






Today’s world is experiencing a dramatic shift in how businesses operate. Everything’s going digital, and the rise of cloud computing and cloud platforms has been a massive catalyst for this growth. Most organizations are now either using or planning to adopt cloud computing for many of their operations, leading to an enormous surge in the demand for skilled cloud professionals.
If you’re interested in a career in the cloud industry, your opportunity has arrived. Cloud computing platforms like AWS are currently taking the business world by storm, and getting trained and certified in this platform can open up fantastic career prospects for you.
To kickstart your AWS career, you’ll need to prepare for and ace those critical AWS interviews. This blog is designed to help you do just that. We cover a wide range of AWS-related questions, from basic concepts to advanced scenarios, ensuring you’re ready for whatever comes your way.
Why AWS?
Before exploring the questions and answers, it is important to understand why it is worth considering the AWS Cloud as the go-to platform.
Here’s a breakdown of the worldwide market share among leading cloud infrastructure service providers for the first quarter (Q1) of 2024:
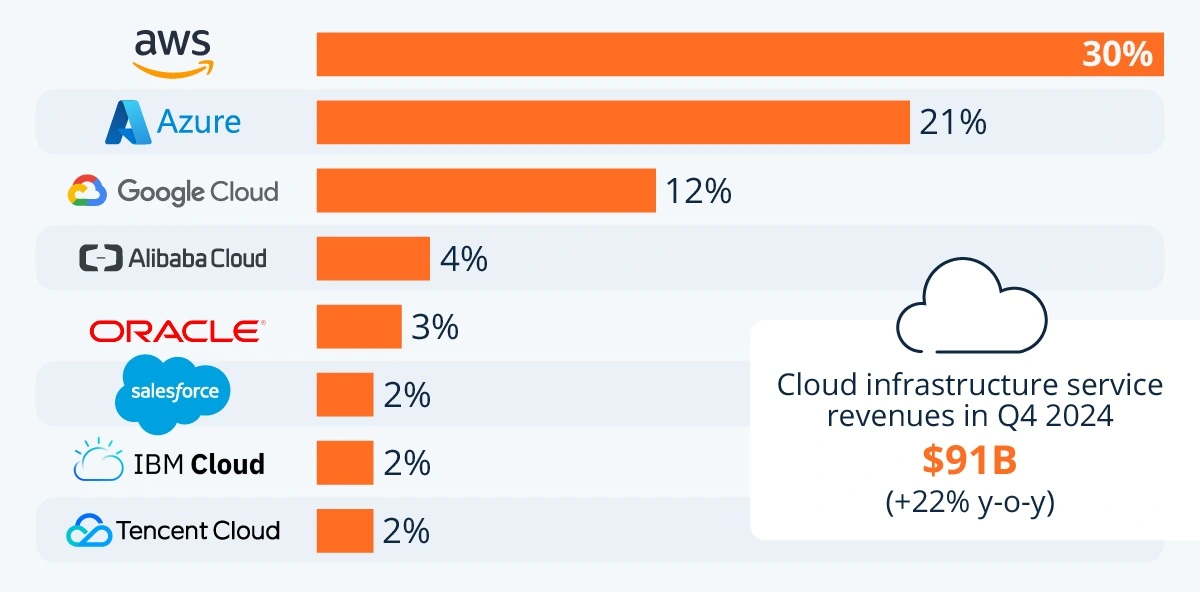
- Amazon Web Services (AWS) leads the market with a 31% share.
- Microsoft Azure follows, securing 25% of the market.
- Google Cloud holds 11% of the market share.
- Alibaba Cloud accounts for 4%.
- Salesforce has grown to reach 3%.
- IBM Cloud, Oracle, and Tencent Cloud each hold 2% of the market.
Also note that the data includes platform as a service (PaaS) and infrastructure as a service (IaaS), as well as hosted private cloud services. Additionally, there’s a mention that cloud infrastructure service revenues in Q1 2024 amounted to $76 billion, which is a significant jump from Q2 2023, when they were $65 billion.
Amazon Web Services (AWS) continues to be the dominant player in the cloud market as of Q1 2024, holding a significant lead over its closest competitor, Microsoft Azure.
AWS’s leadership in the cloud market highlights its importance for upskilling. It offers significant career advantages due to its wide adoption and the value placed on AWS skills in the tech industry.
Basic AWS Interview Questions for Beginners
1. What is AWS, and what are its primary services?
AWS (Amazon Web Services) is a comprehensive cloud computing platform offering a wide range of services such as compute (EC2), storage (S3), databases (RDS, DynamoDB), networking (VPC), application development, analytics, AI, security, and more, all delivered from data centers across global regions and availability zones.
2. What are the key components of Amazon S3?
The main components of Amazon S3 are Buckets (containers for storing data), Objects (the actual data/files), Keys (unique identifiers for objects within a bucket), Access Points (for managing access), and Access Control (permissions using bucket policies and ACLs).
3. What are the types of cloud computing models?
The main cloud computing models are Infrastructure as a Service (IaaS), Platform as a Service (PaaS), Software as a Service (SaaS), and Serverless computing. There are also deployment models: public cloud, private cloud, and hybrid cloud.
4. What is Amazon EC2?
Amazon EC2 (Elastic Compute Cloud) provides scalable, on-demand virtual servers (instances) in the AWS Cloud, allowing users to run applications, scale resources up or down, and pay only for what they use.
5. What is the difference between stopping and terminating an EC2 instance?
Stopping an EC2 instance shuts it down but keeps its data (for EBS-backed instances) and allows it to be started again. Terminating an instance deletes the instance and its attached storage (unless otherwise specified), making it unrecoverable.
6. What are availability zones and regions in AWS?
A region is a geographic area containing multiple, isolated locations called Availability Zones (AZs). Each AZ consists of one or more data centers, and resources in different AZs are isolated to increase fault tolerance and availability.
7. What is an Elastic Load Balancer?
Elastic Load Balancer (ELB) automatically distributes incoming application traffic across multiple targets (such as EC2 instances) in one or more AZs, helping ensure high availability, fault tolerance, and automatic scaling of applications.
8. What is AWS IAM and its importance?
AWS Identity and Access Management (IAM) enables secure management of access to AWS resources by allowing you to create users, groups, and roles with granular permissions, enforce multi-factor authentication, and integrate with identity providers for secure, auditable access control.
9. What is the difference between horizontal and vertical scaling?
Vertical scaling means adding more resources (CPU, RAM) to a single server, while horizontal scaling means adding more servers or nodes to distribute the load, increasing redundancy and scalability.
10. What are security groups, and how do they differ from network ACLs?
Security groups act as virtual firewalls at the instance level, controlling inbound and outbound traffic with allow rules only. Network ACLs operate at the subnet level, support both allow and deny rules, and provide an additional layer of security.
11. What is VPC?
A Virtual Private Cloud (VPC) is an isolated, configurable section of the AWS Cloud where you can launch AWS resources in a virtual network that you define, with control over IP addressing, subnets, route tables, and security.
12. What is the boot time for an instance store-backed instance?
Instance store-backed instances have longer boot times compared to EBS-backed instances because all parts must be retrieved from Amazon S3 before the instance is available.
13. What is DNS and how does it work in AWS?
DNS (Domain Name System) translates domain names to IP addresses. In AWS, Route 53 is a scalable DNS web service that routes end-user requests to AWS resources or external endpoints by resolving domain names to IP addresses.
14. What is SQS?
Amazon Simple Queue Service (SQS) is a fully managed message queuing service that enables decoupling and scaling of distributed systems by allowing reliable message exchange between producers and consumers.
15. What is AWS Lambda?
AWS Lambda is a serverless compute service that runs your code in response to events, automatically manages compute resources, and scales as needed, so you don’t have to provision or manage servers.
16. What is Auto Scaling in AWS?
AWS Auto Scaling automatically adjusts the capacity of AWS resources (like EC2, ECS, DynamoDB, etc.) to maintain performance and optimize costs based on defined policies and real-time demand.
17. What is AWS Lightsail?
AWS Lightsail is a simplified cloud platform that provides virtual private servers (VPS), storage, and networking, designed for users new to the cloud or those needing easy-to-use, cost-effective solutions for simple workloads.
18. What are the different types of storage available in AWS?
AWS provides Object Storage (S3, Glacier), File Storage (EFS), Block Storage (EBS), and Instance Store (ephemeral storage attached to EC2 instances).
19. What are the different types of cloud services?
The main types are Infrastructure as a Service (IaaS), Platform as a Service (PaaS), Software as a Service (SaaS), and Serverless computing.
20. What is Identity Access Management, and how is it used?
Identity and Access Management (IAM) is a framework for managing digital identities and controlling user access to resources using authentication, authorization, roles, and policies to secure and govern access.
21. What is Hybrid cloud architecture?
Hybrid cloud architecture combines public cloud, private cloud, and on-premises resources, allowing organizations to move workloads between environments for greater flexibility, scalability, and compliance.
22. What are AWS Organizations and SCPs?
AWS Organizations allows you to centrally manage and govern multiple AWS accounts. Service Control Policies (SCPs) are used within AWS Organizations to set permission guardrails, controlling the maximum available permissions for member accounts.
Intermediate AWS Interview Questions
23. How does Amazon Route 53 ensure high availability and low latency?
Amazon Route 53 uses a global anycast network of DNS servers distributed worldwide, automatically routing user queries to the nearest DNS server based on network conditions. This design ensures high availability and low latency for end users by circumventing internet or network issues and always using the optimal location for DNS resolution.
24. What is AWS CloudFormation and its benefits?
AWS CloudFormation is a service that enables you to define and provision AWS infrastructure using code templates. Benefits include reduced time spent on resource management, increased efficiency and consistency, infrastructure as code for versioning and change management, improved collaboration and documentation, easier updates, built-in auditing and change tracking, and reduced risk of configuration errors.
25. What is the difference between Amazon SQS and Amazon SNS?
Amazon SQS is a poll-based, one-to-one message queuing service where consumers pull messages from the queue, supporting message retention and batching. Amazon SNS is a push-based, one-to-many pub/sub service that immediately pushes messages to all subscribers, does not retain messages, and does not support batching.
26. What is Amazon RDS?
Amazon RDS (Relational Database Service) is a managed service for setting up, operating, and scaling relational databases in the AWS cloud. It automates database administration tasks such as backups, patching, and recovery, and supports multiple database engines including MySQL, PostgreSQL, Oracle, SQL Server, and Amazon Aurora.
27. What are the core components of the AWS Well-Architected Framework?
The AWS Well-Architected Framework is built around six pillars: operational excellence, security, reliability, performance efficiency, cost optimization, and sustainability. These pillars guide best practices for designing and running workloads in the cloud.
28. Explain the concept of Elastic IP in AWS?
An Elastic IP is a static, public IPv4 address that you can allocate to your AWS account and associate with an instance or network interface in a VPC. You can move Elastic IPs between instances as needed, making it useful for failover and high-availability scenarios.
29. What is AWS Elastic Beanstalk?
AWS Elastic Beanstalk is a platform-as-a-service (PaaS) that lets you quickly deploy and manage applications in the AWS Cloud. You upload your application, and Elastic Beanstalk automatically handles provisioning, load balancing, scaling, and monitoring, reducing management complexity.
30. What are the features of Amazon DynamoDB?
Amazon DynamoDB is a fully managed, serverless NoSQL database offering single-digit millisecond performance, multi-active replication with global tables, ACID transactions, change data capture with DynamoDB Streams, and flexible querying using secondary indexes.
31. What is Amazon VPC?
Amazon Virtual Private Cloud (VPC) is a service that lets you create a logically isolated section of the AWS Cloud where you can launch resources in a virtual network you define, with control over IP addressing, subnets, route tables, and security.
32. What is AWS Transit Gateway?
AWS Transit Gateway is a service that acts as a central hub to connect multiple VPCs and on-premises networks, simplifying network architecture and enabling efficient, scalable, and secure traffic routing between environments.
33. What is the role of AWS GuardDuty?
AWS GuardDuty is a threat detection service that continuously monitors AWS accounts, workloads, and data for malicious activity and unauthorized behavior using machine learning, anomaly detection, and threat intelligence.
34. How do you optimize costs for a high-traffic AWS application?
Optimize costs by right-sizing instances, using a mix of On-Demand, Reserved, and Spot Instances, enabling Auto Scaling, leveraging Elastic Load Balancers and CloudFront for content delivery, scheduling instances to shut down when not needed, and monitoring usage with Cost Explorer and CloudWatch.
35. What is AWS Direct Connect?
AWS Direct Connect is a service that provides a dedicated network connection from your premises to AWS, enabling private, high-bandwidth, low-latency connectivity that bypasses the public internet for more consistent network performance.
36. How do you monitor and troubleshoot performance issues using Amazon CloudWatch?
Use Amazon CloudWatch to collect and visualize metrics, set alarms, and correlate logs and events for AWS resources. This helps identify bottlenecks, track performance trends, and troubleshoot issues in real time by providing a unified view of system health.
37. What is the difference between Amazon Aurora and Amazon RDS?
Amazon RDS is a managed service for multiple relational database engines, suitable for general workloads. Amazon Aurora is a high-performance, cloud-native database compatible with MySQL and PostgreSQL, offering up to five times the throughput of standard MySQL and advanced features like auto-scaling storage and faster failover.
38. What is Amazon Kinesis?
Amazon Kinesis is a family of services for processing and analyzing real-time streaming data at scale, supporting use cases like analytics, log and event collection, and IoT data processing. Components include Kinesis Data Streams, Data Firehose, Data Analytics, and Video Streams.
39. What is the difference between Amazon S3 storage classes?
Amazon S3 offers multiple storage classes for different use cases: S3 Standard (frequent access), S3 Standard-IA and One Zone-IA (infrequent access), S3 Intelligent-Tiering (automated cost optimization), S3 Glacier and Glacier Deep Archive (archival), each differing in durability, availability, cost, and minimum storage duration.
40. What is the role of Amazon CloudFront in improving performance?
Amazon CloudFront is a content delivery network (CDN) that caches and delivers content from edge locations worldwide, reducing latency, improving reliability, and providing faster, more consistent user experiences.
41. What are the strategies to ensure disaster recovery in AWS?
Common strategies include backup and restore, pilot light (minimal core infrastructure always running), warm standby (scaled-down version always running), and multi-site active-active deployments. Multi-AZ and multi-region deployments further enhance resilience and reduce RTO/RPO.
42. What is AWS Glue?
AWS Glue is a serverless data integration service that helps you discover, prepare, move, and integrate data from multiple sources for analytics, machine learning, and application development, supporting ETL (extract, transform, load) pipelines and data cataloging.
43. What is AWS Data Pipeline?
AWS Data Pipeline is a web service that helps you process and move data between different AWS compute and storage services, as well as on-premises data sources, enabling scheduled, reliable data-driven workflows.
44. What are AWS Step Functions?
AWS Step Functions is a serverless orchestration service that lets you coordinate multiple AWS services into serverless workflows, using visual workflows to design and run distributed applications and automate business processes.
45. What is the difference between ECS and EKS?
Amazon ECS (Elastic Container Service) is a fully managed container orchestration service for Docker containers, tightly integrated with AWS. Amazon EKS (Elastic Kubernetes Service) is a managed service for running Kubernetes clusters on AWS, providing native Kubernetes compatibility and ecosystem support.
46. What is SES?
Amazon SES (Simple Email Service) is a cloud-based email sending service designed for sending marketing, notification, and transactional emails securely and at scale.
47. What is PaaS?
Platform as a Service (PaaS) is a cloud computing model that provides a platform allowing customers to develop, run, and manage applications without dealing with infrastructure management. AWS Elastic Beanstalk is an example of a PaaS offering.
48. Will you use encryption for S3?
Yes, encryption should be used for S3 to protect data at rest. AWS supports server-side encryption (SSE-S3, SSE-KMS, SSE-C) and client-side encryption.
49. What are policies, and what are the different types of policies?
Policies are JSON documents that define permissions for AWS resources. Types include identity-based policies (attached to users, groups, or roles), resource-based policies (attached to resources like S3 buckets), permissions boundaries, and service control policies (SCPs) for AWS Organizations.
50. What is sharding?
Sharding is a database partitioning technique that splits data across multiple servers or databases, improving scalability and performance by distributing the load.
51. Which data centers are deployed for cloud computing?
Cloud computing providers like AWS deploy data centers in multiple geographic regions and availability zones worldwide, ensuring redundancy, fault tolerance, and low latency.
52. Which AWS services will you use to collect and process e-commerce data for near real-time analysis?
Services commonly used include Amazon Kinesis (for real-time data streaming), AWS Glue (for ETL), Amazon S3 (for storage), Amazon Redshift or Athena (for analytics), and AWS Lambda (for serverless processing).
Advanced AWS Interview Questions
53. How would you design a multi-region, highly available web application in AWS?
Designing a multi-region, highly available web application involves deploying application resources across multiple AWS Regions and Availability Zones. Use Route 53 with latency-based routing to direct users to the nearest healthy region. Deploy application servers in each region, use CloudFront for global content delivery with origin failover, and replicate data using services like Amazon S3 Cross-Region Replication and DynamoDB Global Tables. For databases, use RDS with cross-region read replicas or Aurora Global Databases. Store secrets in AWS Secrets Manager with cross-region replication. Use Transit Gateway for scalable inter-region VPC connectivity, and centralize logging and monitoring. Ensure that each region can operate independently in case of a regional failure, and automate failover and recovery processes.
54. What are the trade-offs between using VPC Peering and AWS Transit Gateway?
VPC Peering is best for connecting a small number of VPCs (up to 125 connections per VPC), offering low cost and no bandwidth aggregation limits, but it lacks transit routing and becomes complex at scale. Transit Gateway is ideal for connecting hundreds or thousands of VPCs using a hub-and-spoke model, simplifying management and scaling, but it incurs additional hourly charges and has bandwidth limits. Transit Gateway is better for large, complex networks, while VPC Peering is simpler and more cost-effective for smaller setups.
55. Describe your approach to optimizing cost in AWS. How do you ensure that resources are used efficiently while maintaining system performance and reliability?
Cost optimization involves right-sizing resources, using Auto Scaling for elasticity, leveraging the appropriate pricing models (On-Demand, Reserved, and Spot Instances), and selecting the right storage classes. Regularly monitor and analyze usage with tools like AWS Cost Explorer and CloudWatch, implement cost allocation tags, and review metrics to identify and eliminate underutilized resources. Encourage a culture of continuous review and improvement to maintain both performance and cost efficiency.
56. How do you handle secrets and sensitive configuration data in your AWS applications? What AWS services or tools do you use for secure secret management?
Use AWS Secrets Manager to securely store, rotate, and manage sensitive information such as API keys, passwords, and database credentials. Secrets Manager encrypts secrets at rest using AWS KMS keys and ensures secure retrieval over TLS. Access is controlled via IAM policies, and secrets can be rotated automatically to enhance security.
57. Describe a situation where you needed to implement a zero-downtime deployment or update of an application on AWS. What techniques and AWS services did you use to achieve this?
Zero-downtime deployments can be achieved using rolling updates, where only a subset of instances is updated at a time while others continue serving traffic. Use load balancers to distribute traffic and health checks to ensure new instances are healthy before shifting traffic. AWS CodeDeploy automates this process, and blue/green deployments can further minimize risk by switching traffic between two identical environments after successful deployment. Monitoring and rollback strategies are essential for safety.
58. Tell us about an incident when you had to develop a fault-tolerant, highly available system. What difficulties did you encounter and how did you resolve them?
A fault-tolerant, highly available system requires redundancy across multiple AZs or regions, automated failover, and data replication. Challenges may include managing data consistency, handling failover logic, and increased operational complexity. Solutions involve using services like Multi-AZ RDS, cross-region replication, health checks, and automated recovery scripts to ensure continuous operation and minimal downtime.
59. Which risks and security problems are frequently seen in AWS settings, in your experience? How are the risks reduced?
Common risks include misconfigured IAM permissions, unsecured S3 buckets, exposed credentials, lack of encryption, and insufficient monitoring. Risks are mitigated by following the principle of least privilege, enabling encryption at rest and in transit, using AWS Config and CloudTrail for auditing, regular security reviews, and automated compliance checks.
60. How can you be confident that your systems can withstand traffic spikes and are scalable?
Implement Auto Scaling groups for EC2 and managed services like RDS and DynamoDB that scale based on demand. Use load balancers to distribute traffic and CloudWatch to monitor performance metrics. Regularly perform load testing to validate scaling policies and ensure the architecture can handle sudden increases in traffic.
61. In its AWS environment, your organization is having performance problems. Which actions would you take to address the problem and improve performance?
Start by monitoring resources with CloudWatch to identify bottlenecks (CPU, memory, disk, network). Use application performance monitoring tools, review logs, and benchmark workloads. Optimize resource allocation, right-size instances, improve database queries, and consider using caching or distributing workloads across more resources.
62. Can you give an example of a real-world situation where you hosted a high-performance, scalable web application using EC2?
A typical setup involves deploying multiple EC2 instances behind an Elastic Load Balancer, using Auto Scaling to handle varying traffic, and storing session data in a distributed cache like ElastiCache. The application’s database runs on RDS with Multi-AZ for high availability. This architecture allows the application to scale up during peak loads and scale down to save costs, ensuring high performance and reliability.
63. Can you provide an example of a real-world situation where you managed a mission-critical database using RDS?
For a mission-critical application, RDS was configured in Multi-AZ mode, providing synchronous replication to a standby instance in another AZ. Automated backups and snapshots ensured data durability, and read replicas were used to offload reporting queries. This setup minimized downtime during maintenance and failovers, ensuring continuous service.
64. Can you give an example of a time when you used VPC to protect an AWS multitier architecture?
A secure multitier architecture was designed by placing web servers in public subnets and application/database servers in private subnets within a VPC. Security groups and network ACLs restricted access, and NAT gateways allowed outbound internet access for private resources. This setup ensured only necessary traffic reached sensitive components.
65. Can a connection be made between a company’s data center and the Amazon cloud? How?
Yes, a company’s data center can connect to AWS using either a site-to-site VPN (over the internet) or AWS Direct Connect (dedicated private connection), both of which link the on-premises network to a VPC in AWS.
66. How does AWS handle high availability?
AWS achieves high availability through redundancy across multiple Availability Zones and regions, automated failover, load balancing, and managed services like RDS Multi-AZ and Elastic Load Balancing. Best practices include deploying resources across AZs, using health checks, and automating recovery processes.
67. How do you optimize AWS costs?
Optimize costs by right-sizing resources, using Auto Scaling, selecting the right pricing model (On-Demand, Reserved, Spot), monitoring usage, eliminating unused resources, and leveraging cost management tools like AWS Cost Explorer and Budgets.
68. How do you ensure high availability in AWS?
Ensure high availability by deploying resources across multiple AZs, using load balancers, configuring Multi-AZ databases, automating failover, and continuously monitoring system health. Regularly test failover and disaster recovery processes to validate readiness.
Scenario-Based AWS Interview Questions
69. A company plans to migrate its legacy application to AWS. The application is data-intensive and requires low-latency access for users across the globe. What AWS services and architecture would you recommend to ensure high availability and low latency?
Recommend migrating with AWS Application Migration Service to move workloads efficiently. For global low-latency access and high availability, use Amazon CloudFront as a content delivery network, deploy application servers in multiple AWS regions, and use Amazon S3 with Cross-Region Replication for static data. For databases, consider Amazon Aurora Global Databases or DynamoDB Global Tables for multi-region replication. Route 53 can help with global DNS routing to the nearest healthy region.
70. Your organization wants to implement a disaster recovery plan for its critical AWS workloads with an RPO (Recovery Point Objective) of 5 minutes and an RTO (Recovery Time Objective) of 1 hour. Describe the AWS services you would use to meet these objectives.
To achieve an RPO of 5 minutes and RTO of 1 hour, use AWS Elastic Disaster Recovery or AWS Application Migration Service for rapid failover and minimal data loss. Enable frequent backups and cross-region replication for databases (e.g., RDS, DynamoDB). Use S3 Cross-Region Replication for object storage and automate failover with Route 53. Regularly test recovery procedures to ensure objectives are met.
71. Consider a scenario where you need to design a scalable and secure web application infrastructure on AWS. The application should handle sudden spikes in traffic and protect against DDoS attacks. What AWS services and features would you use in your design?
Use Auto Scaling groups with EC2 instances to handle traffic spikes and Elastic Load Balancer for distribution. Protect against DDoS using AWS Shield and AWS WAF for web application firewall rules. Deploy CloudFront as a CDN for both performance and edge-based DDoS mitigation. Use VPC for network isolation, and monitor with CloudWatch and GuardDuty.
72. An IoT startup wants to process and analyze real-time data from thousands of sensors across the globe. The solution needs to be highly scalable and cost-effective. Which AWS services would you use to build this platform, and how would you ensure it scales with demand?
Leverage AWS IoT Core for device connectivity and management, AWS IoT Analytics for scalable data transformation and analysis, and Amazon S3 for storage. Use AWS Lambda for serverless data processing and Amazon Kinesis for real-time streaming analytics. To optimize costs and scalability, use IoT Greengrass for edge processing and only send relevant data to the cloud.
73. A financial services company requires a data analytics solution on AWS to process and analyze large volumes of transaction data in real time. The solution must also comply with stringent security and compliance standards. How would you architect this solution using AWS, and what measures would you put in place to ensure security and compliance?
Design the solution with Amazon Kinesis or AWS Glue for real-time data ingestion and ETL, Amazon S3 for secure storage, and Amazon Redshift or Athena for analytics. Use IAM for fine-grained access control, enable encryption at rest and in transit, and implement audit logging with CloudTrail. Leverage AWS’s compliance certifications and Well-Architected Framework to meet regulatory requirements.
74. You accidentally stopped an EC2 instance in a VPC with an associated Elastic IP. If you start the instance again, what will be the result?
The Elastic IP remains associated with the instance, so when you start the instance again, it retains the same Elastic IP address.
75. Your organization wants to send and receive compliance emails to its clients using its email address and domain. What service would you suggest to achieve the same easily and cost-effectively?
Use Amazon Simple Email Service (SES), which is designed for sending and receiving emails securely and at scale, making it ideal for compliance-related communications.
Technical and Non-Technical AWS Interview Questions
76. What motivates you to work in the cloud computing industry, specifically with AWS?
The rapid innovation, scalability, and impact of AWS in transforming businesses motivate me. I enjoy working with cutting-edge technologies, solving complex problems, and contributing to projects that help organizations grow and innovate.
77. Can you describe a challenging project you managed and how you ensured its success?
In a previous project facing tight deadlines and resource constraints, I prioritized tasks based on impact, negotiated for additional resources, and maintained clear communication with the team and stakeholders. This approach helped us meet milestones and deliver the project on time.
78. How do you handle tight deadlines when multiple projects are demanding your attention?
I prioritize tasks by urgency and importance, delegate when possible, and use project management tools to track progress. Regular communication with stakeholders helps manage expectations and allows for timely adjustments to meet deadlines.
79. What do you think sets AWS apart from other cloud service providers?
AWS stands out due to its extensive service portfolio (over 200 services), global infrastructure, scalability, strong ecosystem and integrations, and robust security and compliance features.
80. How do you approach learning new AWS tools or services when they’re introduced?
I start by understanding the domain, reviewing AWS documentation and overview videos, experimenting hands-on in the AWS Console, and following practical tutorials. I also study the pricing model and use infrastructure as code to deepen my understanding.
81. Describe how you balance security and efficiency when designing AWS solutions.
I follow AWS best practices by implementing least-privilege access, using IAM roles, enabling encryption, and automating security checks. At the same time, I leverage managed and serverless services to reduce operational overhead and ensure performance and cost efficiency.
AWS Interview Questions and Answers S3
82. How many S3 buckets can be created?
By default, you can create up to 10,000 S3 buckets per AWS account. If needed, you can request a quota increase to create up to 1 million buckets per account.
83. What are the key components of Amazon S3?
The main components are Buckets (containers for storing objects), Objects (the actual data/files), Keys (unique identifiers for objects within a bucket), Access Points (for managing access), and Access Control (permissions via bucket policies and ACLs).
84. What are the different ways to encrypt a file in S3?
Files in S3 can be encrypted using server-side encryption with Amazon S3 managed keys (SSE-S3), server-side encryption with AWS KMS keys (SSE-KMS), dual-layer server-side encryption (DSSE-KMS), server-side encryption with customer-provided keys (SSE-C), and client-side encryption where you manage the keys and encryption process.
85. Is there a way to upload a file that is greater than 100 megabytes on Amazon S3?
Yes, AWS recommends using the multi-part upload method for files larger than 100 MB. This breaks the file into chunks and uploads them in parallel, improving speed and reliability. Files up to 5 GB can be uploaded with this method.
86. What is the difference between Amazon S3 storage classes?
Amazon S3 offers multiple storage classes for different use cases:
- S3 Standard: For frequently accessed data.
- S3 Intelligent-Tiering: Automatically moves data between tiers based on usage.
- S3 Standard-IA and One Zone-IA: For infrequently accessed data.
- S3 Express One Zone: For low-latency, single-AZ workloads.
- S3 Glacier Instant Retrieval, Flexible Retrieval, and Deep Archive: For archival and long-term backup, with varying retrieval times and costs.
Each class differs in durability, availability, cost, and minimum storage duration.
87. Will you use encryption for S3?
Yes, encryption should be used for S3 to protect data at rest and in transit. By default, all new S3 objects are automatically encrypted using server-side encryption (SSE-S3), and you can choose other encryption options for additional control.
AWS Interview Questions for VPC
88. What do you understand by VPC?
A Virtual Private Cloud (VPC) is a logically isolated, customizable virtual network within the AWS Cloud where you can launch AWS resources such as EC2 instances and databases. It closely resembles a traditional on-premises network, giving you control over IP address ranges, subnets, route tables, gateways, and security settings.
89. What’s the difference between public and private subnets in a VPC?
A public subnet is connected to the internet via an internet gateway, allowing resources within it (like EC2 instances) to send and receive traffic from the internet. A private subnet does not have a direct route to the internet and is typically used for resources that shouldn’t be publicly accessible, such as databases or backend servers.
90. Can you give an example of a time when you used VPC to protect an AWS multitier architecture?
In a typical multitier architecture, web servers are placed in a public subnet (accessible from the internet), while application servers and databases are placed in private subnets (not directly accessible from the internet). Security groups and network ACLs further restrict access, ensuring only necessary communication between tiers and protecting sensitive data and services.
91. You accidentally stopped an EC2 instance in a VPC with an associated Elastic IP. If you start the instance again, what will be the result?
When you start the instance again, the Elastic IP remains associated with the instance, so it retains the same public IP address.
AWS Interview Questions for Database
92. What is Amazon RDS?
Amazon RDS (Relational Database Service) is a fully managed cloud service that simplifies the setup, operation, and scaling of relational databases such as MySQL, PostgreSQL, MariaDB, Oracle, SQL Server, and Amazon Aurora. It automates tasks like backups, patching, and failover, and provides high availability through multi-AZ deployments.
93. What are the features of Amazon DynamoDB?
Amazon DynamoDB is a fully managed, serverless NoSQL database known for single-digit millisecond performance at any scale. Key features include multi-active replication with global tables, ACID transaction support, change data capture with DynamoDB Streams, flexible querying using global and local secondary indexes, and seamless scalability.
94. What is the difference between Amazon Aurora and Amazon RDS?
Amazon Aurora is a cloud-native relational database compatible with MySQL and PostgreSQL, offering higher performance, automatic scaling, and a distributed, multi-AZ storage architecture. Aurora can scale storage automatically up to 128TiB and provides faster failover and replication. Amazon RDS supports more database engines and offers traditional database management with up to 64TiB storage for some engines, but with less automation and scalability compared to Aurora.
95. AWS provides a range of database services, including RDS, Aurora, DynamoDB, and Redshift. How do you choose the right database service for a specific application’s requirements?
Choose based on data type and workload:
- Use RDS or Aurora for structured, relational data with complex queries and transactions.
- Use DynamoDB for high-scale, low-latency NoSQL workloads with key-value or document data.
- Use Redshift for large-scale data warehousing and analytics.
Other services like DocumentDB, Neptune, and Timestream are suited for document, graph, and time-series data, respectively. Consider performance, scalability, and compliance needs.
96. Can you provide an example of a real-world situation where you managed a mission-critical database using RDS?
In a mission-critical application, RDS was configured with Multi-AZ deployments for high availability and automated failover. Read replicas were used to scale read operations, and automated backups enabled point-in-time recovery. This setup ensured minimal downtime and data loss during incidents.
97. What is sharding?
Sharding is a database partitioning technique that splits a large database into smaller, more manageable pieces called shards. Each shard contains a subset of the data and is stored on a separate server, improving performance and scalability by distributing the workload across multiple machines.
AWS Interview Questions and Answers
General AWS DevOps Questions
98. What do you know about DevOps?
DevOps is a software development and operations approach that emphasizes collaboration, automation, continuous integration, continuous delivery (CI/CD), and monitoring to accelerate software delivery and improve reliability. It aims to break down silos between development and operations teams for faster, more stable releases.
99. How is DevOps different from agile methodology?
Agile focuses on iterative software development, collaboration, and customer feedback, primarily addressing the development phase. DevOps extends beyond development to include operations, emphasizing automation, continuous testing, deployment, and end-to-end responsibility for software delivery and maintenance.
100. Which are some of the most popular DevOps tools?
Popular DevOps tools include AWS CodePipeline, CodeBuild, CodeDeploy, CodeCommit, Jenkins, Git, Docker, Kubernetes, Terraform, Ansible, Chef, and Puppet.
101. What are the different phases in DevOps?
The main phases are: Plan, Code, Build, Test, Deploy, Operate, Monitor, and Feedback. These stages form a continuous, iterative cycle to ensure rapid and reliable software delivery.
102. What is the role of configuration management in DevOps?
Configuration management ensures consistency and integrity of software and infrastructure across environments by tracking and controlling changes. It minimizes errors, enables automation, and ensures reliable deployments using tools like Ansible, Chef, Puppet, and version control systems.
103. How does continuous monitoring help you maintain the entire architecture of the system?
Continuous monitoring collects and analyzes real-time metrics, logs, and events from applications and infrastructure. It helps detect issues early, supports automated responses, and provides visibility into system health, enabling proactive maintenance and faster incident resolution.
104. What is the role of AWS in DevOps?
AWS provides a suite of DevOps tools and services, such as CodePipeline, CodeBuild, CodeDeploy, CloudFormation, CloudWatch, and Lambda, that automate infrastructure provisioning, software deployment, monitoring, and scaling, enabling teams to implement DevOps best practices efficiently on the cloud.
105. Name three important DevOps KPIs.
Three key DevOps KPIs are: Deployment frequency, Change failure rate, and Mean time to recovery (MTTR).
106. Explain the term “Infrastructure as Code” (IaC) as it relates to configuration management.
IaC is the practice of managing and provisioning infrastructure using machine-readable code and templates, enabling version control, automation, and repeatable deployments, thus reducing manual errors and improving consistency.
107. How is IaC implemented using AWS?
AWS implements IaC through services like AWS CloudFormation and AWS CDK, where infrastructure is defined in templates (YAML/JSON or code), versioned, and deployed as stacks. These tools automate provisioning, updates, and drift detection for AWS resources.
108. Why has DevOps gained prominence over the last few years?
DevOps has become popular due to its ability to accelerate software delivery, improve collaboration, increase deployment reliability, enable rapid response to change, and support scalable, cloud-native architectures.
109. What is DevOps and how does AWS support it?
DevOps is a culture and set of practices that unify development and operations to automate and improve software delivery. AWS supports DevOps with integrated tools for CI/CD, infrastructure automation, monitoring, and scalable cloud services.
110. Can you explain the concept of “Infrastructure as Code” and how it’s implemented in AWS?
Infrastructure as Code means defining cloud resources using code or templates for automated, consistent, and repeatable deployments. In AWS, this is implemented with CloudFormation, CDK, and related tools that manage infrastructure lifecycle as code.
111. Explain the concept of “Everything as Code” in DevOps and how AWS supports it.
Everything as Code applies coding principles—such as version control, testing, and automation—to all aspects of IT (infrastructure, configuration, policies, documentation). AWS supports this with services like CloudFormation, CDK, and automation tools, enabling codification and automation across the stack.
112. What monitoring tools and practices do you prefer to use when ensuring system health and optimizing efficiency on AWS?
Preferred tools include Amazon CloudWatch for metrics and alarms, AWS CloudTrail for auditing, AWS X-Ray for tracing, and AWS Config for compliance. Practices include setting up dashboards, automated alerts, and regular log reviews.
113. What CI/CD tools have you worked on, and how have they contributed to the automation of infrastructure deployment and management?
Tools like AWS CodePipeline, CodeBuild, CodeDeploy, Jenkins, and GitHub Actions automate building, testing, and deploying code, leading to faster releases, reduced manual errors, and consistent infrastructure deployments.
114. What problems does a large organization face while deploying DevOps?
Challenges include silos between teams, inconsistent tools and processes, resistance to change, scaling infrastructure, and measuring success. Overcoming these requires standardization, automation, collaboration, and upskilling.
115. What are the most effective methods for dealing with change in a DevOps setting?
Effective methods include using version control, automated CI/CD pipelines, thorough documentation, change tracking, code reviews, and continuous integration and testing to ensure safe and traceable changes.
116. How could you make your CI/CD workflow more effective?
Improve by automating tests and deployments, enforcing code reviews, making frequent small merges, isolating environments, and securing production access. Monitor pipeline health and resolve issues promptly.
117. How would you track the modifications made to your applications and infrastructure using your CI/CD pipeline?
Track changes using version control systems (e.g., CodeCommit, Git), enable pull requests and code reviews, and use pipeline logs and notifications to monitor deployments and changes.
118. How do you handle version control in AWS, and what strategies would you use with CodeCommit?
Use AWS CodeCommit for secure, managed Git repositories. Employ branching strategies (feature, release, hotfix branches), enforce IAM-based access controls, require pull requests for code reviews, and set up notifications for repository activity.
119. What are the best practices for implementing high availability and disaster recovery in AWS?
Best practices include deploying resources across multiple AZs and regions, using automated backups, enabling cross-region replication, automating failover, and regularly testing recovery procedures.
120. How do you secure DevOps pipelines in AWS, especially when dealing with sensitive data?
Secure pipelines by integrating security checks early (shift left), automating vulnerability scans, using IAM for least-privilege access, encrypting secrets with AWS Secrets Manager, and monitoring with AWS-native security tools like GuardDuty and Config.
121. What strategies would you use to scale your application in AWS automatically?
Use AWS Auto Scaling for EC2, ECS, DynamoDB, and other services, set scaling policies based on metrics, and leverage managed load balancers to distribute traffic and optimize resource usage.
122. What is the importance of AWS OpsWorks, and how does it compare to AWS Systems Manager?
AWS OpsWorks is a configuration management service using Chef/Puppet for application deployment and orchestration, ideal for managing complex stacks. AWS Systems Manager focuses on system maintenance, patching, and automation without server infrastructure, making it better for operational tasks and hybrid environments.
CI/CD Pipeline Questions
123. How does AWS CodePipeline facilitate continuous integration and continuous delivery?
AWS CodePipeline automates the build, test, and deployment phases of your software release process. It enables continuous integration by automatically building and testing code every time there is a code change, and supports continuous delivery by automating the deployment of changes to production or other environments. CodePipeline integrates with AWS services like CodeBuild and CodeDeploy, as well as third-party tools, allowing you to define customizable pipelines, visualize workflow stages, and rapidly release new features with high reliability.
124. How would you track the modifications made to your applications and infrastructure using your CI/CD pipeline?
Tracking modifications is achieved by integrating version control systems (like Git or AWS CodeCommit) with your CI/CD pipeline, ensuring every change is logged and traceable. Pipeline visibility features, monitoring tools, and dashboards allow you to observe changes at each stage of the build, test, and deployment process. Real-time alerts and notifications keep teams informed about pipeline status and modifications.
125. How could you make your CI/CD workflow more effective?
To optimize your CI/CD workflow, automate build and deployment processes, integrate automated testing, and use monitoring tools for early failure detection. Establish clear KPIs, regularly review pipeline performance, and adopt best practices like infrastructure as code, security checks, and continuous feedback. Encourage collaboration, use pipeline visualization, and embrace a culture of continuous improvement and learning.
126. Describe a situation where you need to troubleshoot a failing CI/CD pipeline.
When troubleshooting a failing CI/CD pipeline, start by reviewing pipeline logs and monitoring dashboards to identify the failed stage or job. Check configuration variables, environment settings, and recent code changes. Use debugging tools or run failing commands locally to replicate the issue. Analyze error messages, consult documentation, and collaborate with team members to isolate and resolve the root cause.
Containerization and Orchestration
127. What is the difference between ECS and EKS?
Amazon ECS (Elastic Container Service) is AWS’s native, fully managed container orchestration service that is deeply integrated with AWS services, easy to use, and ideal for teams looking for simplicity and quick deployments. ECS abstracts much of the complexity, does not require managing a control plane, and is cost-effective, especially for AWS-centric workloads. It is suitable for straightforward container management and works with both EC2 and AWS Fargate for compute.
Amazon EKS (Elastic Kubernetes Service) is a fully managed Kubernetes service that brings the flexibility and power of the open-source Kubernetes platform to AWS. EKS is more complex, requires Kubernetes expertise, and offers granular control over deployments, networking, and scaling. It is ideal for organizations needing multi-cloud or hybrid deployments, advanced orchestration, or those already using Kubernetes. EKS provides greater flexibility and control but at the cost of increased complexity and management overhead.
128. Can you explain the difference between AWS Elastic Beanstalk and AWS Elastic Kubernetes Service (EKS)? When would you choose one over the other for a specific application or workload?
AWS Elastic Beanstalk is a managed service for deploying and scaling web applications and services. It automatically handles the provisioning of infrastructure (like EC2, load balancers, and auto scaling), application deployment, and health monitoring. Beanstalk is best for simple applications, teams with limited DevOps or container experience, and scenarios where ease of use and fast time-to-market are priorities. It supports containerized applications but does not offer Kubernetes support and provides limited customization over the underlying infrastructure.
AWS EKS, on the other hand, is a managed Kubernetes service that offers granular control over container orchestration, networking, and scaling. It is suitable for complex, large-scale, or microservices-based applications, especially when you need advanced orchestration, custom networking, or plan to run workloads across multiple clouds or on-premises. EKS is preferred when you require Kubernetes-native features, have a team with Kubernetes expertise, or need to manage both stateless and stateful workloads with fine-grained control.
AWS Elastic Beanstalk and Lambda, Lambda and Serverless
129. What is AWS Lambda?
AWS Lambda is an event-driven, serverless compute service that lets you run code without provisioning or managing servers. Lambda automatically scales and executes your code in response to events such as HTTP requests, file uploads, or changes in data, and you only pay for the compute time consumed.
130. How would you create a scalable and affordable application using serverless computing?
To build a scalable and cost-effective serverless application, use AWS Lambda for compute, API Gateway for managing HTTP requests, and managed services like DynamoDB or S3 for storage. Design your application as microservices, keep functions lightweight, and leverage auto-scaling and pay-as-you-go pricing. Use frameworks like AWS SAM or Serverless Framework for deployment, and monitor performance with CloudWatch. This approach allows your app to handle millions of concurrent requests automatically, with costs only incurred for actual usage.
131. You have been given the responsibility of setting up Elastic Beanstalk so that it can automatically deploy updated versions of your application each time you upload a modification to your code repository. What method would you use?
Set up a continuous deployment workflow using a CI/CD tool like GitHub Actions or AWS CodePipeline integrated with Elastic Beanstalk. Configure your workflow to trigger deployments to Elastic Beanstalk whenever changes are pushed to your repository, using IAM credentials with appropriate permissions and deployment scripts defined in your pipeline configuration.
132. What is AWS Elastic Beanstalk?
AWS Elastic Beanstalk is a managed service that enables you to quickly deploy and manage applications in the AWS Cloud without dealing with the underlying infrastructure. You simply upload your application code, and Elastic Beanstalk automatically handles provisioning, load balancing, scaling, and health monitoring for your environment.
133. Which service would you use to create a continuous delivery workflow for serverless applications?
AWS CodePipeline is the recommended service for orchestrating a continuous delivery workflow for serverless applications. It integrates with services like Lambda, API Gateway, and CloudFormation to automate build, test, and deployment stages for serverless workloads.
134. What are AWS Step Functions?
AWS Step Functions is a serverless orchestration service that lets you coordinate multiple AWS services into workflows using a visual editor. It manages the sequence, error handling, and retry logic of each step, making it easier to build complex, distributed applications with reliable execution and tracking.
AWS EC2 and Load Balancing
135. What is EC2?
Amazon EC2 (Elastic Compute Cloud) is a web service that provides resizable, on-demand compute capacity in the cloud, allowing users to run virtual servers (instances) for various workloads with flexible scaling and pricing options.
136. What are the key security best practices for AWS EC2?
Best practices include using IAM roles for permissions, enabling security groups and network ACLs, regularly patching OS and applications, disabling root access and using SSH keys, encrypting data at rest and in transit, and monitoring with CloudWatch and CloudTrail.
137. Can you give an example of a real-world situation where you hosted a high-performance, scalable web application using EC2?
A typical setup involves deploying EC2 instances behind an Elastic Load Balancer, using Auto Scaling to adjust capacity based on demand, and storing session data in ElastiCache or DynamoDB. RDS provides a scalable backend database, and CloudWatch monitors performance for proactive scaling and troubleshooting.
138. What is an Elastic Load Balancer?
Elastic Load Balancer (ELB) is a managed service that automatically distributes incoming application traffic across multiple targets, such as EC2 instances, containers, or IP addresses, in one or more Availability Zones to ensure high availability and fault tolerance.
139. How does auto-scaling work?
Auto Scaling automatically adjusts the number of compute resources (like EC2 instances) based on demand using scaling policies and CloudWatch alarms. It helps maintain performance, availability, and cost efficiency by adding or removing resources as needed.
AWS CloudFormation and Automation
140. What is AWS CloudFormation and its benefits?
AWS CloudFormation is a service that enables you to define and provision AWS infrastructure as code using templates. Benefits include automated, repeatable deployments, version control, consistency, and easier management of complex environments.
141. How can you use AWS CloudFormation to implement Infrastructure as Code?
You write CloudFormation templates (in YAML or JSON) describing your AWS resources and configurations. These templates are used to create, update, or delete stacks, enabling automated and version-controlled infrastructure provisioning.
142. How does CloudFormation help with infrastructure management?
CloudFormation manages the lifecycle of AWS resources, tracks dependencies, supports rollbacks on failures, and allows you to update or delete resources in a controlled, predictable manner, reducing manual errors and improving operational efficiency.
143. You are building a new infrastructure for your application using AWS CloudFormation. The CloudFormation template has an error that you have committed. What could happen as a result of the error, and how would you correct it?
If the template has an error, stack creation or update may fail, leading to incomplete or inconsistent infrastructure. CloudFormation will roll back changes by default. To correct it, review error messages, fix the template, validate with the CloudFormation linter, and redeploy.
AWS Monitoring and Logging
144. What is CloudWatch?
Amazon CloudWatch is a monitoring and observability service that collects and tracks metrics, logs, and events from AWS resources and applications, enabling real-time monitoring, alerting, and automated responses.
145. How do you monitor and troubleshoot performance issues using Amazon CloudWatch?
Monitor key metrics (CPU, memory, disk, network), set up alarms for anomalies, analyze logs, and use CloudWatch dashboards for visualization. Troubleshoot by correlating metrics with logs and events to identify and resolve bottlenecks or failures.
146. How would you design a logging and monitoring solution for a distributed microservices app on AWS?
Use CloudWatch Logs for centralized log collection, CloudWatch Metrics for resource monitoring, and X-Ray for distributed tracing. Set up dashboards, alarms, and automated notifications. Use structured logging and correlation IDs for easier tracing across services.
147. What observability tools have you utilized, specifically? How do you employ them for system monitoring?
Tools include Amazon CloudWatch (metrics, logs, alarms), AWS X-Ray (tracing), AWS CloudTrail (auditing), and third-party solutions like Datadog or New Relic. These are used for real-time monitoring, alerting, root cause analysis, and compliance auditing.
148. What is the role of Amazon CloudWatch in DevOps?
CloudWatch enables DevOps teams to monitor application and infrastructure health, set up automated alarms, trigger scaling actions, and analyze logs and metrics for faster troubleshooting and continuous improvement.
AWS Auto Scaling
149. What is Auto Scaling in AWS?
Auto Scaling is a service that automatically adjusts the number of compute resources (like EC2 instances, ECS tasks, or DynamoDB capacity) based on demand, maintaining application performance and optimizing costs.
150. How can you be confident that your systems can withstand traffic spikes and are scalable?
Implement Auto Scaling, use load balancers, regularly perform load testing, monitor with CloudWatch, and design stateless applications for horizontal scaling. Review scaling policies and test failover scenarios.
151. Describe a situation where you needed to scale an application dynamically based on traffic spikes. What AWS services and strategies did you use to handle sudden increases in load?
Used EC2 Auto Scaling groups with scaling policies based on CPU and network metrics, Elastic Load Balancer for traffic distribution, and CloudWatch alarms to trigger scaling. Caching with ElastiCache and asynchronous processing with SQS helped absorb spikes.
AWS Networking
152. What is DNS and how does it work in AWS?
DNS (Domain Name System) translates domain names to IP addresses. In AWS, Route 53 provides managed DNS services, routing user requests to AWS resources or external endpoints with high availability and low latency.
153. What’s the difference between public and private subnets in a VPC?
Public subnets have a route to the internet via an internet gateway, allowing direct access, while private subnets do not, restricting access to internal resources only.
154. What are security groups, and how do they differ from network ACLs?
Security groups act as virtual firewalls at the instance level, allowing only specified inbound/outbound traffic. Network ACLs operate at the subnet level, support both allow and deny rules, and provide stateless filtering.
155. What is AWS Transit Gateway?
AWS Transit Gateway is a network transit hub that connects multiple VPCs and on-premises networks through a central gateway, simplifying network architecture and management at scale.
156. Can a connection be made between a company’s data center and the Amazon cloud? How?
Yes, using AWS Direct Connect for a dedicated private connection or a VPN connection over the internet to link the on-premises data center to an AWS VPC.
157. What is Hybrid cloud architecture?
Hybrid cloud architecture integrates on-premises infrastructure with public and/or private cloud resources, allowing seamless workload migration, data sharing, and unified management.
AWS Elastic Container Service (ECS)
158. What is ECS?
Amazon ECS (Elastic Container Service) is a fully managed container orchestration service that allows you to run, scale, and secure Docker containers on AWS, using either EC2 instances or AWS Fargate for serverless compute.
159. What is the difference between ECS and EKS?
ECS is AWS’s native container orchestration service, simpler to use and tightly integrated with AWS. EKS is a managed Kubernetes service, offering open-source Kubernetes compatibility, more flexibility, and portability, but with increased complexity.
AWS Elastic Kubernetes Service (EKS)
160. What is EKS?
Amazon EKS (Elastic Kubernetes Service) is a fully managed Kubernetes service that simplifies running Kubernetes clusters on AWS, providing scalability, security, and integration with AWS services.
161. What is the difference between ECS and EKS?
ECS is AWS-native, easier to set up, and best for AWS-centric workloads. EKS offers standard Kubernetes orchestration, suitable for multi-cloud or hybrid environments and advanced container management.
162. Can you explain the difference between AWS Elastic Beanstalk and AWS Elastic Kubernetes Service (EKS)? When would you choose one over the other for a specific application or workload?
Elastic Beanstalk is for simple, managed application deployments with minimal configuration. EKS is for complex, large-scale, microservices, or multi-cloud workloads needing Kubernetes-native orchestration and customization. Choose Beanstalk for quick, straightforward deployments; choose EKS for advanced orchestration and control.
Conclusion
Mastering AWS interview questions across all experience levels is essential for anyone aiming to excel in the cloud computing field. By building a strong foundation in AWS fundamentals, practicing hands-on scenarios, and staying current with evolving services, you can confidently approach any interview. Consistent learning and real-world problem-solving will not only help you stand out to employers but also prepare you for ongoing success as the cloud landscape continues to grow and change.
If you want to dive deeper into AWS and build your expertise, you can explore the AWS Solution Architect Certification Training to gain a comprehensive understanding of AWS services, infrastructure, and deployment strategies. For more detailed insights, check out our What is AWS and AWS Tutorial. If you are preparing for an interview, explore our AWS Data Engineer Interview Questions.
FAQs
1. How do I prepare for an AWS interview?
Start by reviewing core AWS services like EC2, S3, Lambda, and VPC, and understand their use cases. Practice common interview questions, study the AWS Well-Architected Framework, and get hands-on experience with the AWS Console or labs. Also, be ready for scenario-based and behavioral questions, often using the STAR method, and review Amazon’s Leadership Principles.
2. What are the interview questions for AWS?
Interview questions cover AWS basics (e.g., What is EC2? What is S3?), architecture and best practices, security, cost optimization, scenario-based problem solving, and behavioral questions about teamwork and leadership. You may also be asked about your experience with specific AWS projects and services.
3. Is an AWS interview difficult?
AWS interviews can be challenging, especially for technical roles, as they test both your knowledge of AWS services and your problem-solving ability. Expect a mix of technical, scenario-based, and behavioral questions. With thorough preparation and hands-on practice, most candidates find them manageable.
4. What are AWS basics?
AWS basics include understanding core services like EC2 (virtual servers), S3 (object storage), RDS (managed databases), IAM (identity and access management), VPC (virtual private cloud), and Lambda (serverless computing). You should also know about regions, availability zones, and the pay-as-you-go cloud model.






























Hi,
Good Interview Questions and will useful to Aws Jobs. Find Aws jobs in peeljobs.com. Peeljobs is one of the best job portal in India. Job seekers can create their account or they can log in with their social networking sites like Facebook, G+, Twitter, LinkedIn, GitHub.
For this question Q: A company is deploying a new two-tier web application in AWS. The company has limited staff and requires high availability, and the application requires complex queries and table joins. Which configuration provides the solution for the company’s requirements?
Dynamo DB is incorrect answer. It should be RDS with MySQL in Multi-AZ configuration. Because Dynamo DB is not suitable for complex queries and Table Joins..
Here is some sample question and answers!
A group can contain many users. Can a user belong to multiple groups?
A. No
C. Yes always
B. Yes but only in VPC
D. Yes but only if they are using two factor authentication
Answer: B
A group can contain many users. Can a user belong to multiple groups?
A. No
B. Yes but only in VPC
C. Yes always
D. Yes but only if they are using two factor authentication
Answer: C
For which of the following use cases are Simple Workflow Service (SWF) and Amazon EC2 an appropriate solution? Choose 2 answers!
A. Using as an endpoint to collect thousands of data points per hour from a distributed fleet of sensors
B. Managing a multi-step and multi-decision checkout process of an e-commerce website
C. Orchestrating the execution of distributed and auditable business processes
D. Using as an SNS (Simple Notification Service) endpoint to trigger execution of video transcoding jobs
E. Using as a distributed session store for your web application
Answer: A,B
Step-by-step video tutorials that helps you in understanding the concepts and clearing the certification exam.
Hi and thanks a lot… but some answers seems strange, for example :
41. Which of the following use cases are suitable for Amazon DynamoDB? Choose 2 answers
A. Managing web sessions.
B. Storing JSON documents.
C. Storing metadata for Amazon S3 objects.
D. Running relational joins and complex updates.
Answer C,D.
For me correct answers are A, B and C (DynamoDB for relational joins ???)
Yeah I agree .. it should be A, B, and C
Hey Muhammad, thanks for checking out our blog.
Yes, Dynanmo Db isn’t used for any Complex relational queries. D shouldn’t be in the answer.
Hey Romain, thanks for checking out our blog.
Yes, Dynanmo Db isn’t used for any Complex relational queries. D shouldn’t be in the answer.
Get AWS Solution Architect Associate dumps from the leading organization Dumps4Download
Hi
I want to learn cloud computing, my background is SAP Basis admin for 2 yrs, I
know nothing about AWS. I am reading about it since a week. What would be
your professional advice? How long will it take to excel it, how about
the job market?
I have done my Bachelor of Arts then PG Dip in Computer
Applications.
I just want to drive my career uniquely. After a brief discussion about AWS, with one
of my friend who is a junior SAP Architect, I thought this is my career.
After I gone through Amazon site I understood that the
Solution architect – Associate is the first step in certification right? Please advice on AWS career plan and the
areas where I need to accumulate knowledge.
Hope for your valued response.
Thank you
Anand
Hey Anand, thanks for checking out our blog. With regard to your query, yes, you can go ahead with learning AWS considering your background. The time required to learn Cloud computing with AWS entirely depends on the time you spend to learn it. However, if you opt for a structured training, you should be ready in a month’s time. When we say ready, it means you will know about most components and how they work. Post that, you will need to spend time on trying out some POC’s to get skilled & become confident in the services provided by AWS. Coming to your last query, your first step should be to get into a structured training so that you are ready before you take your AWS Solution Archtect – Associate exam. And, yes, this is the first exam you need to clear before you can attempt the next one. Hope this helps. Cheers!
These questions are very helpful thank you for sharing this kind of information.
Explain BGP Border Gateway Protocol
Denial Service Attack
Proxy versus Reverse Proxy
Types of Loadbalancer
Which algorithm does an Elastic Load Balancer use?
HAPROXY VS NGINX (Comparing Load Balancing Options: Nginx vs. HAProxy vs. AWS ELB
MYSql Storage Engine
MySQL Architecture
Hadoop Acrchitecture & HDFS, Named Node, Data Node, MapReduce
Web 3 tier Architecture
RPO & RTO in disaster Recovery
Bandwidth Throughput Latency
Bandwidth MTU
OLAP and OLTP
Difference between SAN & NAS
Blue Green Deployment
Replication technologies available
Difference between XML & JSON
What is CI(continuous integration) tool and example
Docker
Container
Difference between Docker & Container
What is Memcache
Details of VLAN
Content Delivery/Distribution Network(CDN)
MS SQL to Oracle Migration
Platforms (Power, Sparc, Intel X86)
How do you perform caching?
Do you know EMR and Redshift?
What is the biggest mistake you have made?
What is EBS?
How do you architect a design that is fault tolerant?
What are the services you have used in AWS?
What are some web protocols?
What is TCP and UDP?