







MapReduce Tutorial: Introduction
In this MapReduce Tutorial blog, I am going to introduce you to MapReduce, which is one of the core building blocks of processing in Hadoop framework. Before moving ahead, I would suggest you to get familiar with HDFS concepts which I have covered in my previous HDFS tutorial blog. This will help you to understand the MapReduce concepts quickly and easily.
Before we begin, let us have a brief understanding of the following.
What is Big Data?


Big Data can be termed as that colossal load of data that can be hardly processed using the traditional data processing units. A better example of Big Data would be the currently trending Social Media sites like Facebook, Instagram, WhatsApp and YouTube.


What is Hadoop?
Hadoop is a Big Data framework designed and deployed by Apache Foundation. It is an open-source software utility that works in the network of computers in parallel to find solutions to Big Data and process it using the MapReduce algorithm.
Google released a paper on MapReduce technology in December 2004. This became the genesis of the Hadoop Processing Model. So, MapReduce is a programming model that allows us to perform parallel and distributed processing on huge data sets. The topics that I have covered in this MapReduce tutorial blog are as follows:
- Traditional Way for parallel and distributed processing
- What is MapReduce?
- MapReduce Example
- MapReduce Advantages
- MapReduce Program
- MapReduce Program Explained
- MapReduce Use Case: KMeans Algorithm
MapReduce Tutorial: Traditional Way
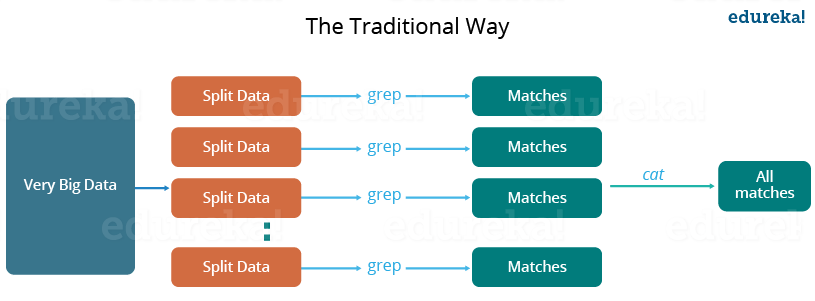

Let us understand, when the MapReduce framework was not there, how parallel and distributed processing used to happen in a traditional way. So, let us take an example where I have a weather log containing the daily average temperature of the years from 2000 to 2015. Here, I want to calculate the day having the highest temperature in each year.
So, just like in the traditional way, I will split the data into smaller parts or blocks and store them in different machines. Then, I will find the highest temperature in each part stored in the corresponding machine. At last, I will combine the results received from each of the machines to have the final output. Let us look at the challenges associated with this traditional approach:
- Critical path problem: It is the amount of time taken to finish the job without delaying the next milestone or actual completion date. So, if, any of the machines delay the job, the whole work gets delayed.
- Reliability problem: What if, any of the machines which are working with a part of data fails? The management of this failover becomes a challenge.
- Equal split issue: How will I divide the data into smaller chunks so that each machine gets even part of data to work with. In other words, how to equally divide the data such that no individual machine is overloaded or underutilized.
- The single split may fail: If any of the machines fail to provide the output, I will not be able to calculate the result. So, there should be a mechanism to ensure this fault tolerance capability of the system.
- Aggregation of the result: There should be a mechanism to aggregate the result generated by each of the machines to produce the final output.
These are the issues which I will have to take care individually while performing parallel processing of huge data sets when using traditional approaches.
To overcome these issues, we have the MapReduce framework which allows us to perform such parallel computations without bothering about the issues like reliability, fault tolerance etc. Therefore, MapReduce gives you the flexibility to write code logic without caring about the design issues of the system. You can get a better understanding with the Azure Data Engineering certification.
MapReduce Tutorial: What is MapReduce?
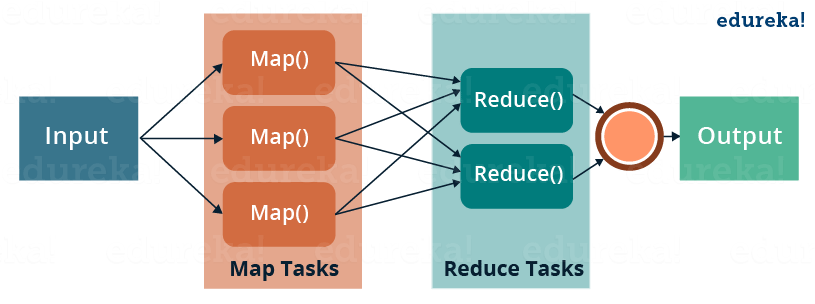

MapReduce is a programming framework that allows us to perform distributed and parallel processing on large data sets in a distributed environment.
- MapReduce consists of two distinct tasks – Map and Reduce.
- As the name MapReduce suggests, the reducer phase takes place after the mapper phase has been completed.
- So, the first is the map job, where a block of data is read and processed to produce key-value pairs as intermediate outputs.
- The output of a Mapper or map job (key-value pairs) is input to the Reducer.
- The reducer receives the key-value pair from multiple map jobs.
- Then, the reducer aggregates those intermediate data tuples (intermediate key-value pair) into a smaller set of tuples or key-value pairs which is the final output.
Let us understand more about MapReduce and its components. MapReduce majorly has the following three Classes. They are,
Mapper Class
The first stage in Data Processing using MapReduce is the Mapper Class. Here, RecordReader processes each Input record and generates the respective key-value pair. Hadoop’s Mapper store saves this intermediate data into the local disk.
- Input Split
It is the logical representation of data. It represents a block of work that contains a single map task in the MapReduce Program.
- RecordReader
It interacts with the Input split and converts the obtained data in the form of Key-Value Pairs.
Reducer Class
The Intermediate output generated from the mapper is fed to the reducer which processes it and generates the final output which is then saved in the HDFS.
Driver Class
The major component in a MapReduce job is a Driver Class. It is responsible for setting up a MapReduce Job to run-in Hadoop. We specify the names of Mapper and Reducer Classes long with data types and their respective job names.
Meanwhile, you may go through this MapReduce Tutorial video where our expert from Hadoop online training has discussed all the concepts related to MapReduce has been clearly explained using examples:
Hadoop MapReduce Tutorial | MapReduce Example | Edureka
MapReduce Tutorial: A Word Count Example of MapReduce
Let us understand, how a MapReduce works by taking an example where I have a text file called example.txt whose contents are as follows:
Dear, Bear, River, Car, Car, River, Deer, Car and Bear
Now, suppose, we have to perform a word count on the sample.txt using MapReduce. So, we will be finding the unique words and the number of occurrences of those unique words.
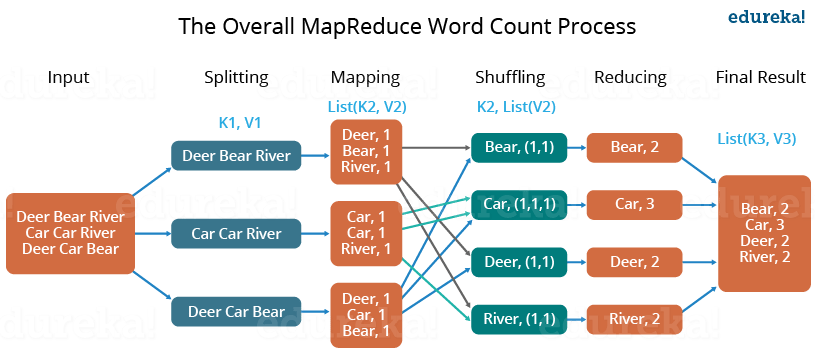

- First, we divide the input into three splits as shown in the figure. This will distribute the work among all the map nodes.
- Then, we tokenize the words in each of the mappers and give a hardcoded value (1) to each of the tokens or words. The rationale behind giving a hardcoded value equal to 1 is that every word, in itself, will occur once.
- Now, a list of key-value pair will be created where the key is nothing but the individual words and value is one. So, for the first line (Dear Bear River) we have 3 key-value pairs – Dear, 1; Bear, 1; River, 1. The mapping process remains the same on all the nodes.
- After the mapper phase, a partition process takes place where sorting and shuffling happen so that all the tuples with the same key are sent to the corresponding reducer.
- So, after the sorting and shuffling phase, each reducer will have a unique key and a list of values corresponding to that very key. For example, Bear, [1,1]; Car, [1,1,1].., etc.
- Now, each Reducer counts the values which are present in that list of values. As shown in the figure, reducer gets a list of values which is [1,1] for the key Bear. Then, it counts the number of ones in the very list and gives the final output as – Bear, 2.
- Finally, all the output key/value pairs are then collected and written in the output file.
MapReduce Tutorial: Advantages of MapReduce
The two biggest advantages of MapReduce are:
1. Parallel Processing:
In MapReduce, we are dividing the job among multiple nodes and each node works with a part of the job simultaneously. So, MapReduce is based on Divide and Conquer paradigm which helps us to process the data using different machines. As the data is processed by multiple machines instead of a single machine in parallel, the time taken to process the data gets reduced by a tremendous amount as shown in the figure below (2).
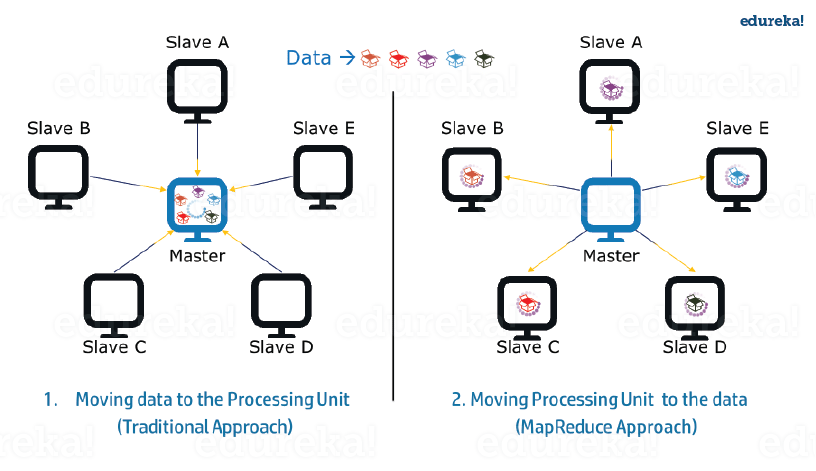

2. Data Locality:
Instead of moving data to the processing unit, we are moving the processing unit to the data in the MapReduce Framework. In the traditional system, we used to bring data to the processing unit and process it. But, as the data grew and became very huge, bringing this huge amount of data to the processing unit posed the following issues:
- Moving huge data to processing is costly and deteriorates the network performance.
- Processing takes time as the data is processed by a single unit which becomes the bottleneck.
- The master node can get over-burdened and may fail.
Now, MapReduce allows us to overcome the above issues by bringing the processing unit to the data. So, as you can see in the above image that the data is distributed among multiple nodes where each node processes the part of the data residing on it. This allows us to have the following advantages:
- It is very cost-effective to move processing unit to the data.
- The processing time is reduced as all the nodes are working with their part of the data in parallel.
- Every node gets a part of the data to process and therefore, there is no chance of a node getting overburdened.
MapReduce Tutorial: MapReduce Example Program
Before jumping into the details, let us have a glance at a MapReduce example program to have a basic idea about how things work in a MapReduce environment practically. I have taken the same word count example where I have to find out the number of occurrences of each word. And Don’t worry guys, if you don’t understand the code when you look at it for the first time, just bear with me while I walk you through each part of the MapReduce code. You can get a better understanding with the Azure Data Engineering Training in Atlanta.
MapReduce Tutorial: Explanation of MapReduce Program
The entire MapReduce program can be fundamentally divided into three parts:
- Mapper Phase Code
- Reducer Phase Code
- Driver Code
We will understand the code for each of these three parts sequentially.
Mapper code:
public static class Map extends Mapper<LongWritable,Text,Text,IntWritable> {
public void map(LongWritable key, Text value, Context context) throws IOException,InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
value.set(tokenizer.nextToken());
context.write(value, new IntWritable(1));
}
- We have created a class Map that extends the class Mapper which is already defined in the MapReduce Framework.

- We define the data types of input and output key/value pair after the class declaration using angle brackets.
- Both the input and output of the Mapper is a key/value pair.
- Input:
- The key is nothing but the offset of each line in the text file: LongWritable
- The value is each individual line (as shown in the figure at the right): Text
- Output:
- The key is the tokenized words: Text
- We have the hardcoded value in our case which is 1: IntWritable
- Example – Dear 1, Bear 1, etc.
- We have written a java code where we have tokenized each word and assigned them a hardcoded value equal to 1.

Reducer Code:
public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,Context context)
throws IOException,InterruptedException {
int sum=0;
for(IntWritable x: values)
{
sum+=x.get();
}
context.write(key, new IntWritable(sum));
}
}
- We have created a class Reduce which extends class Reducer like that of Mapper.
- We define the data types of input and output key/value pair after the class declaration using angle brackets as done for Mapper.
- Both the input and the output of the Reducer is a key-value pair.
- Input:
- The key nothing but those unique words which have been generated after the sorting and shuffling phase: Text
- The value is a list of integers corresponding to each key: IntWritable
- Example – Bear, [1, 1], etc.
- Output:
- The key is all the unique words present in the input text file: Text
- The value is the number of occurrences of each of the unique words: IntWritable
- Example – Bear, 2; Car, 3, etc.
- We have aggregated the values present in each of the list corresponding to each key and produced the final answer.
- In general, a single reducer is created for each of the unique words, but, you can specify the number of reducer in mapred-site.xml.
Driver Code:
Configuration conf= new Configuration(); Job job = new Job(conf,"My Word Count Program"); job.setJarByClass(WordCount.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); Path outputPath = new Path(args[1]); //Configuring the input/output path from the filesystem into the job FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1]));
- In the driver class, we set the configuration of our MapReduce job to run in Hadoop.
- We specify the name of the job, the data type of input/output of the mapper and reducer.
- We also specify the names of the mapper and reducer classes.
- The path of the input and output folder is also specified.
- The method setInputFormatClass () is used for specifying how a Mapper will read the input data or what will be the unit of work. Here, we have chosen TextInputFormat so that a single line is read by the mapper at a time from the input text file.
- The main () method is the entry point for the driver. In this method, we instantiate a new Configuration object for the job.
Source code:
package co.edureka.mapreduce;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.fs.Path;
public class WordCount{
public static class Map extends Mapper<LongWritable,Text,Text,IntWritable> {
public void map(LongWritable key, Text value,Context context) throws IOException,InterruptedException{
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
value.set(tokenizer.nextToken());
context.write(value, new IntWritable(1));
}
}
}
public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException,InterruptedException {
int sum=0;
for(IntWritable x: values)
{
sum+=x.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf= new Configuration();
Job job = new Job(conf,"My Word Count Program");
job.setJarByClass(WordCount.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path(args[1]);
//Configuring the input/output path from the filesystem into the job
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//deleting the output path automatically from hdfs so that we don't have to delete it explicitly
outputPath.getFileSystem(conf).delete(outputPath);
//exiting the job only if the flag value becomes false
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Run the MapReduce code:
The command for running a MapReduce code is:
hadoop jar hadoop-mapreduce-example.jar WordCount /sample/input /sample/output
Now, we will look into a Use Case based on MapReduce Algorithm.
Use case: KMeans Clustering using Hadoop’s MapReduce.
KMeans Algorithm is one of the simplest Unsupervised Machine Learning Algorithm. Typically, unsupervised algorithms make inferences from datasets using only input vectors without referring to known or labelled outcomes.
Executing the KMeans Algorithm using Python with a smaller Dataset or a .csv file is easy. But, when it comes to executing the Datasets at the level of Big Data, then the normal procedure cannot stay handy anymore.
That is exactly when you deal Big Data with Big Data tools. The Hadoop’s MapReduce. The following code snippets are the Components of MapReduce performing the Mapper, Reducer and Driver Jobs
//Mapper Class
public void map(LongWritable key, Text value, OutputCollector<DoubleWritable, DoubleWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
double point = Double.parseDouble(line);
double min1, min2 = Double.MAX_VALUE, nearest_center = mCenters.get(0);
for (double c : mCenters) {
min1 = c - point;
if (Math.abs(min1) < Math.abs(min2)) {
nearest_center = c;
min2 = min1;
}
}
output.collect(new DoubleWritable(nearest_center),
new DoubleWritable(point));
}
}//Reducer Class
public static class Reduce extends MapReduceBase implements
Reducer<DoubleWritable, DoubleWritable, DoubleWritable, Text> {
@Override
public void reduce(DoubleWritable key, Iterator<DoubleWritable> values, OutputCollector<DoubleWritable, Text> output, Reporter reporter)throws IOException {
double newCenter;
double sum = 0;
int no_elements = 0;
String points = "";
while (values.hasNext()) {
double d = values.next().get();
points = points + " " + Double.toString(d);
sum = sum + d;
++no_elements;
}
newCenter = sum / no_elements;
output.collect(new DoubleWritable(newCenter), new Text(points));
}
}//Driver Class
public static void run(String[] args) throws Exception {
IN = args[0];
OUT = args[1];
String input = IN;
String output = OUT + System.nanoTime();
String again_input = output;
int iteration = 0;
boolean isdone = false;
while (isdone == false) {
JobConf conf = new JobConf(KMeans.class);
if (iteration == 0) {
Path hdfsPath = new Path(input + CENTROID_FILE_NAME);
DistributedCache.addCacheFile(hdfsPath.toUri(), conf);
} else {
Path hdfsPath = new Path(again_input + OUTPUT_FIE_NAME);
DistributedCache.addCacheFile(hdfsPath.toUri(), conf);
}
conf.setJobName(JOB_NAME);
conf.setMapOutputKeyClass(DoubleWritable.class);
conf.setMapOutputValueClass(DoubleWritable.class);
conf.setOutputKeyClass(DoubleWritable.class);
conf.setOutputValueClass(Text.class);
conf.setMapperClass(Map.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input + DATA_FILE_NAME));
FileOutputFormat.setOutputPath(conf, new Path(output));
JobClient.runJob(conf);
Path ofile = new Path(output + OUTPUT_FIE_NAME);
FileSystem fs = FileSystem.get(new Configuration());
BufferedReader br = new BufferedReader(new InputStreamReader(fs.open(ofile)));
List<Double> centers_next = new ArrayList<Double>();
String line = br.readLine();
while (line != null) {
String[] sp = line.split("t| ");
double c = Double.parseDouble(sp[0]);
centers_next.add(c);
line = br.readLine();
}
br.close();
String prev;
if (iteration == 0) {
prev = input + CENTROID_FILE_NAME;
} else {
prev = again_input + OUTPUT_FILE_NAME;
}
Path prevfile = new Path(prev);
FileSystem fs1 = FileSystem.get(new Configuration());
BufferedReader br1 = new BufferedReader(new InputStreamReader(fs1.open(prevfile)));
List<Double> centers_prev = new ArrayList<Double>();
String l = br1.readLine();
while (l != null) {
String[] sp1 = l.split(SPLITTER);
double d = Double.parseDouble(sp1[0]);
centers_prev.add(d);
l = br1.readLine();
}
br1.close();
Collections.sort(centers_next);
Collections.sort(centers_prev);
Iterator<Double> it = centers_prev.iterator();
for (double d : centers_next) {
double temp = it.next();
if (Math.abs(temp - d) <= 0.1) {
isdone = true;
} else {
isdone = false;
break;
}
}
++iteration;
again_input = output;
output = OUT + System.nanoTime();
}
}Now, we will go through the complete executable code
//Source Code
import java.io.IOException;
import java.util.*;
import java.io.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.mapred.Reducer;
@SuppressWarnings("deprecation")
public class KMeans {
public static String OUT = "outfile";
public static String IN = "inputlarger";
public static String CENTROID_FILE_NAME = "/centroid.txt";
public static String OUTPUT_FILE_NAME = "/part-00000";
public static String DATA_FILE_NAME = "/data.txt";
public static String JOB_NAME = "KMeans";
public static String SPLITTER = "t| ";
public static List<Double> mCenters = new ArrayList<Double>();
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, DoubleWritable, DoubleWritable> {
@Override
public void configure(JobConf job) {
try {
Path[] cacheFiles = DistributedCache.getLocalCacheFiles(job);
if (cacheFiles != null && cacheFiles.length > 0) {
String line;
mCenters.clear();
BufferedReader cacheReader = new BufferedReader(
new FileReader(cacheFiles[0].toString()));
try {
while ((line = cacheReader.readLine()) != null) {
String[] temp = line.split(SPLITTER);
mCenters.add(Double.parseDouble(temp[0]));
}
} finally {
cacheReader.close();
}
}
} catch (IOException e) {
System.err.println("Exception reading DistribtuedCache: " + e);
}
}
@Override
public void map(LongWritable key, Text value, OutputCollector<DoubleWritable, DoubleWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
double point = Double.parseDouble(line);
double min1, min2 = Double.MAX_VALUE, nearest_center = mCenters.get(0);
for (double c : mCenters) {
min1 = c - point;
if (Math.abs(min1) < Math.abs(min2)) {
nearest_center = c;
min2 = min1;
}
}
output.collect(new DoubleWritable(nearest_center),
new DoubleWritable(point));
}
}
public static class Reduce extends MapReduceBase implements
Reducer<DoubleWritable, DoubleWritable, DoubleWritable, Text> {
@Override
public void reduce(DoubleWritable key, Iterator<DoubleWritable> values, OutputCollector<DoubleWritable, Text> output, Reporter reporter)throws IOException {
double newCenter;
double sum = 0;
int no_elements = 0;
String points = "";
while (values.hasNext()) {
double d = values.next().get();
points = points + " " + Double.toString(d);
sum = sum + d;
++no_elements;
}
newCenter = sum / no_elements;
output.collect(new DoubleWritable(newCenter), new Text(points));
}
}
public static void main(String[] args) throws Exception {
run(args);
}
public static void run(String[] args) throws Exception {
IN = args[0];
OUT = args[1];
String input = IN;
String output = OUT + System.nanoTime();
String again_input = output;
int iteration = 0;
boolean isdone = false;
while (isdone == false) {
JobConf conf = new JobConf(KMeans.class);
if (iteration == 0) {
Path hdfsPath = new Path(input + CENTROID_FILE_NAME);
DistributedCache.addCacheFile(hdfsPath.toUri(), conf);
} else {
Path hdfsPath = new Path(again_input + OUTPUT_FIE_NAME);
DistributedCache.addCacheFile(hdfsPath.toUri(), conf);
}
conf.setJobName(JOB_NAME);
conf.setMapOutputKeyClass(DoubleWritable.class);
conf.setMapOutputValueClass(DoubleWritable.class);
conf.setOutputKeyClass(DoubleWritable.class);
conf.setOutputValueClass(Text.class);
conf.setMapperClass(Map.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input + DATA_FILE_NAME));
FileOutputFormat.setOutputPath(conf, new Path(output));
JobClient.runJob(conf);
Path ofile = new Path(output + OUTPUT_FIE_NAME);
FileSystem fs = FileSystem.get(new Configuration());
BufferedReader br = new BufferedReader(new InputStreamReader(fs.open(ofile)));
List<Double> centers_next = new ArrayList<Double>();
String line = br.readLine();
while (line != null) {
String[] sp = line.split("t| ");
double c = Double.parseDouble(sp[0]);
centers_next.add(c);
line = br.readLine();
}
br.close();
String prev;
if (iteration == 0) {
prev = input + CENTROID_FILE_NAME;
} else {
prev = again_input + OUTPUT_FILE_NAME;
}
Path prevfile = new Path(prev);
FileSystem fs1 = FileSystem.get(new Configuration());
BufferedReader br1 = new BufferedReader(new InputStreamReader(fs1.open(prevfile)));
List<Double> centers_prev = new ArrayList<Double>();
String l = br1.readLine();
while (l != null) {
String[] sp1 = l.split(SPLITTER);
double d = Double.parseDouble(sp1[0]);
centers_prev.add(d);
l = br1.readLine();
}
br1.close();
Collections.sort(centers_next);
Collections.sort(centers_prev);
Iterator<Double> it = centers_prev.iterator();
for (double d : centers_next) {
double temp = it.next();
if (Math.abs(temp - d) <= 0.1) {
isdone = true;
} else {
isdone = false;
break;
}
}
++iteration;
again_input = output;
output = OUT + System.nanoTime();
}
}
}Now, you guys have a basic understanding of MapReduce framework. You would have realized how the MapReduce framework facilitates us to write code to process huge data present in the HDFS. There have been significant changes in the MapReduce framework in Hadoop 2.x as compared to Hadoop 1.x. These changes will be discussed in the next blog of this MapReduce tutorial series. I will share a downloadable comprehensive guide which explains each part of the MapReduce program in that very blog.
Now that you have understood what is MapReduce and its advantages, check out the Hadoop training in Chennai by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. The Edureka Big Data Hadoop Certification Training course helps learners become expert in HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume and Sqoop using real-time use cases on Retail, Social Media, Aviation, Tourism, Finance domain.
Got a question for us? Please mention it in the comments section and we will get back to you.