HDFS Blocks
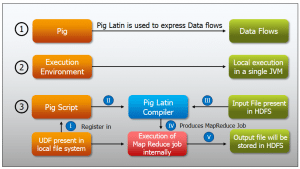
A file is always made up of blocks. When you talk of a file system it could be small, but when it comes to Hadoop the file is usually a big one. The file is split into multiple blocks based on the block size of the cluster. If it is 4 MB then any file that comes to the data node will be 64 MB blocks.
If the file was a 128 MB file or 256 MB file, it will have 4 MB blocks; which means the file will go into 4 blocks. If the replication factor is 1, there will be four blocks. As you see in the image, the blocks in blue, orange and green are based on replication and they end up being on data nodes depending where name node decides to place it. The name node is basically managing the complete file system.
A file system image (FsImage) is made up of the blocks in the system. All the data systems instruct their blocks when a data node comes up. It informs their blocks to name node about the availability of these blocks. As you can see in different data nodes, there are different colors. They are nothing but the blocks.
Then comes the EditLog. When there is a change made, like a file gets removed, changed or corrected, EditLogs come into the picture. Based on transactional logs there are EditLogs. If you need the complete file system at any point of time, look at the initial FsImage. The changes that were done to the file system go to the EditLogs. So if the FsImage is combined, all the EditLogs are there in the meta data directory. If the two are combined together, it will convey the file system status at a point of time. This is how the file system image is built.
Become a master of data architecture and shape the future with our comprehensive Big Data Architect Course.
HDFS Architecture

The client is the machine from where the Hadoop commands are running. File system commands the name node and hence, all the meta data operations to read and write the data comes from the client. The client contacts the name node and the name node stores the meta data, which means that all the files are aware of each data that has got replicated and what the blocks are made of. There are multiple racks having data nodes. When a client needs to read, it goes to name node and it gets the location of data nodes.
Similarly, when a client has to write, it talks to name node, gets the location and starts writing the blocks to the data node directly, without contacting the name node. The name node just instructs as to what has to be written and read. This is where the role of the name node comes to an end.
Got a question for us? Mention them in the comments section and we will get back to you.
Related Posts: