
Advanced DevOps Certification Training with G ...
- 24k Enrolled Learners
- Weekend
- Live Class
(7990)





 Copy Link!
Copy Link!
Containers have become the definitive way to develop applications because they provide packages that contain everything you need to run your applications. In this blog, we will discuss Kubernetes architecture and the moving parts of Kubernetes and also what are the key elements, what are the roles and responsibilities of them in Kubernetes architecture.
Kubernetes is an open-source Container Management tool which automates container deployment, container (de)scaling & container load balancing.
 Written on Golang, it has a huge community because it was first developed by Google & later donated to CNCF
Written on Golang, it has a huge community because it was first developed by Google & later donated to CNCFIf you would favor a video explanation on Kubernetes Architecture, then you can go through the below video.
This video will give you an introduction to popular DevOps tool – Kubernetes, and will deep dive into Kubernetes Architecture and its working.
For a detailed explanation, check this blog.

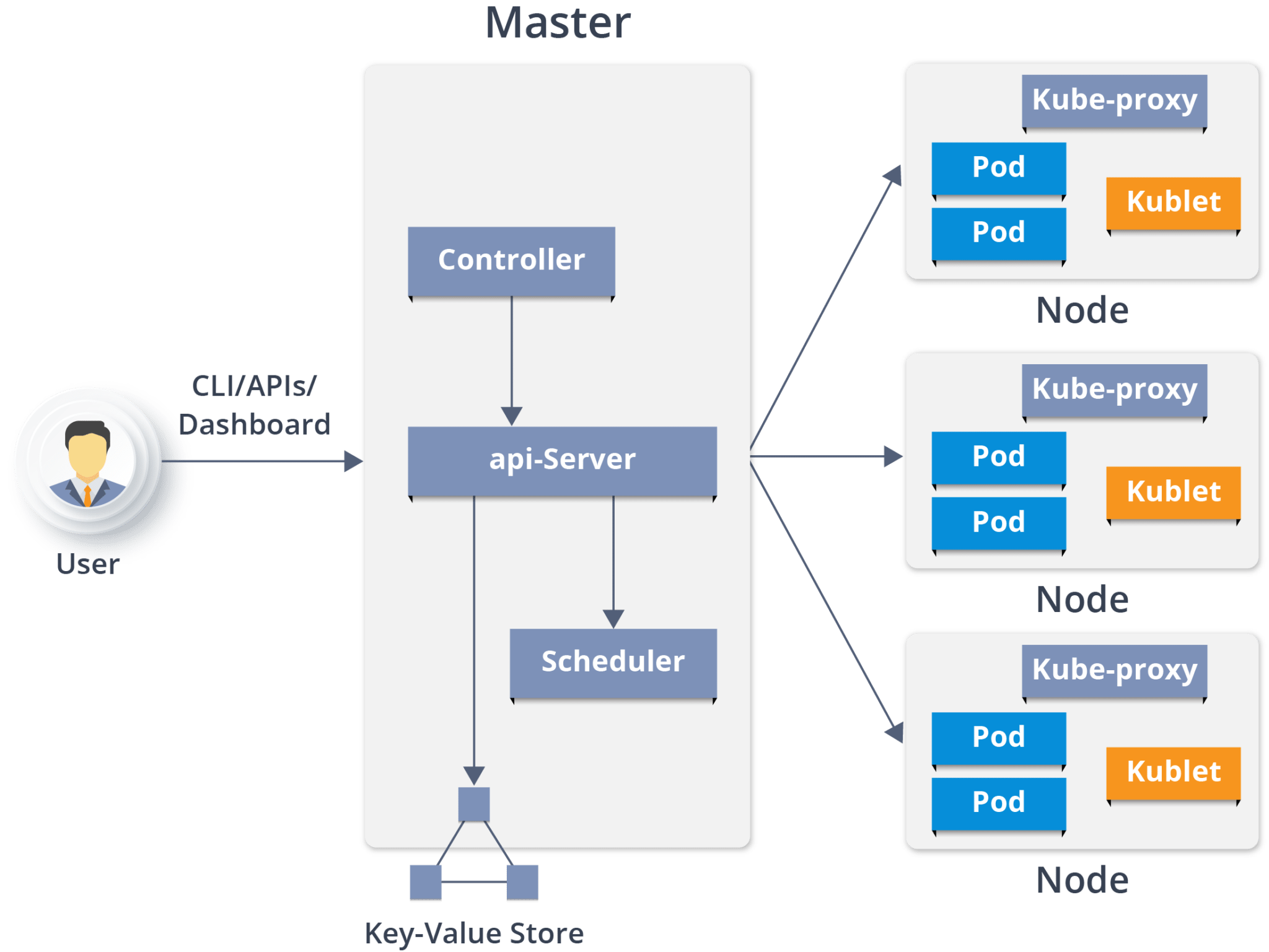 Kubernetes Architecture has the following main components:
Kubernetes Architecture has the following main components:
 It is the entry point for all administrative tasks which is responsible for managing the Kubernetes cluster. There can be more than one master node in the cluster to check for fault tolerance. More than one master node puts the system in a High Availability mode, in which one of them will be the main node which we perform all the tasks.
It is the entry point for all administrative tasks which is responsible for managing the Kubernetes cluster. There can be more than one master node in the cluster to check for fault tolerance. More than one master node puts the system in a High Availability mode, in which one of them will be the main node which we perform all the tasks.
For managing the cluster state, it uses etcd in which all the master nodes connect to it.
Let us discuss the components of a master node. As you can see in the diagram it consists of 4 components:
API server:
Scheduler:
Controller manager:
What is the ETCD?
Now you have understood the functioning of Master node. Let’s see what is the Worker/Minions node and its components.
Take the next step in your cloud & DevOps career by Enroll in our Docker and Kubernetes course.
 It is a physical server or you can say a VM which runs the applications using Pods (a pod scheduling unit) which is controlled by the master node. On a physical server (worker/slave node), pods are scheduled. For accessing the applications from the external world, we connect to nodes.
It is a physical server or you can say a VM which runs the applications using Pods (a pod scheduling unit) which is controlled by the master node. On a physical server (worker/slave node), pods are scheduled. For accessing the applications from the external world, we connect to nodes.
Let’s see what are the following components:
Container runtime:
Kubelet:
Kube-proxy:
A pod is one or more containers that logically go together. Pods run on nodes. Pods run together as a logical unit. So they have the same shared content. They all share the same IP address but can reach other Pods via localhost, as well as shared storage. Pods don’t need to all run on the same machine as containers can span more than one machine. One node can run multiple pods.
Problem: Luminis, a software technology company used AWS for deploying their applications. For deploying the applications, it required custom scripts and tools to automate which was not easy for teams other than operations. Their small teams didn’t have the resources to learn all of the details about the scripts and tools.
Main Issue: There was no unit-of-deployment which created a gap between the development and the operations teams.
Solution:
How did they Deploy in Kubernetes:
 They used a blue-green deployment mechanism to reduce the complexity of handling multiple concurrent versions. (As there’s always only one version of the application running in the background)
They used a blue-green deployment mechanism to reduce the complexity of handling multiple concurrent versions. (As there’s always only one version of the application running in the background)
In this, a component called “Deployer” that orchestrated the deployment was created by their team by open sourcing their implementation under the Apache License as part of the Amdatu umbrella project. This mechanism performed the health checking on the pods before re-configuring the load balancer because they wanted each component that was deployed to provide a health check.
How did they Automate Deployments?
 With the Deployer in place, they were able to engage up deployments to a build pipeline. After a successful build, their build server pushed a new Docker image to a registry on Docker Hub. Then the build server invoked the Deployer to automatically deploy the new version to a test environment. That same image was promoted to production by triggering the Deployer on the production environment.
With the Deployer in place, they were able to engage up deployments to a build pipeline. After a successful build, their build server pushed a new Docker image to a registry on Docker Hub. Then the build server invoked the Deployer to automatically deploy the new version to a test environment. That same image was promoted to production by triggering the Deployer on the production environment.
So, that’s the Kubernetes architecture in a simple fashion. So that brings an end to this blog on Kubernetes Architecture. Do look out for other blogs in this series which will explain the various other aspects of Kubernetes.
Got a question for us? Please mention it in the comments section and we will get back to you.

































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP