
Advanced DevOps Certification Training with G ...
- 24k Enrolled Learners
- Weekend
- Live Class
(7990)





 Copy Link!
Copy Link!
I really liked working with Git. Git plays a vital role in many organizations to achieve DevOps and is a must-know technology. This reason drives me to prepare you for the most frequently asked Git interview questions.
After a lot of research and discussion with many DevOps-certified experts with more than 10 years of experience in their domain and frequently taking interviews, I have collected the set of questions below.
This Git Interview Questions blog is a part of the parent blog DevOps Interview Questions. It includes all the DevOps Stages.
In this blog, we have covered around 50 questions and we have divided them into 3 categories –
| Git | SVN |
Git is a Decentralized Version Control tool | SVN is a Centralized Version Control tool |
It belongs to the 3rd generation of Version Control tools | It belongs to the 2nd generation of Version Control tools |
Clients can clone entire repositories on their local systems | Version history is stored on a server-side repository |
Commits are possible even if offline | Only online commits are allowed |
Push/pull operations are faster | Push/pull operations are slower |
Works are shared automatically by commit | Nothing is shared automatically |
I will suggest you attempt this question by first telling about the architecture of git as shown in the below diagram just try to explain the diagram by saying:
Git is a Distributed Version Control system(DVCS). It lets you track changes made to a file and allows you to revert back to any particular change that you wish.
It is a distributed architecture that provides many advantages over other Version Control Systems (VCS) like SVN. One of the major advantages is that it does not rely on a central server to store all the versions of a project’s files.
Instead, every developer “clones” a copy of a repository I have shown in the diagram with “Local repository” and has the full history of the project available on his hard drive. So when there is a server outage all you need to do to recover is one of your teammate’s local Git repository.
There is a central cloud repository where developers can commit changes and share them with other teammates.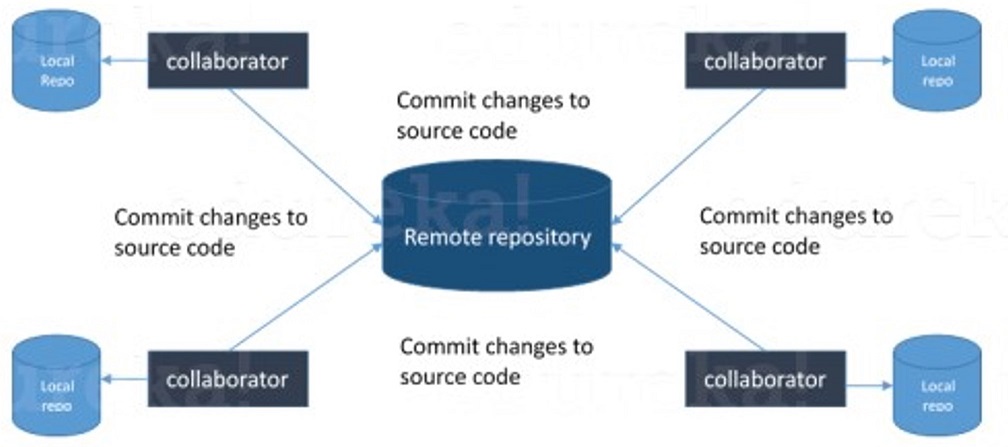
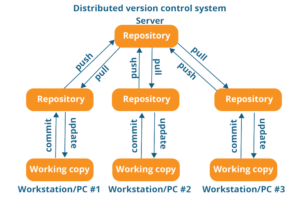
These are the systems that don’t rely on a central server to store a project file and all its versions.
In Distributed VCS, every contributor can get a local copy or “clone” of the main repository.
As you can see in the above diagram, every programmer can maintain a local repository which is actually the copy or clone of the central repository which is present on their hard drive. They can commit and update their local repository without any hassles.
With an operation called “pull”, they can update their local repositories with new data from the central server and “pull” operation affects changes to the main repository from their local repository.
Git is a version control system of distributed nature that is used to track changes in source code during software development. It aids in coordinating work among programmers, but it can be used to track changes in any set of files. The main objectives of Git are speed, data integrity, and support for distributed, non-linear workflows.
GitHub is a Git repository hosting service, plus it adds many of its own features. GitHub provides a Web-based graphical interface. It also provides access control and several collaboration features, basic task management tools for every project.
With the Version Control System(VCS), all the team members are allowed to work freely on any file at any time. VCS gives you the flexibility to merge all the changes into a common version.
All the previous versions and variants are neatly packed up inside the VCS. You can request any version at any time as per your requirement and you’ll have a snapshot of the complete project right at hand.
Whenever you save a new version of your project, your VCS requires you to provide a short description of the changes that you have made. Additionally, you can see what changes are made in the file’s content. This helps you to know what changes have been made in the project and by whom.
A distributed VCS like Git allows all the team members to have a complete history of the project so if there is a breakdown in the central server you can use any of your teammate’s local Git repository.
Instead of just telling the name of the language, you need to tell the reason for using it as well. I will suggest you to answer this by saying:
Git uses ‘C’ language. GIT is fast, and ‘C’ language makes this possible by reducing the overhead of run times associated with high-level languages.
The command that is used to write a commit message is “git commit -a”.
Now explain about -a flag by saying -a on the command line instructs git to commit the new content of all tracked files that have been modified. Also, mention you can use “git add <file>” before git commit -a if new files need to be committed for the first time.
In order to fix any broken commit, use the command “git commit --amend”. When you run this command, you can fix the broken commit message in the editor.
Repository in Git is a place where Git stores all the files. Git can store the files either on the local repository or on the remote repository.
This is probably the most frequently asked question and the answer to this is really simple.
To create a repository, create a directory for the project if it does not exist, then run the command “git init”. By running this command .git directory will be created in the project directory.
A “bare” repository in Git contains information about the version control and no working files (no tree) and it doesn’t contain the special .git sub-directory. Instead, it contains all the contents of the .git sub-directory directly in the main directory itself, whereas the working directory consists of :
Git can handle on its own most merges by using its automatic merging features. There arises a conflict when two separate branches have made edits to the same line in a file, or when a file has been deleted in one branch but edited in the other. Conflicts are most likely to happen when working in a team environment.
‘git instaweb’ is used to automatically direct a web browser and run a webserver with an interface into your local repository.
‘git is-tree’ represents a tree object including the mode and the name of each item and the SHA-1 value of the blob or the tree.
Below are some basic Git commands:
| Command | Function |
git rm [file] | deletes the file from your working directory and stages the deletion. |
git log | list the version history for the current branch. |
| shows the metadata and content changes of the specified commit. |
| used to give tags to the specified commit. |
| used to switch from one branch to another. creates a new branch and also switches to it. |
The following steps will resolve conflict in Git-
Identify the files that have caused the conflict.
Make the necessary changes in the files so that conflict does not arise again.
Add these files by the command git add.
Finally to commit the changed file using the command git commit
There can be two approaches to tackle this question and make sure that you include both because any of the below options can be used depending on the situation:
Remove or fix the bad file in a new commit and then push it to the remote repository. This is the most obvious way to fix an error. Once you have made necessary changes to the file, then commit it to the remote repository using the command: git commit -m “commit message”
Also, you can create a new commit that undoes all changes that were made in the bad commit. To do this use the command
git revert <name of bad commit>
SubGit is a tool for SVN to Git migration. It can create a writable Git mirror of a local or remote Subversion repository and use both Subversion and Git as long as you like.
Now you can also include some advantages like you can do a fast one-time import from Subversion to Git or use SubGit within Atlassian Bitbucket Server. We can use SubGit to create a bi-directional Git-SVN mirror of an existing Subversion repository. You can push to Git or commit to Subversion as per your convenience. Synchronization will be done by SubGit.
Git pull command pulls new changes or commits from a particular branch from your central repository and updates your target branch in your local repository.
Git fetch is also used for the same purpose but it works in a slightly different way. When you perform a git fetch, it pulls all new commits from the desired branch and stores it in a new branch in your local repository. If you want to reflect these changes in your target branch, git fetch must be followed with a git merge. Your target branch will only be updated after merging the target branch and fetched branch. Just to make it easy for you, remember the equation below:
Git pull = git fetch + git merge
That before completing the commits, it can be formatted and reviewed in an intermediate area known as ‘Staging Area’ or ‘Index’. From the diagram it is evident that every change is first verified in the staging area I have termed it as “stage file” and then that change is committed to the repository.

The files which were stashed and saved in the stash index list will be recovered back. Any untracked files will be lost. Also, it is a good idea to always stage and commit your work or stash them.
If you want to fetch the log references of a particular branch or tag then run the command – “git reflog <ref_name>”.
Often, when you’ve been working on part of your project, things are in a messy state and you want to switch branches for some time to work on something else. The problem is, you don’t want to do a commit of half-done work just so you can get back to this point later. The answer to this issue is Git stash.
Stashing takes your working directory that is, your modified tracked files and staged changes and saves it on a stack of unfinished changes that you can reapply at any time.
If you want to continue working where you had left your work then ‘git stash apply‘ command is used to bring back the saved changes onto your current working directory.
‘git diff ’ depicts the changes between commits, commit and working tree, etc. whereas ‘git status’ shows you the difference between the working directory and the index, it is helpful in understanding a git more comprehensively. ‘git diff’ is similar to ‘git status’, the only difference is that it shows the differences between various commits and also between the working directory and index.
‘git remote add’ creates an entry in your git config that specifies a name for a particular URL whereas ‘git clone’ creates a new git repository by copying an existing one located at the URL
Git ‘stash drop’ command is used to remove the stashed item. It will remove the last added stash item by default, and it can also remove a specific item if you include it as an argument.
Now give an example.
If you want to remove a particular stash item from the list of stashed items you can use the below commands:
git stash list: It will display the list of stashed items like:
stash@{0}: WIP on master: 049d078 added the index file
stash@{1}: WIP on master: c264051 Revert “added file_size”
stash@{2}: WIP on master: 21d80a5 added number to log
If you want to remove an item named stash@{0} use command git stash drop stash@{0}.
For this answer instead of just telling the command, explain what exactly this command will do.
To get a list file that has changed in a particular commit use the below command:
git diff-tree -r {hash}
Given the commit hash, this will list all the files that were changed or added in that commit. The -r flag makes the command list individual files, rather than collapsing them into root directory names only.
You can also include the below-mentioned point, although it is totally optional but will help in impressing the interviewer.
The output will also include some extra information, which can be easily suppressed by including two flags:
git diff-tree --no-commit-id --name-only -r {hash}
Here –no-commit-id will suppress the commit hashes from appearing in the output, and –name-only will only print the file names, instead of their paths.
Git uses your username to associate commits with an identity. The git config command can be used to change your Git configuration, including your username.
Now explain with an example.
Suppose you want to give a username and email id to associate a commit with an identity so that you can know who has made a particular commit. For that I will use:
git config –global user.name “Your Name”: This command will add a username.
git config –global user.email “Your E-mail Address”: This command will add an email id.
Commit object contains the following components, you should mention all the three points presented below:
Feature branching – A feature branch model keeps all of the changes for a particular feature inside of a branch. When the feature is fully tested and validated by automated tests, the branch is then merged into master.
Task branching – In this model, each task is implemented on its own branch with the task key included in the branch name. It is easy to see which code implements which task, just look for the task key in the branch name.
Release branching – Once the develop branch has acquired enough features for a release, you can clone that branch to form a Release branch. Creating this branch starts the next release cycle, so no new features can be added after this point, only bug fixes, documentation generation, and other release-oriented tasks should go in this branch. Once it is ready to ship, the release gets merged into master and tagged with a version number. In addition, it should be merged back into the develop branch, which may have progressed since the release was initiated.
In the end tell them that branching strategies vary from one organization to another so I know basic branching operations like delete, merge, checking out a branch, etc.
There is a fundamental difference between the forking workflow and other popular git workflows. Rather than using a single server-side to act as the “central” codebase, it gives every developer their own server-side repository. The Forking Workflow is commonly seen in public open-source projects.
A crucial advantage of the Forking Workflow is that contributions can be integrated without even needing everybody to push to a single central repository that leads to clean project history. Developers can push to their own server-side repositories, but only the project maintainer can push to the official repository.
If developers are ready to publish a local commit, then they push the commit to their own public repository and not the official one. After this, they go for a pull request with the main repository that lets the project maintainer know an update is ready to be integrated.
The answer is pretty direct.
To know if a branch has been merged into master or not you can use the below commands:
git branch --merged – It lists the branches that have been merged into the current branch.
git branch --no-merged – It lists the branches that have not been merged.
There are a couple of reasons for this –
This directory consists of shell scripts that are activated if you run the corresponding Git commands. For example, git will try to execute the post-commit script after you have run a commit.
One or more commits can be reverted through the use of git revert. This command, in a true sense, creates a new commit with patches that cancel out the changes introduced in specific commits. If in case the commit that needs to be reverted has already been published or changing the repository history is not an option then in such cases, git revert can be used to revert commits. If you run the following command then it will revert the last two commits:
git revert HEAD~2..HEAD
Alternatively, there is always an option to check out the state of a particular commit from the past and commit it anew.
One has to be careful during a git add, else you may end up adding files that you didn’t want to commit. However, git rm will remove it from both your staging area (index), as well as your file system (working tree), which may not be what you want.
Instead, use git reset:
git reset filename # or
echo filename >> .gitingore # add it to .gitignore to avoid re-adding it
This means that git reset <paths> is exactly the opposite of git add <paths>.
To record the history of the project, Gitflow workflow employs two parallel long-running branches – master and develop:
The command git cherry-pick is normally used to introduce particular commits from one branch within a repository onto a different branch. Another common use is to forward- or back-port commits from a maintenance branch to a development branch. This is in contrast with other ways such as merge and rebase which normally apply many commits onto another branch.
Consider:
git cherry-pick <commit-hash>
git diff-tree -r {hash}
Given the commit hash, this will list all the files that were changed or added in that commit. The -r flag makes the command list individual files, rather than collapsing them into root directory names only.
The output will also include some extra information, which can be easily suppressed by including a couple of flags:
git diff-tree --no-commit-id --name-only -r {hash}
Here –no-commit-id will suppress the commit hashes from appearing in the output, and –name-only will only print the file names, instead of their paths.
If you want to write the new commit message from scratch use the following command
git reset –soft HEAD~N &&git commit
If you want to start editing the new commit message with a concatenation of the existing commit messages then you need to extract those messages and pass them to Git commit for that I will use
git reset –soft HEAD~N &&git commit –edit -m”$(git log –format=%B –reverse .HEAD@{N})”
git bisect <subcommand> <options>I will suggest you to first give a small introduction to sanity checking.
Sanity or smoke test determines whether it is possible and reasonable to continue testing.
Now explain how to achieve this.
This can be done with a simple script related to the pre-commit hook of the repository. The pre-commit hook is triggered right before a commit is made, even before you are required to enter a commit message. In this script, one can run other tools, such as linters and perform sanity checks on the changes being committed into the repository.
Finally, give an example, you can refer the below script:
#!/bin/sh
files=$(git diff –cached –name-only –diff-filter=ACM | grep ‘.go$’)
if [ -z files ]; then
exit 0
fi
unfmtd=$(gofmt -l $files)
if [ -z unfmtd ]; then
exit 0
fi
echo “Some .go files are not fmt’d”
exit 1
This script checks to see if any .go file that is about to be committed needs to be passed through the standard Go source code formatting tool gofmt. By exiting with a non-zero status, the script effectively prevents the commit from being applied to the repository.
Step 1. Click on the manage jenkins button on your jenkins dashboard.
Step 2. Click on manage jenkins plugin.
Step 3: In the Plugins Page
Step 4: Once the plugins have been installed, go to Manage Jenkins on your Jenkins dashboard. You will see your plugins listed among the rest.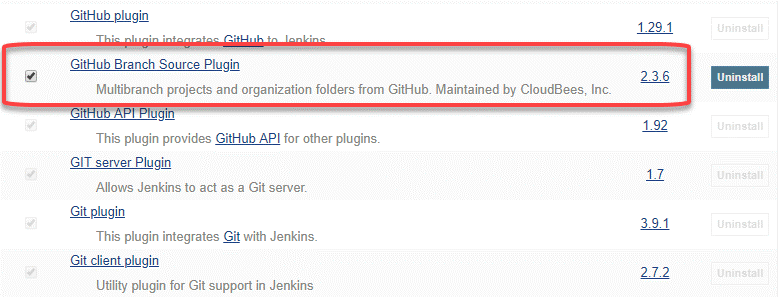
The ‘reflog’ command keeps a track of every single change made in the references (branches or tags) of a repository and keeps a log history of the branches and tags that were either created locally or checked out. Reference logs such as the commit snapshot of when the branch was created or cloned, checked-out, renamed, or any commits made on the branch are maintained by Git and listed by the ‘reflog’ command.
Note: The branch will be recoverable from your working directory only if the branch ever existed in your local repository i.e. the branch was either created locally or checked-out from a remote repository in your local repository for Git to store its reference history logs.
This command must be executed in the repository that had the lost branch. If you consider the remote repository situation, then you have to execute the reflog command on the developer’s machine who had the branch.
command: git reflog
Step 1: History logs of all the references
Get a list of all the local recorded history logs for all the references (‘master’, ‘uat’ and ‘prepod’) in this repository.
Step 2: Identify the history stamp
As you can see from the above snapshot, the highlighted commit id: e2225bb along with the HEAD pointer index:4 is the one when ‘preprod’ branch was created from the current HEAD pointer pointing to your latest work.
Step 3: Recover
If you want to recover back the ‘preprod‘ branch then use the command ‘git checkout’ passing the HEAD pointer reference with the index id – 4. This is the pointer reference when ‘preprod’ branch was created long commit id highlighted in the output screenshot.
I have included the frequently asked Git interview questions. If you have more questions in your mind just type it in the comment box below and we will reply you ASAP. Before going for the interview I will suggest you to check out this Git blog series.
If you found this Git Interview Questions relevant, check out the DevOps Certification Course by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. The Edureka DevOps Certification Training course helps learners gain expertise in various DevOps processes and tools such as Puppet, Jenkins, Nagios and GIT for automating multiple steps in SDLC.






























 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
How
git instaweb is used?
1.How
can you fix a broken commit?
2. Why is it advisable to create an
additional commit rather than amending an existing commit?