






Human-Computer Interaction (HCI) for AI Syste ...
- 2k Enrolled Learners
- Weekend/Weekday
- Live Class
(450)
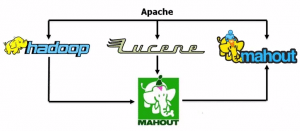
Mahout began its life in 2008, as a sub-project of Apache’s Lucene project, which provides the well-known open-source search engine of the same name.
With Lucene integrated with Solr, which is another product of Lucene, you can manage the distributed indexes using Solr.
Apache Lucene is core for Mahout’s origination. In 2008, Lucene had a few algorithms for doing some sort of clustering by default. Since it had some built-in analytics capabilities, like clustering, when they actually added recommendations engine on top of the search features, they spun out a new project called Mahout. It became a sub-level project of Apache. Later, Mahout absorbed Taste, an open-source collaborative filtering project.
Apache Mahout and its Related Projects within the Apache Software Foundation
The name of Mahout has been actually taken from a Hindi word, “Mahavat”, which means the rider of an elephant. Since it runs the algorithms on top of Hadoop, it has its name Mahout. Mahout is a scalable machine learning implementation. However, it’s not restricted to scalability; it also runs the algorithms in the standalone mode.
Mahout is anyhow not tightly coupled with Hadoop. You can run the algorithms even in the standalone mode. It’s not necessary that you have to learn how to run algorithms in Hadoop environment. It has the combination of both. There are a few algorithms which are specifically available for standalone mode, instead of MapReduce mode, because it takes a lot of efforts and lots of energy in order to rebuild an algorithm to run in MapReduce mode. This is why there are a few algorithms that can only run in a standalone mode.
Machine Learning has taken over the World Wide Web for various use cases, specifically talking about recommendations, and clustering classification. All the data science-related problems generate over World Wide Web, and machine learning complements the web today by providing solutions for the same.
The actual feature of Mahout is that it’s highly scalable because it runs algorithms on top of Hadoop environment with the support of MapReduce and HDFS. As compared to other traditional machine learning tools, like R, Weka, Octave, etc., Mahout is a very good complement. When you are dealing with massive data-sets, the traditional applications running the algorithms on top of such huge amounts of data are most likely to fail. That’s where Mahout gets its importance, even though, it has the capability to run in standalone mode.
Mahout has the functionality for most of the machine learning tasks that are commonly required. Many machine learning techniques have already been a part of Mahout and researches are on to add more. There are so many algorithms which have been migrated. Sooner or later, you can see the latest release of Mahout, i.e. Mahout 1.0. Currently, the latest version of Mahout is Mahout 0.8. In Mahout 0.8, there are a few algorithms, which have not really been optimized. The Mahout team has planned to remove many algorithms, which do not have support. They’ll be keeping only those algorithms, which have been supported and optimized and have had very good implementations for 1.0. They even have a plan to add more support for future algorithms.
They are open to suggestions from outside. So, even you can contribute to the Mahout Project to add any of the algorithms you would prefer to. Say, for example if you want to add an artificial neural network support, then definitely Mahout will be open to take your suggestion to add such algorithms into it.
Got a question for us? Please mention them in the comments section and we will get back to you.
Related Posts
Supervised Learning in Apache Mahout
Start your Training in Machine Learning with Mahout



















 REGISTER FOR FREE WEBINAR
REGISTER FOR FREE WEBINAR  Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP









