
Data Science with Python Certification Course
- 132k Enrolled Learners
- Weekend
- Live Class
(49300)





 Copy Link!
Copy Link!Supervised learning is an important aspect of Data Science. Supervised learning is the machine learning task of inferring a function from labelled training data. The training data consists of a set of training examples. In supervised learning, each example is a pair consisting of an input object (typically a vector) and a desired output value (also called the supervisory signal).
A Supervised Learning algorithm analyzes the training data and produces an inferred function, which can be used for mapping new examples. An optimal scenario will allow for the algorithm to correctly determine the class labels for unseen instances. This requires the learning algorithm to generalize from the training data to unseen situations in a “reasonable” way.
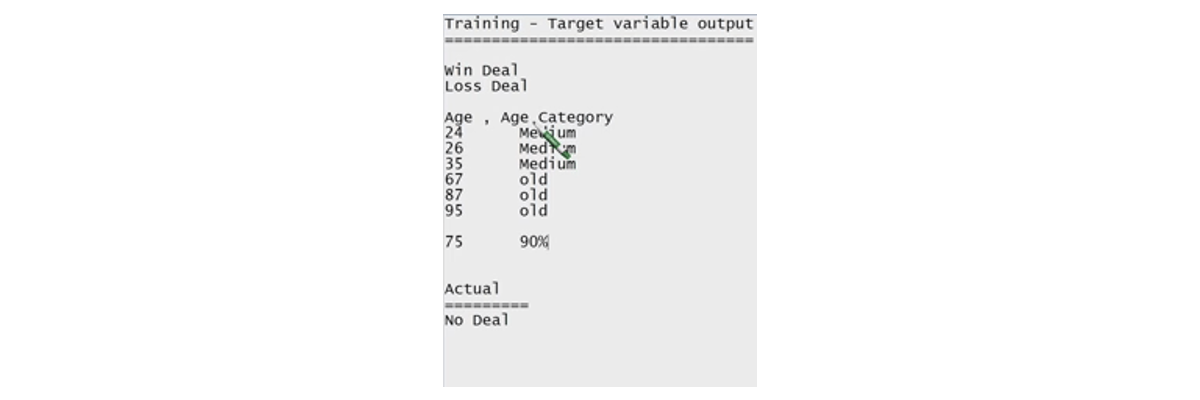
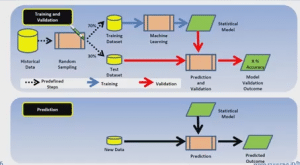
With the help of historical data, random sampling is carried out. Random sampling picks 70% and 30% of records. With 70%, the machine learning gets trained with the data. It is important to make sure the data is generalized and is not a specified one. Once the system is trained, it will provide a model (statistical model) which means that certain understanding has been attained from the data along with some formulas. Calculations will be the output of the modelling.
For instance, the brain has to be evaluated to check its functioning. Thirty per cent of the data has an input and output but when you give that to the model it will take only the independent variable and it calculates, giving the output. Hence, the model will give an output and you’re going to compare the brain predicted output and the actual value. Hence, the accuracy of percentage will be attained.
 If the brain grasps information, a person will be able to communicate the information well. If not, it will be a failure. Similarly, the data too has to be generic.
If the brain grasps information, a person will be able to communicate the information well. If not, it will be a failure. Similarly, the data too has to be generic.
Got a question for us?? Please mention them in the comments section and we will get back to you.
Related Posts:




































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP