
Data Science with Python Certification Course
- 132k Enrolled Learners
- Weekend
- Live Class
(49300)





 Copy Link!
Copy Link!The evolution of Machine Learning has changed the entire 21st century. It is starting to redefine the way we live, and it’s time we understood what it is and why it matters. Logistic Regression is one of the most widely used Machine learning algorithms and in this blog on Logistic Regression In R you’ll understand it’s working and implementation using the R language.
To get in-depth knowledge on Data Science, you can enroll for live Data Science Certification Training by Edureka with 24/7 support and lifetime access.
In this Logistic Regression In R blog, I’ll be covering the following topics:
Machine learning is the science of getting computers to act by feeding them data and letting them learn a few tricks on their own, without being explicitly programmed to do so. There are 3 different approaches through which machines learn:
If you wish to learn more about the Types of Machine learning, you can check out our blog series on Machine Learning, it covers all the fundamental concepts of the various Machine learning algorithms and their use cases.
It is also necessary to have a good understanding of Machine learning. You can go through this video by our Machine learning experts to make yourself familiar with Machine Learning.
Now that you have an idea about the different types of machine learning, for this blog we’ll be focusing on Logistic regression which is a type of supervised machine learning algorithm.
A supervised learning algorithm can be used to solve two types of problems:
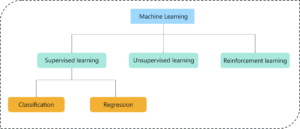
Classification & Regression – Logistic Regression In R – Edureka
Before we move any further and discuss about Logistic Regression, let’s try to draw a line between Classification and Regression problems.
Classification problems are used to assign labels to an input variable, i.e. they are used to classify a variable into one, of the two classes.
Let’s say you want to classify your emails into 2 groups, spam and non-spam emails. For this kind of problems, where you have to assign the input data into different classes, you can make use of classification algorithms. One important point to note here is that the response variable for a classification problem is categorical in nature.

Classification – Logistic Regression In R – Edureka
You can also go through our content on Classification Algorithms to get a better understanding about the various Classification algorithms used in Machine Learning.
On the other hand Regression is used to predict a continuous quantity. A continuous variable is basically a variable that has infinite number of possibilities. So for example, A person’s weight. Someone could weigh 180 pounds, they could weigh 180.10 pounds or they could weigh 180.1110 pounds. The number of possibilities for weight are limitless. And this is exactly what a continuous variable is.
Now that you have a brief understanding about Classification and Regression, let’s focus on Regression Analysis, which is the basic idea behind Logistic Regression.
Regression analysis is a predictive technique used to predict a continuous quantity. A continuous variable is basically a variable that has an infinite number of possibilities.
For example, a person’s height. Someone could be 165cms tall or they could be 165.02cms tall or they could be 165.022cms tall. The number of possibilities for height is limitless. And this is exactly what a continuous variable is.
So, regression is basically a predictive analysis technique used to predict continuous variables. Here you don’t have to label data into different classes, instead, you have to predict a final outcome like, let’s say you want to predict the price of a stock over a period of time.

Regression – Logistic Regression In R – Edureka
For such problems, you can make use of regression by studying the relationship between the dependent variable which is the stock price and the independent variable which is the time.
In order to understand why we use logistic regression, let’s consider a small scenario.
Let’s say that your little sister is trying to get into grad school, and you want to predict whether she’ll get admitted in her dream establishment. So, based on her CGPA and the past data, you can use Logistic Regression to foresee the outcome.
Logistic Regression allows you to analyze a set of variables and predict a categorical outcome. Since here we need to predict whether she will get into the school or not, which is a classification problem, logistic regression would be ideal.
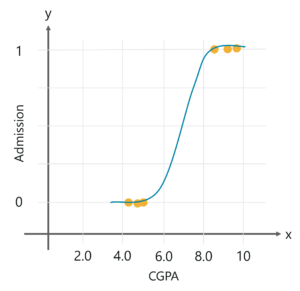
Logistic Regression Example – Logistic Regression In R – Edureka
You might be wondering why we’re not using Linear Regression in this case. The reason is that linear regression is used to predict a continuous quantity rather than a categorical one. So, when the resultant outcome can take only 2 possible values, it is only sensible to have a model that predicts the value either as 0 or 1 or in a probability form that ranges between 0 and 1.
Linear regression does not have this ability. If you use linear regression to model a binary outcome, the resulting model will not predict Y values in the range of 0 and 1 because linear regression works on continuous dependent variables and not on categorical variables. That’s why we make use of logistic regression.
If you’re still confused about the differences between Linear Regression and Logistic Regression, check out this video by our Machine learning experts.
What Is Logistic Regression?
Logistic Regression is one of the most basic and widely used machine learning algorithms for solving a classification problem. The reason it’s named ‘Logistic Regression’ is that its primary technique is quite similar to Linear Regression.
Logistic Regression is a method used to predict a dependent variable (Y), given an independent variable (X), such that the dependent variable is categorical.
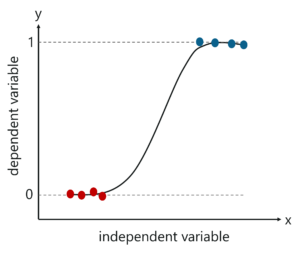
What is Logistic Regression – Logistic Regression In R – Edureka
When I say categorical variable, I mean that it holds values like 1 or 0, Yes or No, True or False and so on. So basically, in logistic regression, the outcome is always categorical.
One of the plus points of Logistic Regression is that it can be used to solve multi-class classification problems by using the Multinomial and Ordinal Logistic models.

Types of Logistic Regression – Logistic Regression In R – Edureka
Multinomial Logistic Regression:
Multinomial Regression is an extension of binary logistic regression, that is used when the response variable has more than 2 classes. Multinomial regression is used to handle multi-class classification problems.
Let’s assume that our response variable has K = 3 classes, then the Multinomial logistic model will fit K-1 independent binary logistic models in order to compute the final outcome.
Ordinal Logistic Regression also known as Ordinal classification is a predictive modeling technique used when the response variable is ordinal in nature.
An ordinal variable is one where the order of the values is significant, but not the difference between values. For example, you might ask a person to rate a movie on a scale of 1 to 5. A score of 4 is much better than 3, because it means that the person liked the movie. But the difference between a rating of 4 and the 3 may not be the same as that between 4 and 1. The values simply express an order.
So that was a brief overview of the different logistic models. However, in this blog, we’ll be focusing only on Binary Logistic Regression.
How Does Logistic Regression Work?
To understand how Logistic Regression works, let’s take a look at the Linear Regression equation:
Y = βo + β1X + ∈
So, given the fact that X is the explanatory variable (independent) and Y is the response variable (dependent), how can we represent a relationship between p(X)=Pr(Y=1|X) and X?
Here, Pr(Y=1|X) denotes the probability of Y=1, given some value of X.
The linear regression models these probabilities as:
p(X)=β0 + β1X
The Logistic Regression equation is derived from the same equation, except we need to make a few alterations since the response variable must accept only categorical values.
Logistic Regression does not necessarily calculate the outcome as 0 or 1, instead, it calculates the probability (ranges between 0 and 1) of a variable falling in class 0 or class 1. Thus, we can conclude that the resultant (dependent) variable must be positive and it should lie between 0 and 1 i.e. it must be less than 1.
In order to meet the above-mentioned conditions, we must do the following:
Hence, the formula:
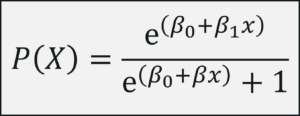
Logit() Function – Logistic Regression In R – Edureka
Next step is to calculate the logit() function.

Derivation – Logistic Regression In R – Edureka
The above derivation is quite simple, we just cross multiply and take e(β0 + β1X) common. The RHS denotes the linear equation for the independent variables, the LHS represents the odds ratio, also known as the logit function.
The logit function is the link function that is represented as an S curve or a Sigmoid curve that ranges between 0 – 1 and calculates the probability of the response variable.
In Logistic Regression, on increasing ‘X’ by one measure, changes the logit by a factor of β0. In simple terms, the regression coefficients describe the change in log(odds) in response to a unit change in predictor variable.
Now that you have a good understanding of how Logistic Regression works, let’s get on with the demo.
A small disclaimer before we get started, I’ll be using the R language to implement the Logistic Regression model. If you want to get a good understanding of R programming, check out this video.
Data Set Description: In this demo, we’ll be using the Default data provided by the ISLR package. This data set has information on around ten thousand customers, such as whether the customer defaulted, is a student, the average balance of the customer and the income of the customer.
Problem Statement: To fit a logistic regression model in order to predict the probability of a customer defaulting based on the average balance carried by the customer.
We’ll start the demo by installing the following packages:
#loading Packages
library(tidyverse)
library(modelr)
library(broom)
#Install ISLR Package
install.packages('ISLR')
#Load ISLR Package
library('ISLR')
Our next step is to import the data set and display it as a tibble:
# Load data (mydata <- as_tibble(ISLR::Default)) # A tibble: 10,000 x 4 default student balance income <fct> <fct> <dbl> <dbl> 1 No No 730. 44362. 2 No Yes 817. 12106. 3 No No 1074. 31767. 4 No No 529. 35704. 5 No No 786. 38463. 6 No Yes 920. 7492. 7 No No 826. 24905. 8 No Yes 809. 17600. 9 No No 1161. 37469. 10 No No 0 29275. # ... with 9,990 more rows
Now let’s check for any NA values if you’ve dealt with NA values before you know that it’s best to get rid of them:
#Checking for NA values sum(is.na(mydata)) [1] 0
Lucky for us, there are no Null values in the data. The next step is to split the data into training and testing data set, this is also called Data Splicing.
#Creating the Training and Testing data set sample <- sample(c(TRUE, FALSE), nrow(mydata), replace = T, prob = c(0.6,0.4)) train <- mydata[sample, ] test <- mydata[!sample, ]
Here, we’re splitting the data in a proportion of 60:40, such that, 60% of the data is used for training and the remaining 40% is for testing the model.
After splitting the data, our next step is to use the training data set to build the logistic model. The logistic model tries to:
In order to build a logistic regression model, we’ll be using the glm() function. Logistic regression belongs to a class of models called the Generalized Linear Models (GLM) which can be built using the glm() function.
The syntax for a glm() function is:
glm(formula, data, family)
In the above syntax:
#Fitting a logistic regression model logmodel <- glm(default ~ balance, family = "binomial", data = train)
The glm() function uses the maximum likelihood method to compute the model.
This method determines the value of coefficients (βo, β1) in such a way that, the predicted probabilities are as close to the actual probabilities as possible. In simple terms, for a binary classification, the maximum likelihood estimator will try to find values of βo and β1 such that the resulting probabilities are closest to either 1 or 0. The likelihood function is represented as:

Maximum Likelihood Estimator – Logistic Regression In R – Edureka
After building the logistic model, we can now visualize the relationship between the response variable and the predictor variable. To do this we use the infamous ggplot library provided by R.
#Plotting a graph: Probability of default Vs Balance
mydata %>%
mutate(prob = ifelse(default == "Yes", 1, 0)) %>%
ggplot(aes(balance, prob)) +
geom_point(alpha = .15) +
geom_smooth(method = "glm", method.args = list(family = "binomial")) +
ggtitle("Logistic regression model fit") +
xlab("Balance") +
ylab("Probability of Default")
The result is an expected S curve or Sigmoid curve.

Logistic Regression Graph – Logistic Regression In R – Edureka
One of the most crucial steps in building a model is evaluating the efficiency and checking the significance of the model. We can evaluate the model by using the summary() function in R:
#Summary of the Logistic Regression Model summary(logmodel) Call: glm(formula = default ~ balance, family = "binomial", data = train) Deviance Residuals: Min 1Q Median 3Q Max -2.2905 -0.1395 -0.0528 -0.0189 3.3346 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -1.101e+01 4.887e-01 -22.52 <2e-16 *** balance 5.669e-03 2.949e-04 19.22 <2e-16 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 1723.03 on 6046 degrees of freedom Residual deviance: 908.69 on 6045 degrees of freedom AIC: 912.69 Number of Fisher Scoring iterations: 8
The above summary tells us a couple of things:
Pay close attention to the Pr(>|z|) or the p-value of the coefficients. A logistic regression model is said to be statistically significant only when the p-Values are less than the pre-determined statistical significance level, which is ideally 0.05. The p-value for each coefficient is represented as a probability Pr(>|z|).
We see here that both the coefficients have a very low p-value which means that both the coefficients are essential in computing the response variable.
The stars corresponding to the p-values indicate the significance of that respective variable. Since in our model, both the p values have a 3 star, this indicates that both the variables are extremely significant in predicting the response variable.
The above-mentioned measures are used to check the fitness of the logistic regression model, hence it is essential to pay attention to these values.
After training the model on the train data set, it is finally time to evaluate the model by using the test data set. In the below lines of code, we’ll use the logistic regression model that we built earlier, to predict the response variable (defaulter class(0/1)) on the test data.
#Fitting a logistic regression model on the testing data logmodel <- glm(default ~ balance, family = "binomial", data = test)
Now let’s take a look at the summary of the model:
summary(logmodel) Call: glm(formula = default ~ balance, family = "binomial", data = test) Deviance Residuals: Min 1Q Median 3Q Max -2.2021 -0.1574 -0.0676 -0.0272 3.6743 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -1.020e+01 5.372e-01 -18.98 <2e-16 *** balance 5.286e-03 3.329e-04 15.88 <2e-16 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 1197.10 on 3952 degrees of freedom Residual deviance: 685.05 on 3951 degrees of freedom AIC: 689.05 Number of Fisher Scoring iterations: 8
On studying the summary of the model, it is evident that both the coefficients are significant since their p-values are small and also the AIC and deviance values have dropped down when compared to the training phase, which is a good thing.
Our final step is to evaluate the efficiency of the model by making predictions on specific values of the predictor variable.
So, here we’re going to predict whether a customer with a balance of $2000 is going to be a defaulter or not. To do this we’ll be using the predict() function in R:
predict(logmodel, data.frame(balance = c(2000)), type = "response") 1 0.5820893
From the above result, it is clear that the customer belongs to Y=1 class and hence is a defaulter.
Now that you know how Logistic Regression works, I’m sure you’re curious to learn more about the various Machine learning algorithms. Here’s a list of blogs that covers the different types of Machine Learning algorithms in depth
With this, we come to the end of this Logistic Regression In R blog. I hope you found this blog informative, if you have any doubts, leave a comment and we’ll get back to you at the earliest.
Stay tuned for more blogs on the trending technologies.
If you are looking for online structured training in Data Science, edureka! has a specially curated Data Science course which helps you gain expertise in Statistics, Data Wrangling, Exploratory Data Analysis, Machine Learning Algorithms like K-Means Clustering, Decision Trees, Random Forest, Naive Bayes. You’ll learn the concepts of Time Series, Text Mining and an introduction to Deep Learning as well. New batches for this course are starting soon!!




































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Zulaikha Lateef, your way of explaining logistic regression and regression analysis is excellent. My daughter will find it very helpful for some of the projects she is handling. It is good to know that you also offer certifications in Data Science training.