






Over the years, Kafka, the open-source message broker project developed by the Apache Software Foundation, has gained the reputation of being the numero uno data processing tool of choice. The exponential boom in the demand for working professionals with certified expertise in Apache Kafka is an evident proof of its growing value in the technological sphere. Written in the Scala language, Kafka provides a unified, high-throughput, low-latency platform for handling real-time data feeds. Kafka’s popularity can be credited to unique attributes that make it a highly attractive option for data integration. Features like scalability, data partitioning, low latency, and the ability to handle large number of diverse consumers make it a good fit for data integration related use cases.
The popularity of Kafka has brought with it, an array of job opportunities and career prospects around it. Having Kafka on your resume is a fast track to growth. In case you are looking to attend an Apache Kafka interview in the near future, do look at the Apache Kafka interview questions and answers below, that have been specially curated to help you crack your interview successfully. If you have attended Kafka interviews recently, we encourage you to add questions in the comments tab.
All the best!
1. What is Kafka?
Wikipedia defines Kafka as “an open-source message broker project developed by the Apache Software Foundation written in Scala and is a distributed publish-subscribe messaging system.
| Feature | Description |
| High Throughput | Support for millions of messages with modest hardware |
| Scalability | Highly scalable distributed systems with no downtime |
| Replication | Messages are replicated across the cluster to provide support for multiple subscribers and balances the consumers in case of failures |
| Durability | Provides support for persistence of message to disk |
| Stream Processing | Used with real-time streaming applications like Apache Spark & Storm |
| Data Loss | Kafka with proper configurations can ensure zero data loss |
2. List the various components in Kafka.
The four major components of Kafka are:
- Topic – a stream of messages belonging to the same type
- Producer – that can publish messages to a topic
- Brokers – a set of servers where the publishes messages are stored
- Consumer – that subscribes to various topics and pulls data from the brokers.
3. Explain the role of the offset.
Messages contained in the partitions are assigned a unique ID number that is called the offset. The role of the offset is to uniquely identify every message within the partition.
4. What is a Consumer Group?
Consumer Groups is a concept exclusive to Kafka. Every Kafka consumer group consists of one or more consumers that jointly consume a set of subscribed topics.
5. What is the role of the ZooKeeper?
Kafka uses Zookeeper to store offsets of messages consumed for a specific topic and partition by a specific Consumer Group.
6. Is it possible to use Kafka without ZooKeeper?
No, it is not possible to bypass Zookeeper and connect directly to the Kafka server. If, for some reason, ZooKeeper is down, you cannot service any client request.
7. Explain the concept of Leader and Follower.
Every partition in Kafka has one server which plays the role of a Leader, and none or more servers that act as Followers. The Leader performs the task of all read and write requests for the partition, while the role of the Followers is to passively replicate the leader. In the event of the Leader failing, one of the Followers will take on the role of the Leader. This ensures load balancing of the server.
8. What roles do Replicas and the ISR play?
Replicas are essentially a list of nodes that replicate the log for a particular partition irrespective of whether they play the role of the Leader. On the other hand, ISR stands for In-Sync Replicas. It is essentially a set of message replicas that are synced to the leaders.
9. Why are Replications critical in Kafka?
Replication ensures that published messages are not lost and can be consumed in the event of any machine error, program error or frequent software upgrades.
10. If a Replica stays out of the ISR for a long time, what does it signify?
It means that the Follower is unable to fetch data as fast as data accumulated by the Leader.
11. What is the process for starting a Kafka server?
Since Kafka uses ZooKeeper, it is essential to initialize the ZooKeeper server, and then fire up the Kafka server.
- To start the ZooKeeper server: > bin/zookeeper-server-start.sh config/zookeeper.properties
- Next, to start the Kafka server: > bin/kafka-server-start.sh config/server.properties
12. How do you define a Partitioning Key?
Within the Producer, the role of a Partitioning Key is to indicate the destination partition of the message. By default, a hashing-based Partitioner is used to determine the partition ID given the key. Alternatively, users can also use customized Partitions.
13. In the Producer, when does QueueFullException occur?
QueueFullException typically occurs when the Producer attempts to send messages at a pace that the Broker cannot handle. Since the Producer doesn’t block, users will need to add enough brokers to collaboratively handle the increased load.
14. Explain the role of the Kafka Producer API.
The role of Kafka’s Producer API is to wrap the two producers – kafka.producer.SyncProducer and the kafka.producer.async.AsyncProducer. The goal is to expose all the producer functionality through a single API to the client.
15. What is the main difference between Kafka and Flume?
Even though both are used for real-time processing, Kafka is scalable and ensures message durability.
These are some of the frequently asked Apache Kafka interview questions with answers. You can brush up on your knowledge of Apache Kafka with these blogs.
Got a question for us? Please mention it in the comments section and we will get back to you.
Related Posts:
Apache Kafka: What You Need for a Career in Real-Time Analytics







































Hello sir,
Faced some problem using Kafka in spring boot. When send a message to listener. listener listen message and done some validation on message and send back response like validation completed the message assign to new topic.But i want to listen the new topic. its taken some time to listen that topic. I hope you understand this question.
Example:
1) First create a Topic=”user” send to Consumer. Consumer listen the topic using @Kafkalistener done some validation on user. Send back to new topic like topic=”validation”. This is the problem i want read this topic takes some time. like 100ms.
Adding some more doubts,please try to clear these too
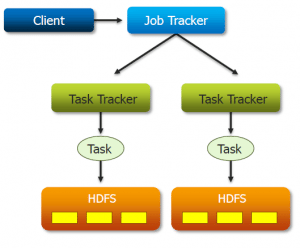
Consider 3 nodes in a Kafka cluster and producer is trying to write data1,data2,data3??
q1)how it find the leader,on what basis Election will happen?
q2)consider a scenerio ,data 1 is written in leader and replication didnt happend and in the middle of that
leader got down, what happend to that data1,weather data loss will happen??
q3)before replication weather a consumer can consume the data from leader(not yet replicated the data)?how?
q4)After sometime node 1 got up and it lost the leader position also then what will happen to the data written to that(not yet replicated),how it will replicate(replication will happen from leader to follower,here this node lost the leader position)
q5)consider a kafka streaming writing to HDFs,assume what will happen if 1 hour HDFS is down? what will happen to the data which
is incoming in these 1 hour?
Hi John,
I will try and answer your questions. Let me know if there are any gaps in my understanding.
q2) If the leader goes down before acknowledgement, this means Producer have also not received the confirmation about the message being successfully stored. Though this will also depend on the API implementation and you can handle such a scenario during coding
q3) No, ideally this scenario will not happen. There are 2 ways of replication Async and Sync. During the Sync method Leader waits for majority of the followers to confirm if the data has been replicated. While on the Async method leader does not wait for any ack from followers and mark the process as complete, this is not fault tolerant. But once the data process by leader is completed it updates the offset id, and also flushes the data to the disk if configured batch size is full. After all this processing only data is available for consumers to pull.
q4) Assume here that node here will have to be brought up, which again gets registered with the zookeeper and start loading up all data. Earlier partially consumed data will be considered lost.
q5) In such a case you have a P1 issue to resolve :) Without the disks the data cannot be persisted, and all the disk writes will start throwing up exceptions and nodes will be down.
Got one question in interview that the producer is sending messsages but consumer is not receiving any. What can be the reason?
Hey Puneet, thanks for checking out our blog. Currently, a topic partition is the smallest unit that we distribute messages among consumers in the same consumer group. So, if the number of consumers is larger than the total number of partitions in a Kafka cluster (across all brokers), some consumers will never get any data. The solution is to increase the number of partitions on the broker.
Why does my consumer never get any data?
By default, when a consumer is started for the very first time, it ignores all existing data in a topic and will only consume new data coming in after the consumer is started. If this is the case, try sending some more data after the consumer is started. Alternatively, you can configure the consumer by setting auto.offset.reset to “earliest” for the new consumer in 0.9 and “smallest” for the old consumer.
You can refer the below given official link of Apache foundation for more information: https://cwiki.apache.org/confluence/display/KAFKA/FAQ
Hope this helps. Cheers!