





Big Data is a term for collection of data sets so large and complex that it becomes difficult to process using hands-on database management tools or traditional data processing applications. Let us talk more about this in this article on Introduction to Hadoop.
Big Data has now become a popular term to describe the explosion of data and Hadoop has become synonymous with Big Data. Doug Cutting, created Apache Hadoop for this very reason. Hadoop has now become the de facto standard for storing, processing and analyzing hundreds of terabytes, and even petabytes of data. Hadoop allows distributed parallel processing of huge amounts of data across inexpensive, industry-standard servers that store and process data.
The above video is the recorded session of the webinar on the topic “Introduction to Hadoop”, which was conducted on 8th August’14.
The above video covers the following topics in detail:
- What is Big Data
- Traditional Warehouse Vs Hadoop
- Why Should you Learn Hadoop and Related Technologies
- Jobs and Trends in Big Data
- Hadoop Architecture and Ecosystem
Presentation:
Why Should you Learn Hadoop & Related Technologies?
- Unstructured Data is Exploding – Digital universe has grown by 62% last year, to 800k petabytes and will grow further to 1.2 zettabytes by the end of this year.
- Big Data Challenges – Increasing volume of data from various sources with different data types are imposing huge challenges.
 Big Data Customer Scenarios:
Big Data Customer Scenarios:
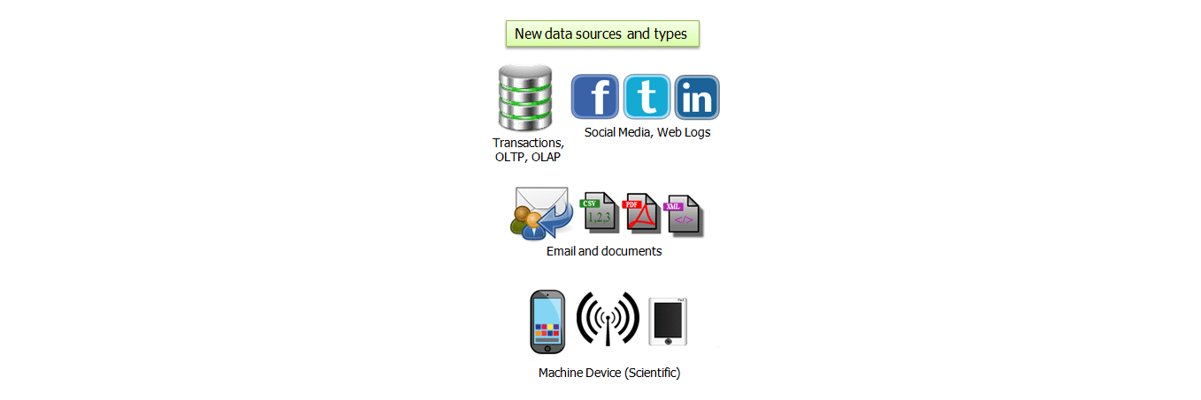 Big Data Customer Scenarios:
Big Data Customer Scenarios:Here are some use cases of Big Data in Retail, Banking and Financial sectors:
Banking and Financial Services:
- Modeling True Risk
- Threat Analysis
- Fraud Detection
- Trade Surveillance
- Credit Scoring and Analysis
Retail:
- Point of Sales Transaction Analysis
- Customer Churn Analysis
- Sentiment Analysis
Case Study:
This video includes a case study where the usage of Hadoop by Sears has been discussed. Sears was previously using traditional systems such as Oracle Exadata, Teradata and SAS to store and process the customer activity and sales data. On adapting Hadoop, Sears gained valuable advantages like :
- Insights in to data provided valuable business advantage
- Key early indicators that means fortune to business
- Precise analysis with more data
You can even check out the details of Big Data with the Data Engineering Course.
Find out our Big Data Hadoop Course in Top Cities
Limitations of Existing Data Analytics Architecture and How Hadoop Overcomes it:

The video has a step by step explanation of the flow of data and limitation faced by it in existing data analytics architecture and how Hadoop over comes it. Hadoop provides a solution where a combined storage computer layer is utilized. As a result, Sears moved to 300 node Hadoop cluster to keep 100% of its data for processing rather than the meager 10% that was available in the existing non-Hadoop solutions.
Moving on with this article on Introduction to Hadoop, let us take a look at why move towards Hadoop.
Here this Big Data Certification Training will explain to you more about tools and concepts with real-time project experience, which was well structured by Top Industry working Experts.
Why Move to Hadoop?
The following reasons make it pretty clear as to why one must move to Hadoop.
- Allows distributed processing of large sets of data across clusters of computers using simple programming model.
- Has become the de facto standard for storing, processing and analyzing hundreds of terabytes and petabytes of data.
- Cheaper to use, in comparison with other traditional proprietary technologies.
- Handles all types of data from disparate systems.
Hadoop – Growth and Job Opportunities:
“We’ve heard it’s a fad, heard it’s hyped and heard it’s fleeting, yet it’s clear that data professionals are in demand and well paid. Tech professionals who analyse large data streams and strategically impact the overall business goals of a firm have an opportunity to write their own ticket.” said Alice Hill, Managing Director of Dice.com.
The best way to become a Data Engineer is by getting the Azure Data Engineering Training in India.

As per the 2012-13 Salary Survey by Dice, a leading career site for technology and engineering professionals:
- Big Data jobs are having positive, disproportionate impact on salaries.
- Professionals with Hadoop, NoSQL and MongoD skills can earn more than $100,000
- Gartner Says Big Data will be creating 4.4 Million IT Jobs Globally to support Big Data, By 2015. Click here to know more about the demand for Hadoop.
Moving on with this article on Introduction to Hadoop, let us take a look at the Hadoop ecosystem and its architecture.
Hadoop Ecosystem & Architecture:

Hadoop comprises of two main components:
HDFS – Hadoop Distributed File System – For Storage
- Highly fault-tolerant
- High throughput access to application data
- Suitable for applications that have large data set
- Natively redundant
MapReduce – For Processing
- Software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) in a reliable, fault-tolerant manner
- Splits a task across processors





































So freshers can learn too…
i dont have knowledge on programming languages.
do i have to learn any programming lang to learn hadoop and big data
Absolutely Tharun!! People in their final years of education are considering learning Hadoop. Reason being, lots of companies are looking for freshers in Big Data space. The prerequisite for learning Hadoop is knowledge in Core Java. We provide a complementary course ‘Comprehensive Java’ along with ‘Big Data & Hadoop’ course. This will help you learn key concepts in Hadoop.
You can call us at US: 1800 275 9730 (Toll Free) or India: +91 88808 62004 for any clarifications. Please visit this link to know more about the course: https://www.edureka.co/big-data-hadoop-training-certification
how has been job growth been ,since march 2013
Hi Sumit, The current growth and the predicted growth of Hadoop is quite extraordinary. The technology is maturing beautifully with organizations implementing them on a lager scale. You can check out the following links to gain more clarity on this:
https://www.edureka.co/blog/big-prospects-for-big-data/
scope of hadoop in future?
Hi Rahul, a lot of companies are looking for freshers as well as experience professionals in Big Data space. what we are seeing as of now is just the beginning and there is a lot of potential for professionals who will be the early movers in Big Data space. The only prerequisite to learn Hadoop is core Java. You can refer to the following link to know more about the future prospects of Big Data: https://www.edureka.co/blog/big-prospects-for-big-data/
You can call us at US: 1800 275 9730 (Toll Free) or India: +91 88808 62004 to discuss in detail. You can also go through our website for further information: https://www.edureka.co/big-data-hadoop-training-certification
nice one
thanks
Nice Tutorial for learning
Thanks!! Feel free to go through our posts as well.
Nice Tutorial