






There has never been a better time than this to explore a career around data warehousing, and with companies investing in tools like Informatica PowerCenter, there is a critical need for trained personnel to leverage these tools for better business insights. So we, at Edureka, have compiled a set of Question Answer type and Scenario based Informatica Interview questions, which will help you ace the Informatica interviews.
You can go through this Informatica Interview Questions video lecture where our expert is discussing the important question that can help you ace your interview.
Informatica Interview Questions and Answers for 2025 | Edureka
Informatica Interview Questions:
Over the years, the data warehousing ecosystem has changed. Data warehouses aren’t just bigger than a few years ago, they’re faster, support new data types, and serve a wider range of business-critical functions. But the most important change has been in their ability to provide actionable insights to enterprises and reshape the way companies look at innovation, competition and business outcomes. The fact that data warehousing is today one of the most critical components of an enterprise, has led to tremendous growth in job opportunities and roles. If you are exploring a job opportunity around Informatica, here is a list of Informatica interview questions that will help you crack your Informatica interview. However, if you have already taken an Informatica interview, or have more questions, we urge you to add them in the comments tab below to help the community at large.
1. What are the differences between connected lookup and unconnected lookup?
| Connected Lookup | Unconnected Lookup |
| 1. It receives input from the pipeline & participates in the data flow. | 1. It receives input from the result of an LKP. |
| 2. It can use both, dynamic and static cache. | 2. It can’t be dynamic. |
| 3. It can return more than one column value i.e. output port. | 3. It can return only one column value. |
| 4. It caches all lookup columns. | 4. It caches only the lookup output ports in the return port & lookup conditions. |
| 5. It supports user-defined default values. | 5. It doesn’t support user-defined default values. |
2. What is Lookup transformation?
- Lookup transformation is used to look up a source, source qualifier, or target in order to get relevant data.
- It is used to look up a ‘flat file’, ‘relational table’, ‘view’ or ‘synonym’.
- Lookup can be configured as Active or Passive as well as Connected or Unconnected transformation.
- When the mapping contains the lookup transformation, the integration service queries the lookup data and compares it with lookup input port values. One can use multiple lookup transformations in a mapping.
- The lookup transformation is created with the following type of ports:
- Input port (I)
- Output port (O)
- Look up Ports (L)
- Return Port (R)
3. How many input parameters can exist in an unconnected lookup?
Any number of input parameters can exist. For instance, you can provide input parameters like column 1, column 2, column 3, and so on. But the return value would only be one.
4. Name the different lookup cache(s)?
Informatica lookups can be cached or un-cached (no cache). Cached lookups can be either static or dynamic. A lookup cache can also be divided as persistent or non-persistent based on whether Informatica retains the cache even after completing session run or if it deletes it.
- Static cache
- Dynamic cache
- Persistent cache
- Shared cache
- Recache
5. Is ‘sorter’ an active or passive transformation?
It is an active transformation because it removes the duplicates from the key and consequently changes the number of rows.
6. What are the various types of transformation?
- Aggregator transformation
- Expression transformation
- Filter transformation
- Joiner transformation
- Lookup transformation
- Normalizer transformation
- Rank transformation
- Router transformation
- Sequence generator transformation
- Stored procedure transformation
- Sorter transformation
- Update strategy transformation
- XML source qualifier transformation
7. What is the difference between active and passive transformation?
Active Transformation:- An active transformation can perform any of the following actions:
- Change the number of rows that pass through the transformation: For instance, the Filter transformation is active because it removes rows that do not meet the filter condition.
- Change the transaction boundary: For e.g., the Transaction Control transformation is active because it defines a commit or roll back transaction based on an expression evaluated for each row.
- Change the row type: For e.g., the Update Strategy transformation is active because it flags rows for insert, delete, update, or reject.
Passive Transformation: A passive transformation is one which will satisfy all these conditions:
- Does not change the number of rows that pass through the transformation
- Maintains the transaction boundary
- Maintains the row type
8. Name the output files created by Informatica server during session running.
- Informatica server log: Informatica server (on UNIX) creates a log for all status and error messages (default name: pm.server.log). It also creates an error log for error messages. These files will be created in the Informaticahome directory.
- Session log file: Informatica server creates session log files for each session. It writes information about sessions into log files such as initialization process, creation of SQL commands for reader and writer threads, errors encountered and load summary. The amount of detail in the session log file depends on the tracing level that you set.
- Session detail file: This file contains load statistics for each target in mapping. Session detail includes information such as table name, number of rows written or rejected. You can view this file by double clicking on the session in the monitor window.
- Performance detail file: This file contains session performance details which tells you where performance can be improved. To generate this file, select the performance detail option in the session property sheet.
- Reject file: This file contains the rows of data that the writer does not write to targets.
- Control file: Informatica server creates a control file and a target file when you run a session that uses the external loader. The control file contains the information about the target flat file such as data format and loading instructions for the external loader.
- Post session email: Post session email allows you to automatically communicate information about a session run to designated recipients. You can create two different messages. One if the session completed successfully and another if the session fails.
- Indicator file: If you use the flat file as a target, you can configure the Informatica server to create an indicator file. For each target row, the indicator file contains a number to indicate whether the row was marked for insert, update, delete or reject.
- Output file: If a session writes to a target file, the Informatica server creates the target file based on file properties entered in the session property sheet.
- Cache files: When the Informatica server creates a memory cache, it also creates cache files. For the following circumstances, Informatica server creates index and data cache files.
9. How do you differentiate dynamic cache from static cache?
The differences are shown in the table below:
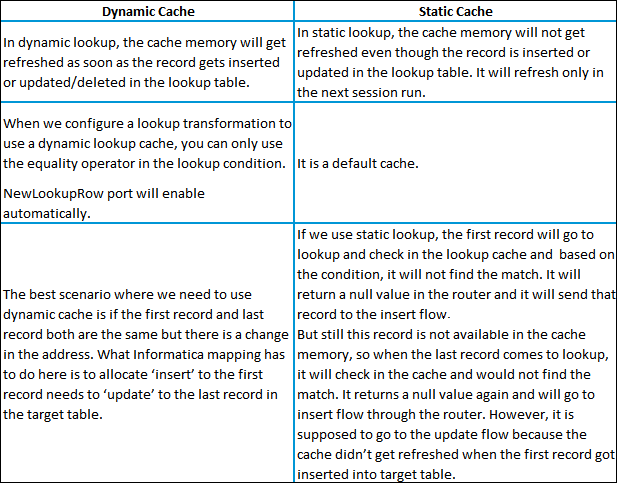
10. What are the types of groups in router transformation?
- Input group
- Output group
- Default group
11. What is the difference between STOP and ABORT options in Workflow Monitor?
On issuing the STOP command on the session task, the integration service stops reading data from the source although it continues processing the data to targets. If the integration service cannot finish processing and committing data, we can issue the abort command.
ABORT command has a timeout period of 60 seconds. If the integration service cannot finish processing data within the timeout period, it kills the DTM process and terminates the session
12. How can we store previous session logs?
If you run the session in the time stamp mode then automatically session log out will not overwrite the current session log.
Go to Session Properties –> Config Object –> Log Options
Select the properties as follows:
Save session log by –> SessionRuns
Save session log for these runs –> Change the number that you want to save the number of log files (Default is 0)
If you want to save all of the log files created by every run, and then select the option Save session log for these runs –> Session TimeStamp
You can find these properties in the session/workflow Properties.
13. What are the similarities and differences between ROUTER and FILTER?
The differences are:

Advantages of Router transformation over Filter transformation:
- Better Performance; because in mapping, the Router transformation Informatica server processes the input data only once instead of as many times, as you have conditions in Filter transformation.
- Less complexity; because we use only one Router transformation instead of multiple Filter transformations.
- Router transformation is more efficient than Filter transformation.
For E.g.:
Imagine we have 3 departments in source and want to send these records into 3 tables. To achieve this, we require only one Router transformation. In case we want to get same result with Filter transformation then we require at least 3 Filter transformations.
Similarity:
A Router and Filter transformation are almost same because both transformations allow you to use a condition to test data.
14. Why is sorter an active transformation?
When the Sorter transformation is configured to treat output rows as distinct, it assigns all ports as part of the sort key. The integration service discards duplicate rows that were compared during the sort operation. The number of input rows will vary as compared to the output rows and hence it is an active transformation.
15. When do you use SQL override in a lookup transformation?
You should override the lookup query in the following circumstances:
- Override the ORDER BY clause. Create the ORDER BY clause with fewer columns to increase performance. When you override the ORDER BY clause, you must suppress the generated ORDER BY clause with a comment notation.
Note: If you use pushdown optimization, you cannot override the ORDER BY clause or suppress the generated ORDER BY clause with a comment notation. - A lookup table name or column names contains a reserved word. If the table name or any column name in the lookup query contains a reserved word, you must ensure that they are enclosed in quotes.
- Use parameters and variables. Use parameters and variables when you enter a lookup SQL override. Use any parameter or variable type that you can define in the parameter file. You can enter a parameter or variable within the SQL statement, or use a parameter or variable as the SQL query. For example, you can use a session parameter, $ParamMyLkpOverride, as the lookup SQL query, and set $ParamMyLkpOverride to the SQL statement in a parameter file. The designer cannot expand parameters and variables in the query override and does not validate it when you use a parameter or variable. The integration service expands the parameters and variables when you run the session.
- A lookup column name contains a slash (/) character. When generating the default lookup query, the designer and integration service replace any slash character (/) in the lookup column name with an underscore character. To query lookup column names containing the slash character, override the default lookup query, replace the underscore characters with the slash character, and enclose the column name in double quotes.
- Add a WHERE clause. Use a lookup SQL override to add a WHERE clause to the default SQL statement. You might want to use the WHERE clause to reduce the number of rows included in the cache. When you add a WHERE clause to a Lookup transformation using a dynamic cache, use a Filter transformation before the Lookup transformation to pass rows into the dynamic cache that match the WHERE clause.
Note: The session fails if you include large object ports in a WHERE clause. - Other. Use a lookup SQL override if you want to query lookup data from multiple lookups or if you want to modify the data queried from the lookup table before the Integration Service caches the lookup rows. For example, use TO_CHAR to convert dates to strings.
16. What are data driven sessions?
When you configure a session using update strategy, the session property data driven instructs Informatica server to use the instructions coded in mapping to flag the rows for insert, update, delete or reject. This is done by mentioning DD_UPDATE or DD_INSERT or DD_DELETE in the update strategy transformation.
“Treat source rows as” property in session is set to “Data Driven” by default when using a update strategy transformation in a mapping.
17. What are mapplets?
18. What is the difference between Mapping and Mapplet?
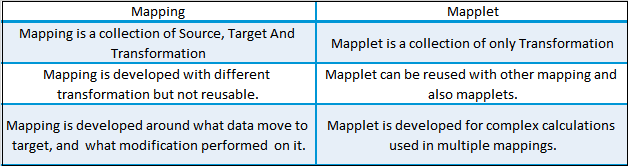
19. How can we delete duplicate rows from flat files?
We can make use of sorter transformation and select distinct option to delete the duplicate rows.
20. What is the use of source qualifier?
The source qualifier transformation is an active, connected transformation used to represent the rows that the integrations service reads when it runs a session. You need to connect the source qualifier transformation to the relational or flat file definition in a mapping. The source qualifier transformation converts the source data types to the Informatica native data types. So, you should not alter the data types of the ports in the source qualifier transformation.
The source qualifier transformation can be used to perform the following tasks:
- Joins: You can join two or more tables from the same source database. By default, the sources are joined based on the primary key-foreign key relationships. This can be changed by explicitly specifying the join condition in the “user-defined join” property.
- Filter rows: You can filter the rows from the source database. The integration service adds a WHERE clause to the default query.
- Sorting input: You can sort the source data by specifying the number for sorted ports. The integration service adds an ORDER BY clause to the default SQL query
- Distinct rows: You can get distinct rows from the source by choosing the “Select Distinct” property. The integration service adds a SELECT DISTINCT statement to the default SQL query.
- Custom SQL Query: You can write your own SQL query to do calculations.
21. What are the different ways to filter rows using Informatica transformations?
- Source Qualifier
- Joiner
- Filter
- Router
22. What are the different transformations where you can use a SQL override?
- Source Qualifier
- Lookup
- Target
23. Why is it that in some cases, SQL override is used?
The Source Qualifier provides the SQL Query option to override the default query. You can enter any SQL statement supported by your source database. You might enter your own SELECT statement, or have the database perform aggregate calculations, or call a stored procedure or stored function to read the data and perform some tasks.
24. State the differences between SQL Override and Lookup Override?
- The role of SQL Override is to limit the number of incoming rows entering the mapping pipeline, whereas Lookup Override is used to limit the number of lookup rows to avoid the whole table scan by saving the lookup time and the cache it uses.
- Lookup Override uses the “Order By” clause by default. SQL Override doesn’t use it and should be manually entered in the query if we require it
- SQL Override can provide any kind of ‘join’ by writing the query
Lookup Override provides only Non-Equi joins. - Lookup Override gives only one record even if it finds multiple records for a single condition
SQL Override doesn’t do that.
If you want to get hands-on learning on Informatica, you can also check out the tutorial given below. In this tutorial, you will learn about Informatica Architecture, Domain & Nodes in Informatica, and other related concepts.
25. What is parallel processing in Informatica?
After optimizing the session to its fullest, we can further improve performance by exploiting under utilized hardware power. This refers to parallel processing and we can achieve this in Informatica Powercenter using Partitioning Sessions.
The Informatica Powercenter Partitioning Option increases the performance of the Powercenter through parallel data processing. The Partitioning option will let you split the large data set into smaller subsets which can be processed in parallel to get a better session performance.
26. What are the different ways to implement parallel processing in Informatica?
We can implement parallel processing using various types of partition algorithms:
Database partitioning: The Integration Service queries the database system for table partition information. It reads partitioned data from the corresponding nodes in the database.
Round-Robin Partitioning: Using this partitioning algorithm, the Integration service distributes data evenly among all partitions. It makes sense to use round-robin partitioning when you need to distribute rows evenly and do not need to group data among partitions.
Hash Auto-Keys Partitioning: The Powercenter Server uses a hash function to group rows of data among partitions. When the hash auto-key partition is used, the Integration Service uses all grouped or sorted ports as a compound partition key. You can use hash auto-keys partitioning at or before Rank, Sorter, and unsorted Aggregator transformations to ensure that rows are grouped properly before they enter these transformations.
Hash User-Keys Partitioning: Here, the Integration Service uses a hash function to group rows of data among partitions based on a user-defined partition key. You can individually choose the ports that define the partition key.
Key Range Partitioning: With this type of partitioning, you can specify one or more ports to form a compound partition key for a source or target. The Integration Service then passes data to each partition depending on the ranges you specify for each port.
Pass-through Partitioning: In this type of partitioning, the Integration Service passes all rows from one partition point to the next partition point without redistributing them.
27. What are the different levels at which performance improvement can be performed in Informatica?
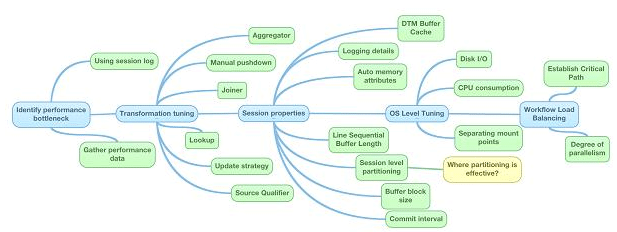
28. Mention a few design and development best practices for Informatica.
Mapping design tips:Standards – sticking to consistent standards is beneficial in the long run. This includes naming conventions, descriptions, environment settings, parameter files, documentation, among others.
- Reusability – in order to react quickly to potential changes, use Informatica components like mapplets, worklets, and reusable transformations.
- Scalability – when designing and developing mappings, it is a good practice to keep volumes in mind. This is caching, queries, partitioning, initial vs incremental loads.
- Simplicity – it is recommended to create multiple mappings instead of few complex ones. Use Staging Area and try to keep the processing logic as clear and simple as possible.
- Modularity – use the modular design technique (common error handling, reprocessing).
Mapping development best practices
- Source Qualifier – use shortcuts, extract only the necessary data, limit read of columns and rows on source. Try to use the default query options (User Defined Join, Filter) instead of using SQL Query override which may impact database resources and make unable to use partitioning and push-down.
- Expressions – use local variables to limit the amount of redundant calculations, avoid datatype conversions, reduce invoking external scripts (coding outside of Informatica), provide comments, use operators (||, +, /) instead of functions. Keep in mind that numeric operations are generally faster than string operations.
- Filter – use the Filter transformation as close to the source as possible. If multiple filters need to be applied, usually it’s more efficient to replace them with Router.
- Aggregator – use sorted input, also use as early (close to the source) as possible and filter the data before aggregating.
- Joiner – try to join the data in Source Qualifier wherever possible, and avoid outer joins. It is good practice to use a source with fewer rows, such as a Master source.
- Lookup – relational lookup should only return ports that meet the condition. Call Unconnected Lookup in expression (IIF). Replace large lookup tables with joins whenever possible. Review the database objects and add indexes to database columns when possible. Use Cache Calculator in session to eliminate paging in lookup cache.
29. What are the different types of profiles in Informatica?
30. Explain shared cache and re cache.
To answer this question, it is essential to understand persistence cache. If we are performing lookup on a table, it looks up all the data brings it inside the data cache. However, at the end of each session, the Informatica server deletes all the cache files. If you configure the lookup as a persistent cache, the server saves the lookup under an anonymous name. Shared cache allows you to use this cache in other mappings by directing it to an existing cache.
- Differentiate between Informatica and DataStage.
Informatica and IBM InfoSphere DataStage are both popular data integration and ETL (Extract, Transform, Load) tools used in the field of data management. They serve similar purposes but have differences in their features, capabilities, and underlying architectures. Here’s a comparison between the two:
| Aspect | Informatica | IBM InfoSphere DataStage |
|---|---|---|
| Vendor | Informatica Corporation | IBM (International Business Machines Corporation) |
| Features and Capabilities | Comprehensive ETL, data integration, data profiling, data quality, data governance, master data management | ETL, data transformation, data quality, parallel processing |
| Scalability | Scalable for large volumes of data | Scalable with emphasis on parallel processing |
| User Interface | User-friendly drag-and-drop interface | Visual interface with a steeper learning curve for business users |
| Integration | Wide range of connectors and integration options | Integrates well with other IBM products and technologies |
| Deployment Options | On-premises and cloud-based options | On-premises and cloud deployment options |
| Market Presence | Widely recognized and used in the industry | Strong market presence, particularly among existing IBM users |
- What is Informatica PowerCenter?
Informatica PowerCenter is a widely-used enterprise data integration and ETL (Extract, Transform, Load) tool developed by Informatica Corporation. It serves as a comprehensive data integration platform that allows organizations to efficiently and securely move, transform, and manage large volumes of data across various systems, applications, and platforms.
Key features and components of Informatica PowerCenter include:
- ETL Capabilities: PowerCenter facilitates the extraction of data from multiple sources, its transformation based on business rules, and the loading of transformed data into target systems, such as data warehouses, databases, and cloud storage.
- Data Profiling and Quality: PowerCenter includes tools for data profiling, which enables the assessment and analysis of data quality, consistency, and completeness. It helps identify data issues and anomalies.
- Data Governance: The platform supports data governance initiatives by providing data lineage, impact analysis, and metadata management capabilities. This helps ensure data accuracy, compliance, and accountability.
- Data Integration: PowerCenter supports integration with a wide range of data sources and destinations, including relational databases, cloud services, flat files, mainframes, and more.
- Scalability: PowerCenter is designed to handle large-scale data integration projects, making it suitable for enterprises with diverse data integration needs.
- Connectivity: The tool provides a variety of connectors and adapters to connect with different data sources, applications, and systems, facilitating seamless data movement.
- Workflow Automation: PowerCenter enables the creation of workflows to orchestrate and schedule data integration tasks. This automation enhances efficiency and reduces manual intervention.
- Transformation: PowerCenter offers a wide range of transformation functions for data cleansing, enrichment, aggregation, and more. Users can design and customize transformations based on specific business requirements.
- Performance Optimization: The platform includes features like pushdown optimization, parallel processing, and caching to enhance data processing speed and efficiency.
- Monitoring and Management: PowerCenter provides monitoring and management tools to track job execution, manage resources, and troubleshoot issues in real-time.
Informatica PowerCenter is widely used across industries to address data integration challenges, streamline business processes, and enable data-driven decision-making. It has become a go-to solution for organizations seeking a robust and flexible platform to manage their data integration and ETL requirements.
- Mention some use cases of Informatica.
Certainly, here are some additional use cases of Informatica:
- Regulatory Compliance: Informatica is used to ensure compliance with data protection regulations like GDPR (General Data Protection Regulation) by managing and securing personal data.
- Data Governance: Organizations employ Informatica to establish data governance frameworks, defining data ownership, quality standards, and policies to ensure data accuracy and consistency.
- Data Integration for Mergers and Acquisitions: During mergers or acquisitions, Informatica helps integrate data from disparate systems, ensuring a smooth transition and consolidation of data.
- Logistics and Transportation: Informatica aids in integrating data from different logistics systems, optimizing routes, tracking shipments, and enhancing overall supply chain efficiency.
- Energy and Utilities: Informatica is used to integrate data from various sources in the energy sector, such as smart meters and sensors, to monitor energy consumption and optimize distribution.
- Media and Entertainment: Informatica supports media companies in managing content, metadata, and distribution data across different platforms and channels.
- Education Institutions: Educational institutions use Informatica to integrate student data, course information, and administrative records for effective management.
- Government Services: Informatica helps government agencies integrate and manage citizen data, improving service delivery and enhancing data accuracy.
- Manufacturing: Informatica assists in integrating data from production lines, sensors, and manufacturing systems, optimizing processes and improving overall productivity.
- Pharmaceuticals: In the pharmaceutical industry, Informatica aids in integrating data from clinical trials, research databases, and regulatory systems for efficient drug development and compliance.
- Insurance: Informatica is used to integrate customer information, policy data, and claims data, enabling insurers to provide better services and risk assessment.
- Hospitality and Travel: Informatica helps integrate booking data, customer preferences, and loyalty program information, enhancing customer experiences in the hospitality sector.
- Agriculture: In the agriculture industry, Informatica assists in integrating data from sensors, weather forecasts, and crop management systems to optimize farming practices.
- Automotive: Automotive companies use Informatica to integrate data from production lines, supply chains, and customer feedback systems to enhance quality control and innovation.
- Non-profit Organizations: Informatica helps non-profits integrate donor information, program data, and fundraising records for improved donor relationship management.
These use cases illustrate the versatility of Informatica across a wide range of industries and sectors, showcasing its ability to address diverse data integration and management challenges.
- In Informatica Workflow Manager, how many repositories can be created?
You can build multiple repositories in Informatica Workflow Manager to organize and handle your ETL (Extract, Transform, Load) workflows and related items. There is no hard limit on how many repositories you can make, but it usually relies on your Informatica license and the hardware tools you have to host the repositories.
Each repository is its own area where workflows, maps, sessions, and other related items can be made, saved, and managed. You could make multiple folders to keep projects, teams, or settings separate. But the number of folders you can make may depend on how your Informatica system is licensed and how much space it has.
When choosing how many sources to make, it’s important to think about the organization’s needs, security needs, and speed. If you work in a setting with more than one team or have more than one project, making separate repositories can help keep things organized and easy to handle. For the best ways to handle a repository, you should look at the official instructions from Informatica and the rules from your company.
- How do pre- and post-session shell commands function?
In Informatica PowerCenter, pre-session and post-session shell commands are custom commands that you can execute before and after a session runs within a workflow. These commands allow you to perform specific actions outside the scope of the session itself, such as preparing the environment, cleaning up resources, or logging information.
Here’s how pre-session and post-session shell commands function:
Pre-Session Shell Command:
- Configuration: In the workflow, when you define a session, you can specify a pre-session shell command. This command is defined in the session properties and is executed before the session begins its execution.
- Purpose: Pre-session shell commands are often used to set up the environment for the session. This can include tasks like initializing variables, clearing temporary files, or connecting to external resources.
- Execution: Just before the session starts running, the Informatica server executes the pre-session shell command. It’s a script or command that you provide, and you can include any necessary commands or logic within it.
Post-Session Shell Command:
- Configuration: Similar to the pre-session command, you can specify a post-session shell command in the session properties. This command is executed after the session completes its execution.
- Purpose: Post-session shell commands are used for actions that need to take place after the session runs. This can include tasks like generating reports, archiving logs, or triggering notifications.
- Execution: After the session has finished running, the Informatica server immediately executes the post-session shell command. Like the pre-session command, you can include custom commands or scripts to perform the desired actions.
Usage:
– You can use pre-session and post-session shell commands to customize and extend the functionality of your ETL processes.
– These commands can be written in various scripting languages like Unix Shell Script, Windows Batch Script, or any language supported by the execution environment.
Considerations:
– When using shell commands, ensure that the environment and permissions are set correctly to execute the desired actions.
– Be cautious with these commands, as they run outside the scope of the actual ETL logic. Incorrect commands can lead to unexpected results or errors.
Overall, pre-session and post-session shell commands provide a way to integrate external actions into your ETL workflows, enhancing the overall automation and management of your data integration processes.
- What can we do to improve the performance of Informatica Aggregator transformation?
To enhance the performance of Informatica Aggregator transformations, you can employ several optimization techniques. These strategies aim to streamline data processing and minimize resource usage. Here are some ways to improve the performance of the Aggregator transformation:
- Sort Data: If possible, sort the data before it enters the Aggregator transformation. Sorting data beforehand improves the efficiency of grouping and aggregation processes.
- Minimize Input Rows: Filter out irrelevant rows from the input data using filters and routers. This reduces the data volume entering the Aggregator.
- Use Sorted Ports for Grouping: If your data is already sorted, utilize ports with “sorted” attributes for grouping. This speeds up group processing.
- Simplify Expressions: Reduce the use of complex expressions within the Aggregator transformation, as these can slow down processing.
- Limit Grouping Ports: Only use necessary grouping ports to avoid unnecessary memory usage.
- Aggregator Cache: Utilize the Aggregator cache to store intermediate results and minimize data processing repetition.
- Enable Aggregator Sorted Input: If the data isn’t pre-sorted, enable the “Aggregator Sorted Input” option to sort data within the transformation.
- Parallel Processing: Leverage partitioning and parallel processing to distribute workloads across multiple resources, if feasible.
- Memory Allocation: Adjust memory settings in session properties to allocate adequate memory for the Aggregator transformation.
- Source Indexes and Partitioning: Consider using indexes and partitioning in the source database for efficient data retrieval.
- Pushdown Optimization: If supported, use pushdown optimization to perform some aggregation operations directly within the source database.
- Persistent Cache: For large datasets, implement persistent cache to store aggregated data across sessions, minimizing recalculations.
- Regular Monitoring: Monitor session logs and performance metrics to identify performance bottlenecks and areas for optimization.
- Test Different Configurations: Test various configurations to determine the most effective settings for your specific environment.
- Aggregate at Source: Whenever possible, perform aggregations at the source database level before data extraction.
- Use Aggregator Expressions Wisely: Use built-in aggregate functions rather than custom expressions whenever feasible.
- Avoid Unnecessary Ports: Remove any unused input/output ports from the Aggregator transformation.
- Properly Define Ports: Ensure that the “precision” and “scale” properties of output ports are appropriately defined to minimize data type conversions.
- Session-Level Recovery: Enable session-level recovery to resume a session from the point of failure, minimizing reprocessing.
Implementing a combination of these techniques based on your specific use case can significantly improve the performance of your Informatica Aggregator transformations and overall ETL processes.
- How can we update a record in the target table without using Update Strategy?
To update records in the target table without using the Update Strategy transformation in Informatica, you can use the “Update” option available in the Target Designer. This approach is suitable when you want to update existing records in the target table based on certain conditions. Here’s how you can achieve this:
- Using the Target Designer:
– Open the Target Designer in Informatica.
– Edit the target table definition.
– In the “Keys” tab, specify the primary key or unique key columns that will be used to identify records for updates.
– In the “Update as Update” option, select the columns that you want to update in the target table.
– Save the target definition.
- In the Mapping:
– In your mapping, ensure that you are using the same primary key or unique key columns in the source that match the key columns defined in the target.
– Connect the source to the target, passing data through transformations as needed.
– The mapping will pass data to the target table, and during the session run, Informatica will compare the source data with the target data using the defined key columns.
– Records with matching keys will be updated in the target table based on the columns you specified in the “Update as Update” option.
- In the Session:
– Open the session properties.
– In the “Mapping” tab, make sure the target table is linked to the correct target definition.
– In the “Properties” tab, ensure the “Target Load Plan” is set to “Normal” or “Update.”
– Save the session properties.
By configuring the target definition and session properties as described above, Informatica will automatically handle the update operation for you based on the matching keys. This method is effective when you want to perform updates without explicitly using the Update Strategy transformation. However, it’s essential to thoroughly test this approach to ensure it aligns with your data update requirements and produces the desired results.
- Why do we use mapping parameters and mapping variables?
Mapping parameters and mapping variables are essential components in Informatica that enable you to add flexibility, reusability, and dynamic behavior to your ETL processes. They serve different purposes and are used in various scenarios:
Mapping Parameters:
- Dynamic Configuration: Mapping parameters allow you to pass values dynamically to a mapping during runtime. This is useful when you need to provide different parameter values for each session run, such as source file paths, target table names, or database connection information.
- Reusability: By using mapping parameters, you can create reusable mappings that can be configured differently for different tasks or environments without modifying the mapping itself.
- Change Impact Management: If a source or target changes, you can update the parameter value instead of modifying the mapping, reducing the impact of changes.
- Session Overrides: Mapping parameters can be overridden at the session level, giving you control to adjust values specifically for each session run.
- Globalization and Localization: Mapping parameters can be used to accommodate language or country-specific variations without altering the mapping structure.
Mapping Variables:
- Calculations and Transformations: Mapping variables allow you to perform calculations and transformations within a mapping. You can use them to calculate derived values, perform conditional logic, or manipulate data.
- Change Data Capture: Mapping variables can be used to capture changes in data or to track row counts, which can be important for auditing purposes.
- Custom Expressions: Mapping variables can be used to create custom expressions, enhancing the mapping’s functionality beyond built-in transformations.
- Session-Level Operations: Mapping variables can be referenced in session tasks to control session behavior dynamically. For example, you can use them to generate dynamic file names or log messages.
- Looping and Iterations: Mapping variables can be used in iterative processes, allowing you to perform actions repetitively while incrementing or modifying the variable value.
In summary, mapping parameters and mapping variables are essential tools for making your Informatica mappings adaptable, reusable, and capable of handling dynamic scenarios. They provide a way to externalize configuration details, perform calculations, and enable dynamic behavior without altering the underlying mapping structure.
- Define the Surrogate Key.
A surrogate key is a unique identifier assigned to each record in a database table. It ensures uniqueness and simplifies data management. Unlike natural keys, surrogate keys lack real-world meaning and are often integers. They enhance data integrity, aid in efficient joins, and are valuable in data warehousing and integration.
- Explain sessions and shed light on how batches are used to combine executions.
In the context of Informatica PowerCenter, a session is a unit of work that represents the execution of a single ETL (Extract, Transform, Load) job. It includes all parts of the data processing flow, such as getting data from source systems, changing it, and putting it into target systems. Sessions are important parts of a process, and the PowerCenter process Manager is used to coordinate them.
Key Components of a Session:
- Mapping: A session is associated with a mapping, which defines the transformation logic applied to source data to generate target data.
- Source and Target Definitions: Source definitions define the structure of source data, while target definitions specify the structure of the destination or target data.
- Session Properties: These properties configure various aspects of the session, including connections, transformation settings, error handling, performance tuning, and recovery strategies.
- Workflow Integration: Sessions are often integrated into workflows, enabling the orchestration of multiple tasks within a coherent ETL process.
Batches in Sessions:
Batches are used in sessions to make sure that big files are processed as quickly as possible. Instead of handling all the data at once, batches break the data up into smaller pieces that are easier to handle. This method improves speed, resource use, and the way memory is handled. Batching is especially helpful when working with a lot of data to make sure everything runs smoothly and keep the system from getting too busy.
How Batches are Used:
- Partitioning: Batching is often used in conjunction with data partitioning. The data is divided into partitions, and each partition is processed as a separate batch.
- Memory Efficiency: Batching prevents excessive memory consumption by processing a subset of data at a time. This is crucial for maintaining system stability and performance.
- Scalability: Batching facilitates scalability by allowing the system to efficiently handle large datasets, as each batch can be processed individually.
- Parallel Processing: Batching enables parallelism by processing multiple batches simultaneously, leveraging the available hardware resources.
- Error Isolation: If errors occur within a batch, they can be contained and addressed without affecting the entire dataset.
- Commit Points: Batching introduces commit points at the end of each batch, ensuring data integrity and recoverability in case of failures.
- Optimized Resource Utilization: Batching helps manage resources effectively and mitigates potential bottlenecks by controlling the data flow.
In conclusion, sessions in Informatica PowerCenter encompass the execution of ETL tasks, while batches are utilized within sessions to enhance the processing of large datasets. Batching improves memory usage, scalability, parallelism, error management, and overall ETL performance. It’s an essential technique for maintaining efficient data processing and ensuring the stability of the ETL environment.
- What is incremental aggregation?
Incremental aggregation is a technique used in data warehousing and ETL (Extract, Transform, Load) processes to efficiently update aggregated data without recalculating the entire dataset. Instead of processing all the source data, incremental aggregation focuses on processing only the new or changed data since the last aggregation run. This approach reduces processing time and resource usage, making it particularly useful for large datasets.
- What are the features of Informatica Developer 9.1.0?
Informatica Developer 9.1.0 is a powerful tool for data integration. It provides a variety of features that make it easy to extract, transform, and load data from a variety of sources.
Here are some of the key features of Informatica Developer 9.1.0:
- Enhanced user interface: The user interface has been redesigned to be more intuitive and user-friendly.
- New wizards: A number of new wizards have been added to make it easier to create and manage data integration projects.
- Improved performance: Informatica Developer 9.1.0 has been optimized for performance, so it can handle larger and more complex data sets.
- New features: A number of new features have been added, such as the ability to create and manage data profiles, the ability to use machine learning to improve data quality, and the ability to integrate with cloud-based services.
Here are some specific examples of the new features in Informatica Developer 9.1.0:
- Data profiling: You can now create and manage data profiles in Informatica Developer. Data profiles can help you to understand the quality of your data and identify any potential problems.
- Machine learning: You can now use machine learning to improve the quality of your data in Informatica Developer. Machine learning can help you to identify and correct errors in your data, and it can also help you to identify patterns in your data.
- Cloud integration: Informatica Developer 9.1.0 can now integrate with cloud-based services, such as Amazon S3 and Microsoft Azure. This allows you to store and process data in the cloud, and it also allows you to connect to cloud-based applications.
If you are looking for a powerful and feature-rich tool for data integration, then Informatica Developer 9.1.0 is a good choice. It has a number of new features that can help you to improve the quality of your data and to integrate your data with cloud-based services.
- What are the advantages of using Informatica as an ETL tool over Teradata?
Informatica and Teradata are two different types of tools within the data management ecosystem. Informatica is primarily known as an ETL (Extract, Transform, Load) tool, while Teradata is a data warehousing and analytics platform. It’s important to understand their roles and how they complement each other rather than directly comparing them. However, here are some advantages of using Informatica as an ETL tool:
Advantages of Informatica as an ETL Tool:
- Versatility: Informatica is a versatile ETL tool that supports a wide range of data sources and targets, making it suitable for complex data integration scenarios.
- Transformation Capabilities: Informatica provides powerful visual transformation capabilities, allowing users to design and implement complex data transformations with ease.
- Data Quality: Informatica offers data profiling and cleansing features, ensuring that data quality is maintained during the ETL process.
- Metadata Management: Informatica provides robust metadata management, facilitating better data lineage, impact analysis, and governance.
- Reusability: Informatica supports the creation of reusable components, such as mappings and transformations, which promotes consistency and reduces development time.
- Change Data Capture: Informatica can efficiently handle change data capture processes, allowing incremental updates to be processed.
- Scalability: Informatica is designed to handle large data volumes, making it suitable for enterprises with complex data integration needs.
- Broad Integration: Informatica integrates well with various data warehousing platforms, including Teradata, allowing for seamless data movement between systems.
On the other hand, Teradata offers advantages in terms of data warehousing and analytics capabilities:
Advantages of Teradata:
- Scalability: Teradata is known for its scalability, capable of handling massive data volumes and supporting analytical workloads.
- Parallel Processing: Teradata’s architecture enables parallel processing, resulting in fast query performance for complex analytical queries.
- Advanced Analytics: Teradata provides advanced analytics capabilities, including machine learning and predictive analytics, for deriving insights from data.
- Data Storage: Teradata’s data warehousing capabilities provide optimized storage and retrieval of historical data for analysis.
- Performance Optimization: Teradata’s query optimizer and indexing mechanisms contribute to efficient query performance.
In essence, Informatica and Teradata serve different purposes within the data management landscape. Informatica is valuable for ETL processes and data integration, while Teradata excels in data warehousing and advanced analytics. They often work together in data pipelines, with Informatica handling data movement and transformation, and Teradata managing the storage and analysis of data.
Informatica Intermediate Interview Questions
- Define Target Designer.
Target Designer is a component within Informatica PowerCenter used to design and define the structure of target databases or tables where data will be loaded during ETL processes. It enables you to specify columns, data types, relationships, and transformations for accurate data loading. Target Designer integrates with other Informatica components, aids in metadata management, and supports efficient ETL development.
- How can we access repository reports without SQL or other transformations?
In Informatica PowerCenter, you can access repository reports without using SQL or other transformations by leveraging the built-in functionality provided by the PowerCenter Client tools. Here’s how you can access repository reports directly:
- Using the Repository Manager:
– Open the Informatica Repository Manager tool.
– Connect to the repository where your PowerCenter metadata is stored.
– In the left panel, expand the “Reports” node.
– Browse through the available reports under categories such as “Database Reports,” “Transformation Reports,” etc.
– Click on the desired report to view its details and results.
- Using the PowerCenter Workflow Monitor:
– Open the PowerCenter Workflow Monitor tool.
– Connect to the repository where your workflows and sessions are managed.
– In the left panel, navigate to the “Reports” tab.
– You’ll find various predefined reports that provide insights into workflow and session runs, status, performance, etc.
– Click on a report to view its details and results.
- Using the PowerCenter Designer:
– Open the PowerCenter Designer tool.
– Connect to the repository where your mappings, transformations, and workflows are designed.
– In the menu, go to “Tools” > “Repository Reports.”
– This will provide a list of repository reports categorized based on their content.
– Click on a report to access its details.
- Using the Informatica Administrator Console:
– Open the Informatica Administrator Console.
– Navigate to the “Reports” section.
– You’ll find various reports related to the health, performance, and utilization of the Informatica environment.
– Click on a report to view its details.
- Mention the types of metadata that are stored in the repository.
In an Informatica PowerCenter repository, various types of metadata are stored to manage, document, and facilitate the ETL (Extract, Transform, Load) process. Some of the key types of metadata stored in the repository include:
- Source Metadata: Information about source systems, source tables, columns, data types, keys, and other attributes needed to extract data.
- Target Metadata: Details about target databases, tables, columns, indexes, constraints, and other information required for loading transformed data.
- Mapping Metadata: Definitions of mappings that specify how source data is transformed into target data. This includes transformations, expressions, joins, filters, and aggregations.
- Workflow Metadata: Information about workflows that orchestrate the execution of tasks, sequences, and dependencies within ETL processes.
- Session Metadata: Details about individual sessions within workflows, including source-to-target mappings, transformations applied, session properties, and session run statistics.
- Transformation Metadata: Specifications of various transformations used in mappings, including their properties, input/output ports, and expressions.
- Parameter and Variable Metadata: Definitions of parameters and variables used to make mappings and workflows more dynamic and flexible.
- Connection Metadata: Configuration details for connecting to various source and target systems, including database connections, file paths, and connectivity settings.
- Repository Objects Metadata: Information about repository-level objects such as folders, users, groups, roles, privileges, and security settings.
- Dependency Metadata: Relationships between various objects, such as mappings, workflows, and sessions, to ensure proper execution and impact analysis.
- Scheduler Metadata: Details about scheduling tasks, defining schedules, and managing execution frequency for workflows and sessions.
- Audit and Logging Metadata: Information related to logging levels, error handling, and audit settings to monitor and troubleshoot ETL processes.
- Versioning and History Metadata: Records of changes made to objects over time, enabling version control and historical tracking.
- Repository Reports Metadata: Details of predefined and custom reports that provide insights into various aspects of the repository and ETL processes.
These types of metadata collectively enable users to design, develop, schedule, execute, and monitor ETL processes using Informatica PowerCenter. They play a vital role in ensuring data accuracy, lineage, governance, and the efficient management of the ETL lifecycle.
- What is Code Page Compatibility?
Code Page Compatibility refers to the process of converting characters from one character encoding (code page) to another to enable accurate data transfer between systems with different character sets. This conversion ensures that characters are preserved during data integration and transformation, especially when moving data between languages, regions, or applications.
- Define Aggregator Transformation.
An Aggregator Transformation is a data transformation component in Informatica PowerCenter, an ETL (Extract, Transform, Load) tool. It is used to perform aggregate calculations on groups of data rows based on specified group-by columns. The Aggregator Transformation allows you to calculate summary information, such as totals, averages, counts, and minimum/maximum values, within groups of data.
Key points about the Aggregator Transformation:
- Grouping: The Aggregator Transformation groups data rows based on one or more columns specified as group-by columns. Each unique combination of values in the group-by columns forms a group.
- Aggregations: Within each group, you can define multiple aggregate expressions to calculate summary values. These expressions can include functions like SUM, AVG, COUNT, MIN, MAX, etc.
- Output Ports: The Aggregator Transformation generates output columns that contain the aggregated results. These columns represent the calculated values for each group.
- Sorted Input: For optimal performance, the input data should be sorted by the group-by columns before entering the Aggregator Transformation. This helps the transformation process groups more efficiently.
- Aggregate Cache: The Aggregator Transformation uses an aggregate cache to store intermediate results during processing. This improves performance by reducing the need to repeatedly access source data.
- Transformation Logic: The transformation logic includes selecting group-by columns, defining aggregate expressions, and specifying how to handle NULL values and duplicates.
- Transformation Order: The Aggregator Transformation is typically used after the Source Qualifier and any necessary transformations and before the Target.
- Memory Utilization: Aggregator Transformations may require significant memory resources, especially when dealing with large datasets. Adequate memory allocation is important for performance.
- Performance Considerations: Proper optimization of group-by columns, sorting, and cache size can significantly impact the performance of the Aggregator Transformation.
- Usage: Aggregator Transformations are used in scenarios where you need to calculate summary statistics on groups of data, such as generating reports, computing averages, and aggregating sales data.
In summary, the Aggregator Transformation is a powerful tool in Informatica PowerCenter that facilitates the calculation of summary information within groups of data. It’s commonly used for generating aggregated results required for reporting and analytics purposes.
- What is Expression Transformation?
Expression Transformation is a key component in Informatica PowerCenter, an ETL (Extract, Transform, Load) tool, used for performing data transformations by applying expressions and calculations to input data. It allows you to modify, manipulate, and transform data values based on defined logic, and then pass the transformed data to subsequent transformations or target systems.
Key points about the Expression Transformation:
- Data Manipulation: Expression Transformation enables you to perform various data manipulations, such as mathematical calculations, string manipulations, date calculations, conditional statements, and more.
- Single-Row Transformation: It operates on a row-by-row basis, processing each data row independently and applying the specified expressions.
- Custom Logic: You can define custom expressions using functions, operators, and conditions to derive new values, modify existing values, or create calculated fields.
- Input and Output Ports: Expression Transformation has both input and output ports. Input ports receive data from preceding transformations or source systems, and output ports pass the transformed data to subsequent transformations or target systems.
- Reusable Expressions: Expressions created in the Expression Transformation can be reused across different mappings, promoting consistency and efficiency.
- Null Handling: Expression Transformation provides options for handling NULL values, allowing you to manage data quality and transformations effectively.
- Usage: Expression Transformations are used for various tasks, such as data cleansing, data formatting, data validation, data enrichment, and creating derived fields.
- Performance Considerations: Expression Transformations can impact performance, especially when complex expressions are used or when processing large volumes of data.
- Transformation Order: Expression Transformations are typically used after Source Qualifier or any upstream transformations and before other transformations or the Target.
- Debugging: Expression Transformation includes debugging features that allow you to preview data at different stages of the transformation process and identify issues in your expressions.
Expression Transformations are fundamental for transforming and enriching data within an ETL pipeline. They provide a versatile and flexible way to modify and manipulate data based on specific business requirements, enabling data integration processes to generate accurate and meaningful outcomes.
- What are Sessions? List down their properties.
In Informatica PowerCenter, a session is a unit of work that describes the ETL (Extract, Transform, Load) process for moving data from source systems to target systems. A session encapsulates the entire data movement and transformation process and can include one or more workflows, mappings, and transformations. Sessions are designed to perform specific data integration tasks.
Properties of a session in Informatica PowerCenter include:
- Session Name: A unique name that identifies the session within the project.
- Workflow: The workflow associated with the session, which defines the execution flow, dependencies, and triggers.
- Mapping: The mapping used to transform the data from source to target. The mapping specifies how data is manipulated, filtered, and transformed.
- Source and Target Connections: The database or file connections used to connect to the source and target systems.
- Session Configuration: Settings related to the session execution, such as database connections, commit intervals, error handling, and target load types.
- Source Qualifier Transformation: If the source is a relational database, a Source Qualifier Transformation is used to extract data from the source database.
- Session Properties: Various session-specific properties, including parameters, variables, and session environment settings.
- Pre-Session Command: Optional command or script executed before the session starts. This can include setup tasks or data validation.
- Post-Session Command: Optional command or script executed after the session completes. This can include cleanup tasks or notifications.
- Mapping Parameters and Variables: Parameters and variables used within the mapping to make it dynamic and flexible.
- Session Log: Records information about the session’s execution, including source data statistics, transformation logic, errors, and status.
- Recovery Strategy: Specifies how the session should handle failures and how to restart from the point of failure.
- Performance Optimization: Configurations related to performance, such as partitioning, sorting, and indexing strategies.
- Commit and Rollback: Control settings for commit intervals and transaction boundaries during data loading.
- Session Schedule: Specifies when and how often the session should run, either on-demand or according to a defined schedule.
- Session Parameters: Parameters passed to the session that can affect its behavior, such as date ranges or filter conditions.
- Session Status: Indicates whether the session is enabled, disabled, or inactive.
- Email Notifications: Options to send email notifications after the session completes or when specific conditions are met.
- Session Variables: Variables used in expressions or scripts within the session, allowing for dynamic behavior.
- Performance Monitoring: Options for performance monitoring and logging to identify bottlenecks and optimize the session’s execution.
Sessions serve as the backbone of the data integration process, orchestrating the execution of mappings, transformations, and workflows to ensure accurate and efficient movement of data from source to target systems.
After a while, data in a table becomes old or redundant. In a scenario where new data enters the table, re cache ensures that the data is refreshed and updated in the existing and new cache.
I hope this Informatica Interview questions blog was of some help to you. We also have another Informatica Interview questions wherein scenario based questions have been compiled. It tests your hands-on knowledge of working on Informatica tool. You can go through that Scenario based Informatica Interview Questions blog by clicking on the hyperlink or by clicking on the button at the right hand corner.
If you have already decided to take up Informatica as a career, I would recommend you why don’t have a look at our Informatica Training course page. The Informatica Certification training at Edureka will make you an expert in Informatica through live instructor led sessions and hands-on training using real-life use cases.
Got a question for us? Please mention it in the comments section and we will get back to you.
































This is excellent information. It is amazing and wonderful to visit your site.Thanks for sharing this information,this is useful to me.
Nice blog, crisp and to the point.
Informatica is a Software development company, which offers data integration products. If offers products for ETL, data masking, data Quality, data replica, data virtualization, master data management, etc.
Informatica Powercenter ETL/Data Integration tool is a most widely used tool and in the common term when we say Informatica, it refers to the Informatica PowerCenter tool for ETL.
Informatica Powercenter is used for Data integration. It offers the capability to connect & fetch data from different heterogeneous source and processing of data.
how to register
Excellent information, really well thought
Hey Larry, thank you for taking look at our blog. We are so glad that you liked it. Stay tuned for more such updates on our channel! Cheers :)
Many Informatica students who will be giving their first job interview in this field will benefit a lot from this article! Thank you for sharing this great list of interview questions and answers.
Thank you for appreciating our blogs. Do subscribe to our channel and stay connected with us. Cheers :)
Amazing thanks for sharing
Simply superb article thank you
In a mapping maximum how many number of mapplets are using ?
Hey Chand Bujji, thanks for checking out the blog. There is no restriction on the number of mapplets. We can use as many see we can. Please feel free to contact us in case you have any other query. Cheers!
Thanks for sharing this nice useful informative post to our knowledge
Thanks so much for your wonderful feedback. We are happy we could help. Do keep checking back in for more blogs on all your favorite topics.