
Data Science with Python Certification Course
- 131k Enrolled Learners
- Weekend
- Live Class
(49300)





 Copy Link!
Copy Link!
This blog is a guide on how to become a Data Scientist. One thing is for sure, you cannot become a data scientist overnight. It’s a journey, for sure and a challenging one.
I am assuming that you are a fresher, so if you are planning to begin your career in Data Science, there is a protracted sojourn.
But how do I go about becoming one?
Where should I start from?
What is my learning roadmap?
Which tools and techniques do I need to know?
How will I know when I have achieved my goal?
You may also go through this recording of “how to become a data scientist” where you can understand the topics in a detailed manner.
This video will explain all the skills required for becoming a modern day Data Scientist.
I have listed down all the skills required to become a Data Scientist:
Once you acquire these skills, Congratulations! You are a Data Scientist.
Below is the road map for becoming a Data Scientist.
Probably it took 5 minutes to read this post on how to become a Data Scientist, but yeah, be prepared for a long hectic journey in becoming one.
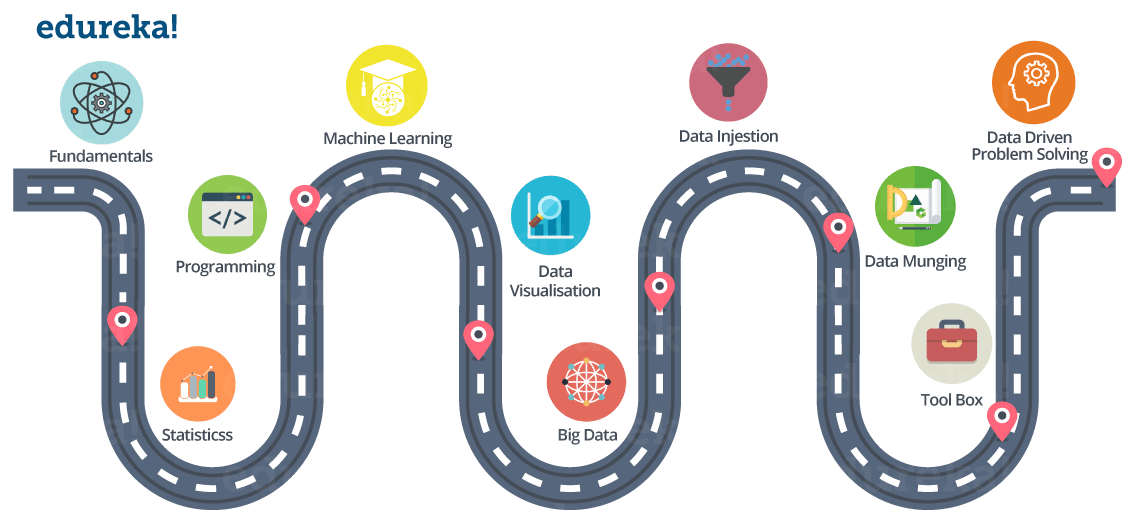
Now, let me explain all of these skills one by one. I hope that will make this blog more useful :)
This includes:
This includes:
I would suggest you to pick a dataset from UCI repo. and start right now!
Expertise in any one programming language, I would suggest ‘R’ or ‘Python.
You should understand what is Machine learning and how it works.
Understand different types of Machine Learning techniques:
Good knowledge on various Supervised and Unsupervised learning algorithms is required such as:
Nowadays everyone is talking about Deep Learning, as it solved a lot of limitations of traditional Machine Learning approaches. I would suggest you to understand how Deep Learning works. I have listed down few Deep Learning concepts that you should be familiar with:
Data visualization is a very important part of Data life-cycle.
Good hands-on knowledge is required on various visualization tools. Even, you can use a programming language for that purpose.
Below are few visualization tools:
Big Data is everywhere and there is almost an urgent need to collect and preserve whatever data is being generated, for the fear of missing out on something important.
There is a huge amount of data floating around. What we do with it is all that matters right now. This is why Big Data Analytics is in the frontiers of IT. Big Data Analytics has become crucial as it aids in improving business, decision makings and providing the biggest edge over the competitors. This applies for organizations as well as professionals in the Analytics domain.
As a Data Scientist it is very important to have knowledge about frameworks that can process Big Data. Two of the most famous ones are ‘Hadoop’ and ‘Spark’.
The process of importing , transferring , loading and processing data for later use or storage in a database is called Data Ingestion. This involves loading data from a variety of sources.
Below are few Data Ingestion tools:
If you have ever performed data analysis, you might have come across feature selection before you apply your Analytical model to the data.
So, in general, all the activity that you do on the raw data to make it “clean” enough to input to your analytical algorithm is data munging.
You can use ‘R’ and ‘Python’ packages for that.
It is one of the most important part of the data life-cycle.
As a Data Scientist you should be able to understand what all features are important in the dataset and what all features can be removed. You should also be able to identify your dependent variable or label.
Obviously, you have to remove inconsistency in the dataset.
All of these things are part of Data Munging (Data Wrangling).
You might find this section pretty redundant, but I think it is very very important to have good knowledge on certain tools like:
All the things we have discussed so far, includes tools and technologies that you can learn. But, Data-Driven problem solving approach is something that you need to develop. It will only come with experience.
A Data Scientist needs to know how to productively approach a problem.
This means identifying a situation’s
All of that in addition to knowing which data science methods to apply to the problem at hand.
I think I have pretty much covered everything. I hope you found this blog useful.
All the best for your journey in becoming a Data Scientist.








































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
A data scientist should define the business goals that are expected from the insights derived from ‘Big Data.