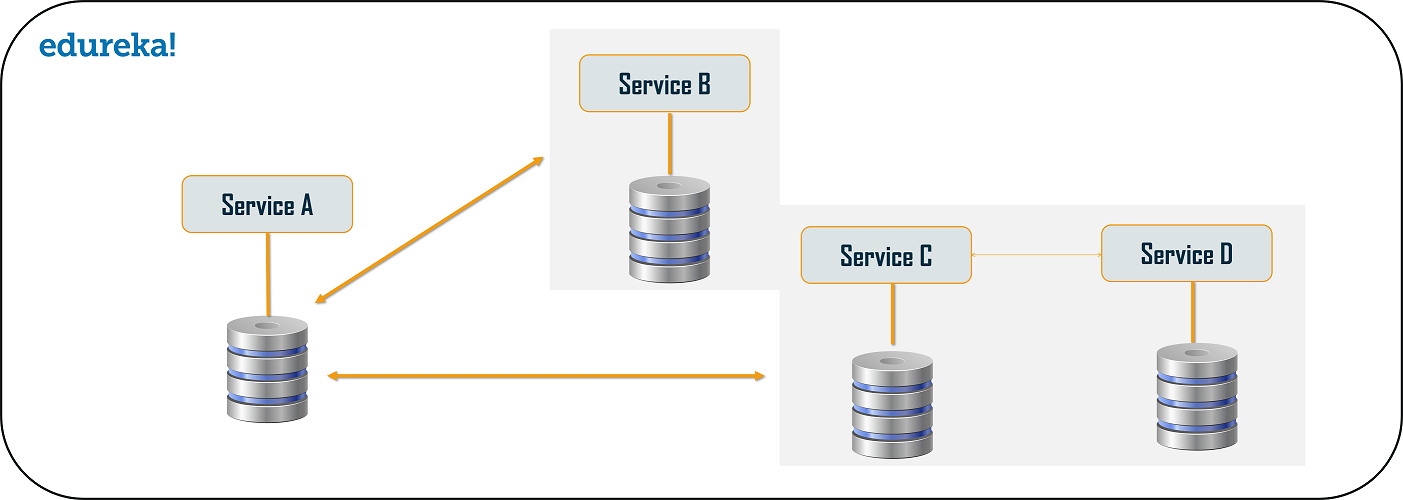
Branch microservice design pattern is a design pattern in which you can simultaneously process the requests and responses from two or more independent microservices. So, unlike the chained design pattern, the request is not passed in a sequence, but the request is passed to two or more mutually exclusive microservices chains. This design pattern extends the Aggregator design pattern and provides the flexibility to produce responses from multiple chains or single chain. For example, if you consider an e-commerce application, then you may need to retrieve data from multiple sources and this data could be a collaborated output of data from various services. So, you can use the branch pattern, to retrieve data from multiple sources.
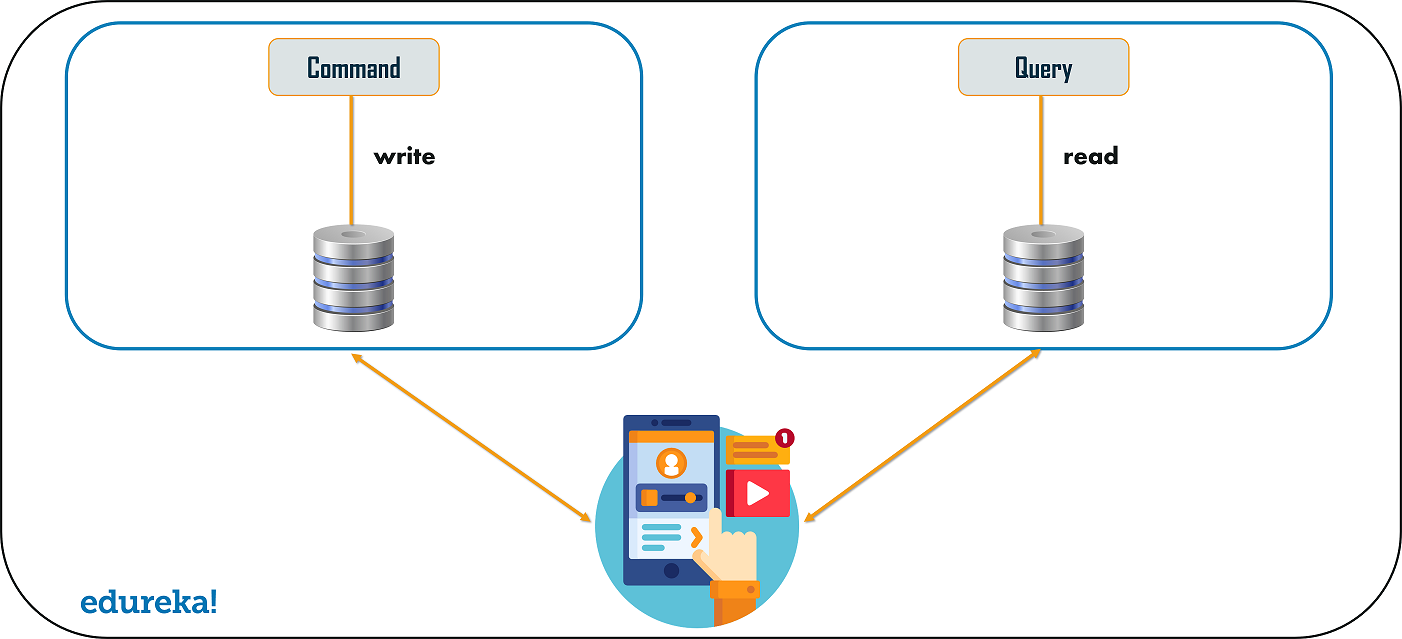
Command Query Responsibility Segregator (CQRS) Design Pattern
Every microservices design has either the database per service model or the shared database per service. But, in the database per service model, we cannot implement a query as the data access is only limited to one single database. So, in such scenario you can use the CQRS pattern. According to this pattern, the application will be divided into two parts: Command and Query. The command part will handle all the requests related to CREATE, UPDATE, DELETE while the query part will take care of the materialized views. The materialized views are updated through a sequence of events which are creating using the event source pattern discussed above.
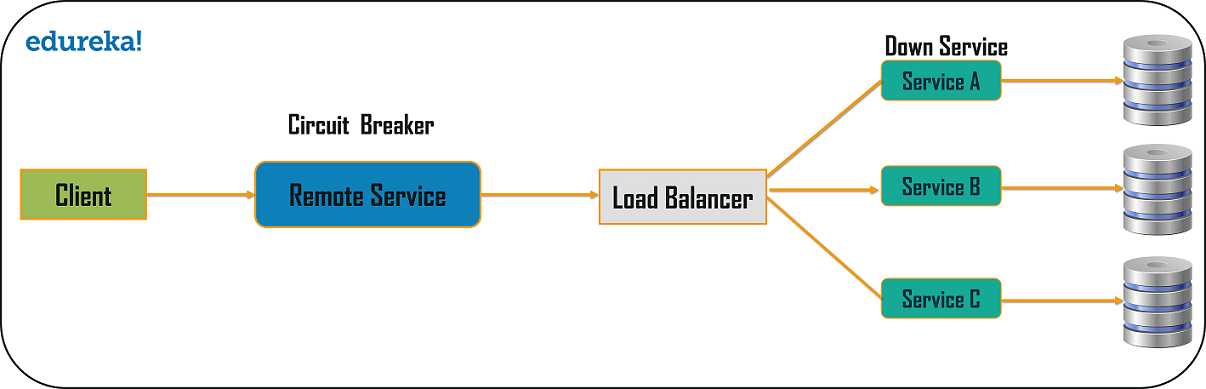
Circuit Breaker Pattern
As the name suggests, the Circuit Breaker design pattern is used to stop the process of request and response if a service is not working. So, for example, let’s say a client is sending a request to retrieve data from multiple services. But, due to some issues, one of the services is down. Now, there are mainly two problems you will face: first, since the client will not have any knowledge about a particular service being down, the request will be continuously sent to that service. The second problem is that the network resources will be exhausted with low performance and bad user experience.
So, to avoid such problems, you can use the Circuit Breaker Design Pattern. With the help of this pattern, the client will invoke a remote service via a proxy. This proxy will basically behave as a circuit barrier. So, when the number of failures crosses the threshold number, the circuit breaker trips for a particular time period. Then, all the attempts to invoke the remote service will fail in this timeout period. Once that time period is finished, the circuit breaker will allow a limited number of tests to pass through and if those requests succeed, the circuit breaker resumes back to the normal operation. Else, if there is a failure, then the time out period begins again.
Decomposition Design Pattern
Microservices are developed with an idea on developers mind to create small services, with each having their own functionality. But, breaking an application into small autonomous units has to be done logically. So, to decompose a small or big application into small services, you can use the Decomposition patterns.
With the help of this pattern, either you can decompose an application based on business capability or on based on the sub-domains. For example, if you consider an e-commerce application, then you can have separate services for orders, payment, customers, products if you decompose by business capability.
But, in the same scenario, if you design the application by decomposing the sub-domains, then you can have services for each and every class. Here, in this example, if you consider the customer as a class, then this class will be used in customer management, customer support, etc. So, to decompose, you can use the Domain-Driven Design through which the whole domain model is broken down into sub-domains. Then, each of these sub-domains will have their own specific model and scope(bounded context). Now, when a developer designs microservices, he/she will design those services around the scope or bounded context.
Though these patterns may sound feasible to you, they are not feasible for big monolithic applications. This is because of the fact that identifying sub-domains and business capabilities is not an easy task for big applications. So, the only way to decompose big monolithic applications is by following the Vine Pattern or the Strangler Pattern.
Strangler Pattern or Vine Pattern
The Strangler Pattern or the Vine Pattern is based on the analogy to a vine which basically strangles a tree that it is wrapped around. So, when this pattern is applied on the web applications, a call goes back and forth for each URI call and the services are broken down into different domains. These domains will be hosted as separate services.
According to the strangler pattern, two separate applications will live side by side in the same URI space, and one domain will be taken in to account at an instance of time. So, eventually, the new refactored application wraps around or strangles or replaces the original application until you can shut down the monolithic application
So, folks, with this we come to an end to this article on Microservices Design Patterns. I hope you have understood the top patterns to design Microservices. If you wish to learn Microservices and build your own applications, then check out our Microservices Certification Training which comes with instructor-led live training and real-life project experience. This training will help you understand Microservices in-depth and help you achieve mastery over the subject.
Got a question for us? Please mention it in the comments section of ” Microservices Design Patterns” and I will get back to you.