





It is essential to prepare yourself in order to pass an interview and land your dream job. Here’s the first step to achieving this. The following are some frequently asked Hadoop Administration interview questions and answers that might be useful.
Name the daemons required to run a Hadoop cluster?
| Daemon | Description |
| DataNode | It stores the data in the Hadoop File System which contains more than one DataNode, with data replicated across them |
| NameNode | It is the core of an HDFS that keeps the directory tree of all files is present in the file system, and tracks where the file data is kept across the cluster |
| SecondaryNameNode | It is a specially dedicated node in HDFS cluster that keep checkpoints of the file system metadata present on namenode |
| NodeManager | It is responsible for launching and managing containers on a node which execute tasks as specified by the AppMaster |
| ResourceManager | It is the master that helps in managing the distributed applications running on the YARN system by arbitrating all the available cluster resources |
How do you read a file from HDFS?
The following are the steps for doing this:
- The client uses a Hadoop client program to make the request.
- Client program reads the cluster config file on the local machine which tells it where the namemode is located. This has to be configured ahead of time.
- The client contacts the NameNode and requests the file it would like to read.
- Client validation is checked by username or by strong authentication mechanism like Kerberos.
- The client’s validated request is checked against the owner and permissions of the file.
- If the file exists and the user has access to it then the NameNode responds with the first block id and provides a list of datanodes a copy of the block can be found, sorted by their distance to the client (reader).
- The client now contacts the most appropriate datanode directly and reads the block data. This process repeats until all blocks in the file have been read or the client closes the file stream.
If while reading the file the datanode dies, the library will automatically attempt to read another replica of the data from another datanode. If all replicas are unavailable, the read operation fails and the client receives an exception. In case the information returned by the NameNode about block locations are outdated by the time the client attempts to contact a datanode, a retry will occur if there are other replicas or the read will fail. Explore and learn more about HDFS in this Big Data Course, which was designed by a Top Industry Expert from Big Data platform.
Explain checkpointing in Hadoop and why is it important?
Checkpointing is an essential part of maintaining and persisting filesystem metadata in HDFS. It’s crucial for efficient Namenode recovery and restart and is an important indicator of overall cluster health.
Namenode persists filesystem metadata. At a high level, namenode’s primary responsibility is to store the HDFS namespace. Meaning, things like the directory tree, file permissions and the mapping of files to block IDs. It is essential that this metadata are safely persisted to stable storage for fault tolerance.
This filesystem metadata is stored in two different parts: the fsimage and the edit log. The fsimage is a file that represents a point-in-time snapshot of the filesystem’s metadata. However, while the fsimage file format is very efficient to read, it’s unsuitable for making small incremental updates like renaming a single file. Thus, rather than writing a new fsimage every time the namespace is modified, the NameNode instead records the modifying operation in the edit log for durability. This way, if the NameNode crashes, it can restore its state by first loading the fsimage then replaying all the operations (also called edits or transactions) in the edit log to catch up to the most recent state of the namesystem. The edit log comprises a series of files, called edit log segments, that together represent all the namesystem modifications made since the creation of the fsimage.
What is default block size in HDFS and what are the benefits of having smaller block sizes?
Most block-structured file systems use a block size on the order of 4 or 8 KB. By contrast, the default block size in HDFS is 64MB – and larger. This allows HDFS to decrease the amount of metadata storage required per file. Furthermore, it allows fast streaming reads of data, by keeping large amounts of data sequentially organized on the disk. As a result, HDFS is expected to have very large files that are read sequentially. Unlike a file system such as NTFS or EXT which has numerous small files, HDFS stores a modest number of very large files: hundreds of megabytes, or gigabytes each. You can even check out the details of Big Data with the Data Engineering Course.
What are two main modules which help you interact with HDFS and what are they used for?
user@machine:hadoop$ bin/hadoop moduleName-cmdargs…
The moduleName tells the program which subset of Hadoop functionality to use. -cmd is the name of a specific command within this module to execute. Its arguments follow the command name.
The two modules relevant to HDFS are : dfs and dfsadmin.
The dfs module, also known as ‘FsShell’, provides basic file manipulation operations and works with objects within the file system. The dfsadmin module manipulates or queries the file system as a whole.
How can I setup Hadoop nodes (data nodes/namenodes) to use multiple volumes/disks?
Datanodes can store blocks in multiple directories typically located on different local disk drives. In order to setup multiple directories one needs to specify a comma separated list of pathnames as values under config paramters dfs.data.dir/dfs.datanode.data.dir. Datanodes will attempt to place equal amount of data in each of the directories.
Namenode also supports multiple directories, which stores the name space image and edit logs. In order to setup multiple directories one needs to specify a comma separated list of pathnames as values under config paramters dfs.name.dir/dfs.namenode.data.dir. The namenode directories are used for the namespace data replication so that image and log could be restored from the remaining disks/volumes if one of the disks fails.
What are schedulers and what are the three types of schedulers that can be used in Hadoop cluster?
Schedulers are responsible for assigning tasks to open slots on tasktrackers. The scheduler is a plug-in within the jobtracker. The three types of schedulers are:
- FIFO (First in First Out) Scheduler
- Fair Scheduler
- Capacity Scheduler
Get a better understanding of Hadoop clusters from the Big Data Course in Bangalore.
How do you decide which scheduler to use?
The CS scheduler can be used under the following situations:
- When you know a lot about your cluster workloads and utilization and simply want to enforce resource allocation.
- When you have very little fluctuation within queue utilization. The CS’s more rigid resource allocation makes sense when all queues are at capacity almost all the time.
- When you have high variance in the memory requirements of jobs and you need the CS’s memory-based scheduling support.
- When you demand scheduler determinism.
The Fair Scheduler can be used over the Capacity Scheduler under the following conditions:
- When you have a slow network and data locality makes a significant difference to a job runtime, features like delay scheduling can make a dramatic difference in the effective locality rate of map tasks.
- When you have a lot of variability in the utilization between pools, the Fair Scheduler’s pre-emption model affects much greater overall cluster utilization by giving away otherwise reserved resources when they’re not used.
- When you require jobs within a pool to make equal progress rather than running in FIFO order.
Why are ‘dfs.name.dir’ and ‘dfs.data.dir’ parameters used ? Where are they specified and what happens if you don’t specify these parameters?
DFS.NAME.DIR specifies the path of directory in Namenode’s local file system to store HDFS’s metadata and DFS.DATA.DIR specifies the path of directory in Datanode’s local file system to store HDFS’s file blocks. These paramters are specified in HDFS-SITE.XML config file of all nodes in the cluster, including master and slave nodes.
If these paramters are not specified, namenode’s metadata and Datanode’s file blocks related information gets stored in /tmp under HADOOP-USERNAME directory. This is not a safe place, as when nodes are restarted, data will be lost and is critical if Namenode is restarted, as formatting information will be lost.
What is file system checking utility FSCK used for? What kind of information does it show? Can FSCK show information about files which are open for writing by a client?
FileSystem checking utility FSCK is used to check and display the health of file system, files and blocks in it. When used with a path ( bin/Hadoop fsck / -files –blocks –locations -racks) it recursively shows the health of all files under the path. And when used with ‘/’ , it checks the entire file system. By Default FSCK ignores files still open for writing by a client. To list such files, run FSCK with -openforwrite option.
FSCK checks the file system, prints out a dot for each file found healthy, prints a message of the ones that are less than healthy, including the ones which have over replicated blocks, under-replicated blocks, mis-replicated blocks, corrupt blocks and missing replicas. You can even check out the details of Big Data with the Data Engineering Course in Australia.
What are the important configuration files that need to be updated/edited to setup a fully distributed mode of Hadoop cluster 1.x ( Apache distribution)?
The Configuration files that need to be updated to setup a fully distributed mode of Hadoop are:
- Hadoop-env.sh
- Core-site.xml
- Hdfs-site.xml
- Mapred-site.xml
- Masters
- Slaves
These files can be found in your Hadoop>conf directory. If Hadoop daemons are started individually using ‘bin/Hadoop-daemon.sh start xxxxxx’ where xxxx is the name of daemon, then masters and slaves file need not be updated and can be empty. This way of starting daemons requires command to be issued on appropriate nodes to start appropriate daemons. If Hadoop daemons are started using ‘bin/start-dfs.sh’ and ‘bin/start-mapred.sh’, then masters and slaves configurations files on namenode machine need to be updated.
Masters – Ip address/hostname of node where secondarynamenode will run.
Slaves –Ip address/hostname of nodes where datanodes will be run and eventually task trackers.
Learn all about the various properties of Namenode, Datanode and Secondary Namenode from the Hadoop Administration Course.
All the best!
Got a question for us? Please mention them in the comments section and we will get back to you.






































1Q)How many nodes do you think can be present in one cluster?
2Q)Which MapReduce version have you configured on your Hadoop cluster?
3Q)Explain any notable Hadoop use case by a company, that helped maximize its profitability?
4Q)Do you follow a standard procedure to deploy Hadoop?
5Q)How will you manage a Hadoop system?
6Q)Which tool will you prefer to use for monitoring Hadoop and HBase clusters?
Please answer to all of my questions in which ill make a note of all those answers and prepare for interviews.Thank you
Hey Omkar, that’s a really long list of questions. :) But, good news, we will be providing answers to many of these questions and more in an upcoming blog. Do subscribe to our blog to stay posted. Cheers!
4Q)ide the cluster size when setting up a Hadoop cluster?
5Q)How can you run Hadoop and real-time processes on the same cluster?
6Q)If you get a connection refused exception – when logging onto a machine of the cluster, what could be the reason? How will you solve this issue?
7Q)How can you identify and troubleshoot a long running job?
8Q)How can you decide the heap memory limit for a NameNode and Hadoop Service?
9Q)If the Hadoop services are running slow in a Hadoop cluster, what would be the root cause for it and how will you identify it?
10Q)Configure slots in Hadoop 2.0 and Hadoop 1.0.
11Q)In case of high availability, if the connectivity between Standby and Active NameNode is lost. How will this impact the Hadoop cluster?
12Q)What is the minimum number of ZooKeeper services required in Hadoop 2.0 and Hadoop 1.0?
13QIf the hardware quality of few machines in a Hadoop Cluster is very low. How will it affect the performance of the job and the overall performance of the cluster?
14Q)Explain the difference between blacklist node and dead node.
15Q)How can you increase the NameNode heap memory?
16Q)Configure capacity scheduler in Hadoop.
17Q)After restarting the cluster, if the MapReduce jobs that were working earlier are failing now, what could have gone wrong while restarting?
18Q)Explain the steps to add and remove a DataNode from the Hadoop cluster.
In a large busy Hadoop cluster-how can you identify a long running job?
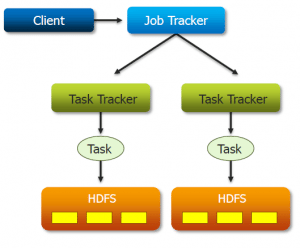
19Q)When NameNode is down, what does the JobTracker do?
20Q)When configuring Hadoop manually, which property file should be modified to configure slots?
21Q)How will you add a new user to the cluster?
22Q)What is the advantage of speculative execution? Under what situations, Speculative Execution might not be beneficial?
1Q)How will you initiate the installation process if you have to setup a Hadoop Cluster for the first time?
2Q)How will you install a new component or add a service to an existing Hadoop cluster?
3Q)If Hive Metastore service is down, then what will be its impact on the Hadoop cluster?
Hey Omkar, thanks for checking out our tutorial! Here are the answers:
1.You can do it virtually by using VMware Tools or Virtual box. You need atleast 8 GB RAM and sufficient hard disk space. Create 3 Virtual machines and make one of them a namenode and making the rest of two as datanodes by changing the configurations and providing privileges.
Now for connection between the nodes, for multinode clustering you need to assign the ip address of the datanodes in the /etc/hosts file in the namenode machine. After establishing connection you can get to know how a cluster works.
2.Using Hortonworks distribution, you can use Apache Ambari for adding/removing service to hadoop cluster.
Cloudera also provides its own cluster manager called Cloudera Management Service.
These tools provides easy installation of services. if in case you are not using these distribution you need to do manually the set up of services on nodes.
3.It is not mandatory to have metastore in the cluster itself. Any machine(inside or outside the cluster) having a JDBC-compliant database can be used for the metastore.
Hence, if the Hive metastore service is down, Hadoop cluster just works fine.
Hive data (not metadata) is spread across Hadoop HDFS DataNode servers. Typically, each block of data is stored on 3 different DataNodes. The NameNode keeps track of which DataNodes have which blocks of actual data.
For a Hive production environment, the metastore service should run in an isolated JVM. Hive processes can communicate with the metastore service using Thrift. The Hive metastore data is persisted in an ACID database such as Oracle DB or MySQL. You can use SQL to find out what is in the Hive metastore.
Hope this helps. Cheers!
Thanks a ton!! i also posted some more questions on your blog expecting the same from your end asap.
There are multiple server and client application components
If I say that zookeeper server is configured to maintain the cluster configuration, does the server component run on namenode and zookeeper client component run on datanodes?
+aefwon, thanks for checking out our blog! Zookeeper stores configuration data and settings in a centralized repository so that it can be accessed from anywhere.
https://uploads.disquscdn.com/images/c5f3a452b198457744712313fdb791cc1c2729e1980c92c3393473364ae6b378.png
Hadoop ZooKeeper is a distributed application that follows a simple client-server model where clients are nodes that make use of the service, and servers are nodes that provide the service. Multiple server nodes are collectively called ZooKeeper ensemble. At any given time, one ZooKeeper client is connected to at least one ZooKeeper server. A master node is dynamically chosen in consensus within the ensemble; thus usually, an ensemble of Zookeeper is an odd number so that there is a majority of vote. If the master node fails, another master is chosen in no time and it takes over the previous master. Hope this helps. Cheers!
what is the default number of zookeeper services run in hadoop and WHY that many number?
Hey Prashant, thanks for checking out the blog. To answer your query, by default no zookeeper runs unless until we start it. Now, once we start the zookeper then only one zookeeper will be running as it is daemon but if you want to run more daemons then we have to go for multinode cluster where we can install zookeeper on each system. But for one system there will be one zookeeper. Hope this helps.
Thank u for the rely and answer Edureka…I was asked in an interview that what is the default zookeeper services running, i said 3, Interviewer: asked me why 3 y not 1, 2, 4 and so on..
Glad we could help. :) Cheers!
how to restart a cluster without making the namenode shutdown
Can we actually do that?
Hey Ayan, please refer to the response above. Cheers!
Hey Omkar, thanks for checking out the blog. In general, restarting the cluster means restarting all the services of Hadoop. But if you want to restart the a cluster without stopping the Namenode service, please follow the steps given below:
1. Stop all the daemons except namenode
mr-jobhistory-daemon.sh stop historyserver
yarn-daemons.sh stop nodemanager
yarn-daemon.sh stop resourcemanager
hadoop-daemons.sh stop datanode
2. Enter the namenode into safemode and save the namespace
hadoop dfsadmin -safemode enter
hadoop dfsadmin –saveNamespace
3. Now For starting the cluster : Leave the safemode for namenode
hadoop dfsadmin -safemode leave
4. Start all the daemons except namenode
Hope this helps!