
Data Science with Python Certification Course
- 132k Enrolled Learners
- Weekend/Weekday
- Live Class
(49300)





 Copy Link!
Copy Link!Deep Learning is one of the Hottest topics of 2024 and for a good reason. There have been so many advancements in the Industry wherein the time has come when machines or Computer Programs are actually replacing Humans. Artificial Intelligence is going to create 85 million Jobs by 2025 and to crack those job interview I have come up with a set of Deep Learning Interview Questions. You can also check out Deep Learning Course by Edureka to get better understanding in this field. I have divided this article into two sections:
This Edureka Deep Learning Full Course video will help you understand and learn Deep Learning & Tensorflow in detail. This Deep Learning Tutorial is ideal for both beginners as well as professionals who want to master Deep Learning Algorithms.
Q1. Differentiate between AI, Machine Learning and Deep Learning.
Artificial Intelligence is a technique that enables machines to mimic human behavior.
Machine Learning is a subset of AI technique which uses statistical methods to enable machines to improve with experience.
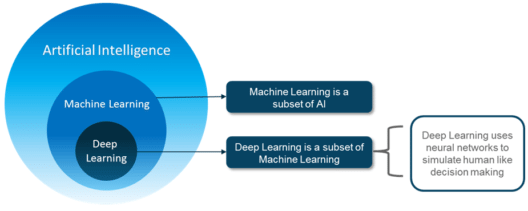
Deep learning is a subset of ML which make the computation of multi-layer neural network feasible. It uses Neural networks to simulate human-like decision making.
Q2. Do you think Deep Learning is Better than Machine Learning? If so, why?
Though traditional ML algorithms solve a lot of our cases, they are not useful while working with high dimensional data, that is where we have a large number of inputs and outputs. For example, in the case of handwriting recognition, we have a large amount of input where we will have a different type of inputs associated with different type of handwriting.
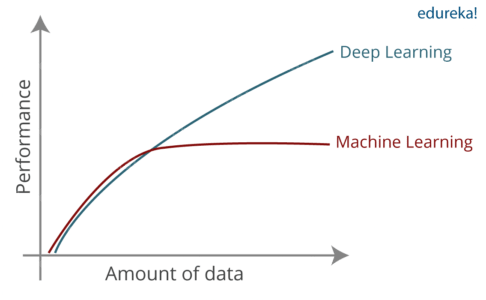
The second major challenge is to tell the computer what are the features it should look for that will play an important role in predicting the outcome as well as to achieve better accuracy while doing so.
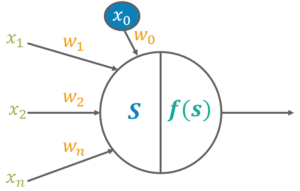
Q3. What is Perceptron? And How does it Work?
If we focus on the structure of a biological neuron, it has dendrites which are used to receive inputs. These inputs are summed in the cell body and using the Axon it is passed on to the next biological neuron as shown below.
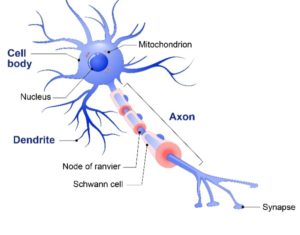
Similarly, a perceptron receives multiple inputs, applies various transformations and functions and provides an output. A Perceptron is a linear model used for binary classification. It models a neuron which has a set of inputs, each of which is given a specific weight. The neuron computes some function on these weighted inputs and gives the output.
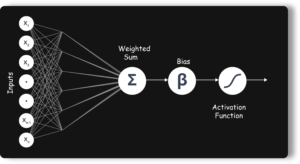
Q4. What is the role of weights and bias?
For a perceptron, there can be one more input called bias. While the weights determine the slope of the classifier line, bias allows us to shift the line towards left or right. Normally bias is treated as another weighted input with the input value x0.
ChatGPT Tutorial | ChatGPT Explained | What is ChatGPT ? | Edureka
This 𝐂𝐡𝐚𝐭𝐆𝐏𝐓 𝐓𝐮𝐭𝐨𝐫𝐢𝐚𝐥 is intended as a Crash Course on 𝐂𝐡𝐚𝐭𝐆𝐏𝐓 for Beginners. 𝐂𝐡𝐚𝐭𝐆𝐏𝐓 has been growing in popularity exponentially. But, 𝐂𝐡𝐚𝐭𝐆𝐏𝐓 is still not known to many people. In this video, I aim to show you the different ways in which you can use 𝐂𝐡𝐚𝐭𝐆𝐏𝐓 for yourself. 𝐂𝐡𝐚𝐭𝐆𝐏𝐓 has been the buzzword for a while now. This yap lab was put on the throne 5 days after its release and has been changing the game ever since.
Q5. What are the activation functions?
Activation function translates the inputs into outputs. Activation function decides whether a neuron should be activated or not by calculating the weighted sum and further adding bias with it. The purpose of the activation function is to introduce non-linearity into the output of a neuron.
There can be many Activation functions like:
Q6. Explain Learning of a Perceptron.

Wj (t+1) – Updated Weight
Wj (t) – Old Weight
d – Desired Output
y – Actual Output
x – Input
Q7. What is the significance of a Cost/Loss function?
A cost function is a measure of the accuracy of the neural network with respect to a given training sample and expected output. It provides the performance of a neural network as a whole. In deep learning, the goal is to minimize the cost function. For that, we use the concept of gradient descent.
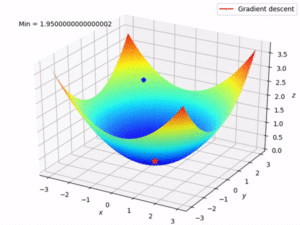
Q8. What is gradient descent?
Gradient descent is an optimization algorithm used to minimize some function by iteratively moving in the direction of steepest descent as defined by the negative of the gradient.
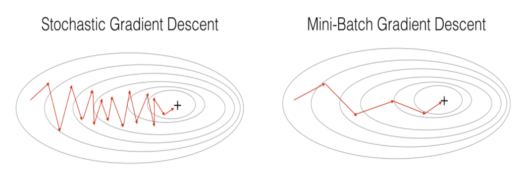
Stochastic Gradient Descent: Uses only a single training example to calculate the gradient and update parameters.
Batch Gradient Descent: Calculate the gradients for the whole dataset and perform just one update at each iteration.
Mini-batch Gradient Descent: Mini-batch gradient is a variation of stochastic gradient descent where instead of single training example, mini-batch of samples is used. It’s one of the most popular optimization algorithms.
Q9. What are the benefits of mini-batch gradient descent?
Q10.What are the steps for using a gradient descent algorithm?
Q11. Create a Gradient Descent in python.
params = [weights_hidden, weights_output, bias_hidden, bias_output] def sgd(cost, params, lr=0.05): grads = T.grad(cost=cost, wrt=params) updates = [] for p, g in zip(params, grads): updates.append([p, p - g * lr]) return updates updates = sgd(cost, params)
Q12. What are the shortcomings of a single layer perceptron?
Well, there are two major problems:
Q13. What is a Multi-Layer-Perceptron
A multilayer perceptron (MLP) is a deep, artificial neural network. It is composed of more than one perceptron. They are composed of an input layer to receive the signal, an output layer that makes a decision or prediction about the input, and in between those two, an arbitrary number of hidden layers that are the true computational engine of the MLP.
Q14. What are the different parts of a multi-layer perceptron?
Input Nodes: The Input nodes provide information from the outside world to the network and are together referred to as the “Input Layer”. No computation is performed in any of the Input nodes – they just pass on the information to the hidden nodes.
Hidden Nodes: The Hidden nodes perform computations and transfer information from the input nodes to the output nodes. A collection of hidden nodes forms a “Hidden Layer”. While a network will only have a single input layer and a single output layer, it can have zero or multiple Hidden Layers.
Output Nodes: The Output nodes are collectively referred to as the “Output Layer” and are responsible for computations and transferring information from the network to the outside world.
Q15. What Is Data Normalization And Why Do We Need It?
Data normalization is very important preprocessing step, used to rescale values to fit in a specific range to assure better convergence during backpropagation. In general, it boils down to subtracting the mean of each data point and dividing by its standard deviation.
These were some basic Deep Learning Interview Questions. Now, let’s move on to some advanced ones.
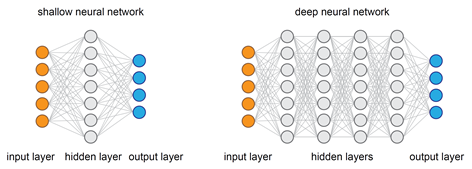
Q16. Which is Better Deep Networks or Shallow ones? and Why?
Both the Networks, be it shallow or Deep are capable of approximating any function. But what matters is how precise that network is in terms of getting the results. A shallow network works with only a few features, as it can’t extract more. But a deep network goes deep by computing efficiently and working on more features/parameters.
Q17. Why is Weight Initialization important in Neural Networks?
Weight initialization is one of the very important steps. A bad weight initialization can prevent a network from learning but good weight initialization helps in giving a quicker convergence and a better overall error.
Biases can be generally initialized to zero. The rule for setting the weights is to be close to zero without being too small.
Q18. What’s the difference between a feed-forward and a backpropagation neural network?
A Feed-Forward Neural Network is a type of Neural Network architecture where the connections are “fed forward”, i.e. do not form cycles. The term “Feed-Forward” is also used when you input something at the input layer and it travels from input to hidden and from hidden to the output layer.
Backpropagation is a training algorithm consisting of 2 steps:
So to be precise, forward-propagation is part of the backpropagation algorithm but comes before back-propagating.
Q19. What are the Hperparameteres? Name a few used in any Neural Network.
Hyperparameters are the variables which determine the network structure(Eg: Number of Hidden Units) and the variables which determine how the network is trained(Eg: Learning Rate). Hyperparameters are set before training.
Q20. Explain the different Hyperparameters related to Network and Training.
Network Hyperparameters

The number of Hidden Layers: Many hidden units within a layer with regularization techniques can increase accuracy. Smaller number of units may cause underfitting.
Network Weight Initialization: Ideally, it may be better to use different weight initialization schemes according to the activation function used on each layer. Mostly uniform distribution is used.
Activation function: Activation functions are used to introduce nonlinearity to models, which allows deep learning models to learn nonlinear prediction boundaries.
Training Hyperparameters

Learning Rate: The learning rate defines how quickly a network updates its parameters. Low learning rate slows down the learning process but converges smoothly. Larger learning rate speeds up the learning but may not converge.
Momentum: Momentum helps to know the direction of the next step with the knowledge of the previous steps. It helps to prevent oscillations. A typical choice of momentum is between 0.5 to 0.9.
The number of epochs: Number of epochs is the number of times the whole training data is shown to the network while training. Increase the number of epochs until the validation accuracy starts decreasing even when training accuracy is increasing(overfitting).
Batch size: Mini batch size is the number of sub-samples given to the network after which parameter update happens. A good default for batch size might be 32. Also try 32, 64, 128, 256, and so on.
Q21. What is Dropout?
Dropout is a regularization technique to avoid overfitting thus increasing the generalizing power. Generally, we should use a small dropout value of 20%-50% of neurons with 20% providing a good starting point. A probability too low has minimal effect and a value too high results in under-learning by the network.
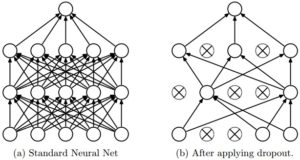
Use a larger network. You are likely to get better performance when dropout is used on a larger network, giving the model more of an opportunity to learn independent representations.
Q22. In training a neural network, you notice that the loss does not decrease in the few starting epochs. What could be the reason?
The reasons for this could be:
Q23. Name a few deep learning frameworks
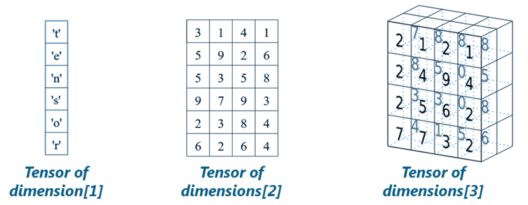
Q24. What are Tensors?
Tensors are nothing but a de facto for representing the data in deep learning. They are just multidimensional arrays, that allows you to represent data having higher dimensions. In general, Deep Learning you deal with high dimensional data sets where dimensions refer to different features present in the data set.
Q25. List a few advantages of TensorFlow?

Q26. What is Computational Graph?
A computational graph is a series of TensorFlow operations arranged as nodes in the graph. Each node takes zero or more tensors as input and produces a tensor as output.
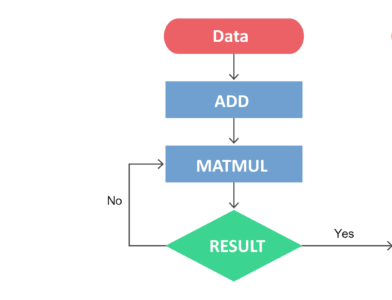
Basically, one can think of a Computational Graph as an alternative way of conceptualizing mathematical calculations that takes place in a TensorFlow program. The operations assigned to different nodes of a Computational Graph can be performed in parallel, thus, providing better performance in terms of computations.
Q27. What is a CNN?
Convolutional neural network (CNN, or ConvNet) is a class of deep neural networks, most commonly applied to analyzing visual imagery. Unlike neural networks, where the input is a vector, here the input is a multi-channeled image. CNNs use a variation of multilayer perceptrons designed to require minimal preprocessing.
Q28. Explain the different Layers of CNN.
There are four layered concepts we should understand in Convolutional Neural Networks:
Convolution: The convolution layer comprises of a set of independent filters. All these filters are initialized randomly and become our parameters which will be learned by the network subsequently.
ReLu: This layer is used with the convolutional layer.
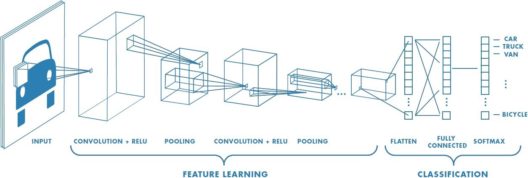
Pooling: Its function is to progressively reduce the spatial size of the representation to reduce the number of parameters and computation in the network. Pooling layer operates on each feature map independently.
Full Connectedness: Neurons in a fully connected layer have full connections to all activations in the previous layer, as seen in regular Neural Networks. Their activations can hence be computed with a matrix multiplication followed by a bias offset.
Q29. What is an RNN?
Recurrent Networks are a type of artificial neural network designed to recognize patterns in sequences of data, such as text, genomes, handwriting, the spoken word, numerical times series data. Recurrent Neural Networks use backpropagation algorithm for training Because of their internal memory, RNN’s are able to remember important things about the input they received, which enables them to be very precise in predicting what’s coming next.
Q30. What are some issues faced while training an RNN?
Recurrent Neural Networks use backpropagation algorithm for training, but it is applied for every timestamp. It is commonly known as Back-propagation Through Time (BTT).
There are some issues with Back-propagation such as:
Q31. What is Vanishing Gradient? And how is this harmful?
When we do Back-propagation, the gradients tend to get smaller and smaller as we keep on moving backward in the Network. This means that the neurons in the Earlier layers learn very slowly as compared to the neurons in the later layers in the Hierarchy.
Earlier layers in the Network are important because they are responsible to learn and detecting the simple patterns and are actually the building blocks of our Network.
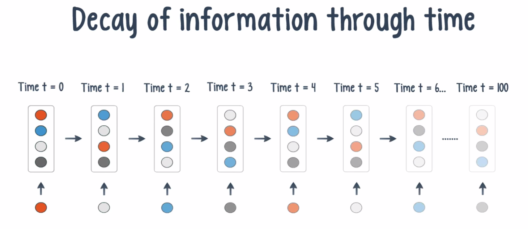
Obviously, if they give improper and inaccurate results, then how can we expect the next layers and the complete Network to perform nicely and produce accurate results. The Training process takes too long and the Prediction Accuracy of the Model will decrease.
Q32. What is Exploding Gradient Descent?
Exploding gradients are a problem when large error gradients accumulate and result in very large updates to neural network model weights during training.
Gradient Descent process works best when these updates are small and controlled. When the magnitudes of the gradients accumulate, an unstable network is likely to occur, which can cause poor prediction of results or even a model that reports nothing useful what so ever.
Q33. Explain the importance of LSTM.
Long short-term memory(LSTM) is an artificial recurrent neural network architecture used in the field of deep learning. Unlike standard feedforward neural networks, LSTM has feedback connections that make it a “general purpose computer”. It can not only process single data points, but also entire sequences of data.
They are a special kind of Recurrent Neural Networks which are capable of learning long-term dependencies.
Q34. What are capsules in Capsule Neural Network?
Capsules are a vector specifying the features of the object and its likelihood. These features can be any of the instantiation parameters like position, size, orientation, deformation, velocity, hue, texture and much more.
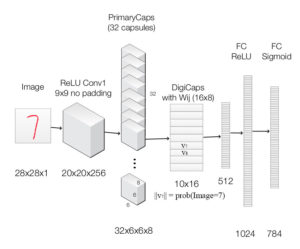
A capsule can also specify its attributes like angle and size so that it can represent the same generic information. Now, just like a neural network has layers of neurons, a capsule network can have layers of capsules.
Now, let’s continue this Deep Learning Interview Questions and move to the section of autoencoders and RBMs.
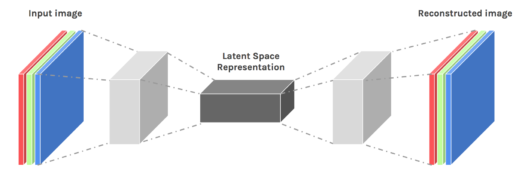
Q35. Explain Autoencoders and it’s uses.
An autoencoder neural network is an Unsupervised Machine learning algorithm that applies backpropagation, setting the target values to be equal to the inputs. Autoencoders are used to reduce the size of our inputs into a smaller representation. If anyone needs the original data, they can reconstruct it from the compressed data.
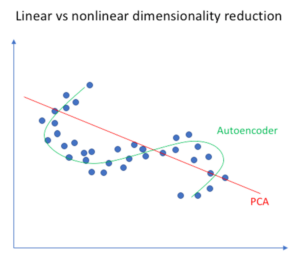
Q36. In terms of Dimensionality Reduction, How does Autoencoder differ from PCAs?
Q37. Give some real-life examples where autoencoders can be applied.
Image Coloring: Autoencoders are used for converting any black and white picture into a colored image. Depending on what is in the picture, it is possible to tell what the color should be.
Feature variation: It extracts only the required features of an image and generates the output by removing any noise or unnecessary interruption.
Dimensionality Reduction: The reconstructed image is the same as our input but with reduced dimensions. It helps in providing a similar image with a reduced pixel value.
Denoising Image: The input seen by the autoencoder is not the raw input but a stochastically corrupted version. A denoising autoencoder is thus trained to reconstruct the original input from the noisy version.
Q38. what are the different layers of Autoencoders?
An Autoencoder consist of three layers:
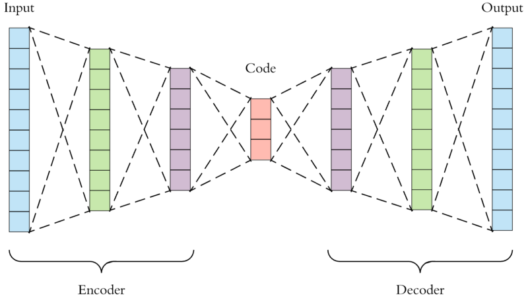
Q39. Explain the architecture of an Autoencoder.
Encoder: This part of the network compresses the input into a latent space representation. The encoder layer encodes the input image as a compressed representation in a reduced dimension. The compressed image is the distorted version of the original image.
Code: This part of the network represents the compressed input which is fed to the decoder.
Decoder: This layer decodes the encoded image back to the original dimension. The decoded image is a lossy reconstruction of the original image and it is reconstructed from the latent space representation.
Q40. What is a Bottleneck in autoencoder and why is it used?
The layer between the encoder and decoder, ie. the code is also known as Bottleneck. This is a well-designed approach to decide which aspects of observed data are relevant information and what aspects can be discarded.
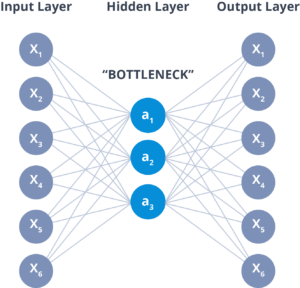
It does this by balancing two criteria:
Q41. Is there any variation of Autoencoders?
Q42. What are Deep Autoencoders?
The extension of the simple Autoencoder is the Deep Autoencoder. The first layer of the Deep Autoencoder is used for first-order features in the raw input. The second layer is used for second-order features corresponding to patterns in the appearance of first-order features. Deeper layers of the Deep Autoencoder tend to learn even higher-order features.
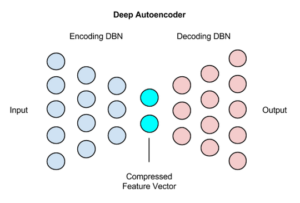
A deep autoencoder is composed of two, symmetrical deep-belief networks:
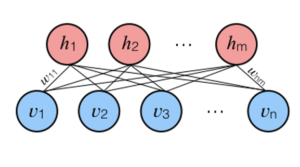
Q43. What is a Restricted Boltzmann Machine?
Restricted Boltzmann Machine is an undirected graphical model that plays a major role in Deep Learning Framework in recent times.
It is an algorithm which is useful for dimensionality reduction, classification, regression, collaborative filtering, feature learning, and topic modeling.
Q44. How Does RBM differ from Autoencoders?
Autoencoder is a simple 3-layer neural network where output units are directly connected back to input units. Typically, the number of hidden units is much less than the number of visible ones. The task of training is to minimize an error or reconstruction, i.e. find the most efficient compact representation for input data.
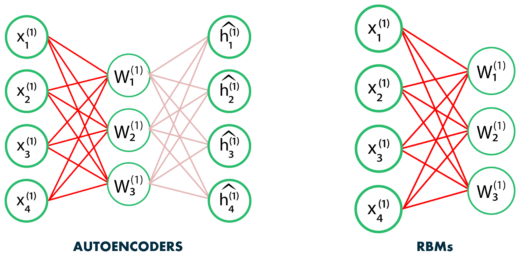
RBM shares a similar idea, but it uses stochastic units with particular distribution instead of deterministic distribution. The task of training is to find out how these two sets of variables are actually connected to each other.
One aspect that distinguishes RBM from other autoencoders is that it has two biases. The hidden bias helps the RBM produce the activations on the forward pass, while The visible layer’s biases help the RBM learn the reconstructions on the backward pass.
Now, Coming to the final questions of this “Deep Learning Interview Questions” series.
Q45. What are some limitations of deep learning?
So, with this, we come to an end of this Deep Learning Interview Questions article. I hope this set of questions will be enough to crack any Deep Learning Interview, but if you’re applying for any specific job, then you need to have sound knowledge of that industry as well because the jobs mostly are for specialists.
You can also check out the Deep Learning Course by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. This Certification Training is curated by industry professionals as per the industry requirements & demands. You will master the concepts such as SoftMax function, Autoencoder Neural Networks, Restricted Boltzmann Machine (RBM) and work with libraries like Keras & TFLearn.
Got a question for us? Please mention it in the comments section and we will get back to you.






































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP