





We have learnt how to Build Hive and Yarn on Spark. Now let us try out Hive and Yarn examples on Spark.
![]()
Hive Example on Spark
We will run an example of Hive on Spark. We will create a table, load data in that table and execute a simple query. When working with Hive, one must construct a HiveContext which inherits from SQLContext.
Command: cd spark-1.1.1
Command: ./bin/spark-shell

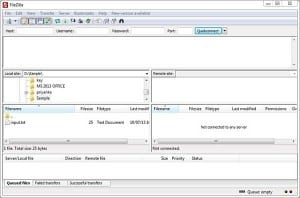
Create an input file ‘sample’ in your home directory as below snapshot (tab separated).

Command: val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)

Command: sqlContext.sql(“CREATE TABLE IF NOT EXISTS test (name STRING, rank INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘ ‘ LINES TERMINATED BY ‘
‘”)

Command: sqlContext.sql(“LOAD DATA LOCAL INPATH ‘/home/edureka/sample’ INTO TABLE test”)

Command: sqlContext.sql(“SELECT * FROM test WHERE rank < 5”).collect().foreach(println)

Yarn Example on Spark
We will run SparkPi example on Yarn. We can deploy Yarn on Spark in two modes : cluster mode and client mode. In yarn-cluster mode, the Spark driver runs inside an application master process which is managed by Yarn on the cluster, and the client can go away after initiating the application. In yarn-client mode, the driver runs in the client process, and the application master is only used for requesting resources from Yarn.
Command: cd spark-1.1.1
Command: SPARK_JAR=./assembly/target/scala-2.10/spark-assembly-1.1.1-hadoop2.2.0.jar ./bin/spark-submit –master yarn –deploy-mode cluster –class org.apache.spark.examples.SparkPi –num-executors 1 –driver-memory 2g –executor-memory 1g –executor-cores 1 examples/target/scala-2.10/spark-examples-1.1.1-hadoop2.2.0.jar

After you execute the above command, please wait for sometime till you get SUCCEEDED message.

Browse localhost:8088/cluster and click on the Spark application.

Click on logs.

Click on stdout to check the output.


For deploying Yarn on Spark in client mode, just make –deploy-mode as “client”. Now, you know how to build Hive and Yarn on Spark. We also did practicals on them.
Got a question for us? Please mention them in the comments section and we will get back to you.
Related Posts
Apache Spark Lighting up the Big Data World
Apache Spark with Hadoop-Why it matters?




































Hi i got an error. Whats this error? how to overcome?
Caused by: org.datanucleus.exceptions.NucleusException: Attempt to invoke the “dbcp-builtin” plugin to create a ConnectionPool gave an error : The specified datastore driver (“com.mysql.jdbc.Driver”) was not found in the CLASSPATH. Please check your CLASSPATH specification, and the name of the driver.
Hi Venu, It is not able to find the jdbc driver class. Add it in your driver classpath as follows:
./bin/spark-sql –driver-class-path /path/to/connector……jar
The connection jar will depend on database that has been set as metascore in hive.
If it MySql then the command would be:
/bin/spark-sql –driver-class-path /home/edureka/spark-1.1.1/lib/mysql-connector-java-5.1.32-bin.jar