





The quantity of digital data generated every day is growing exponentially with the advent of Digital Media, Internet of Things among other developments. This scenario has given rise to challenges in creating next generation tools and technologies to store and manipulate these data. This is where Hadoop Streaming comes in! Given below is a graph which depicts the growth of data generated annually in the world from 2013. IDC estimates that the amount of data created annually will reach 180 Zettabytes in 2025!
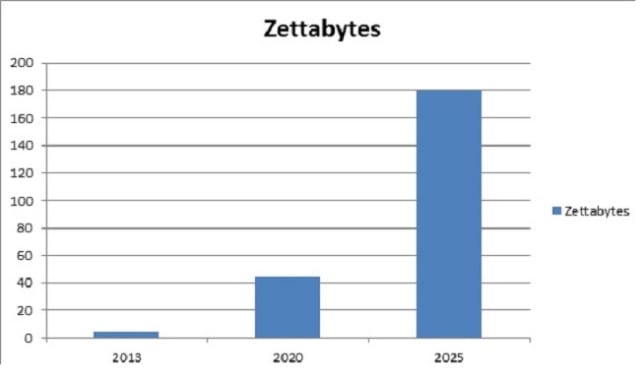
Source: IDC
IBM states that, every day, almost 2.5 quintillion bytes of data are created, with 90 percent of world’s data created in the last two years! It is a challenging task to store such an expansive amount of data. Hadoop can handle large volumes of structured and unstructured data more efficiently than the traditional enterprise Data Warehouse. It stores these enormous data sets across distributed clusters of computers. Hadoop Streaming uses MapReduce framework which can be used to write applications to process humongous amounts of data.
🐍 Ready to Unleash the Power of Python? Sign Up for Edureka’s Comprehensive Online instructor led Python Training with access to hundreds of Python learning Modules and 24/7 technical support.
Since MapReduce framework is based on Java, you might be wondering how a developer can work on it if he/ she does not have experience in Java. Well, developers can write mapper/Reducer application using their preferred language and without having much knowledge of Java, using Hadoop Streaming rather than switching to new tools or technologies like Pig and Hive. Learn more about Pig and Hive with help of this Big Data course designed by the Top Industry experts in Big Data Platform.
What is Hadoop Streaming?
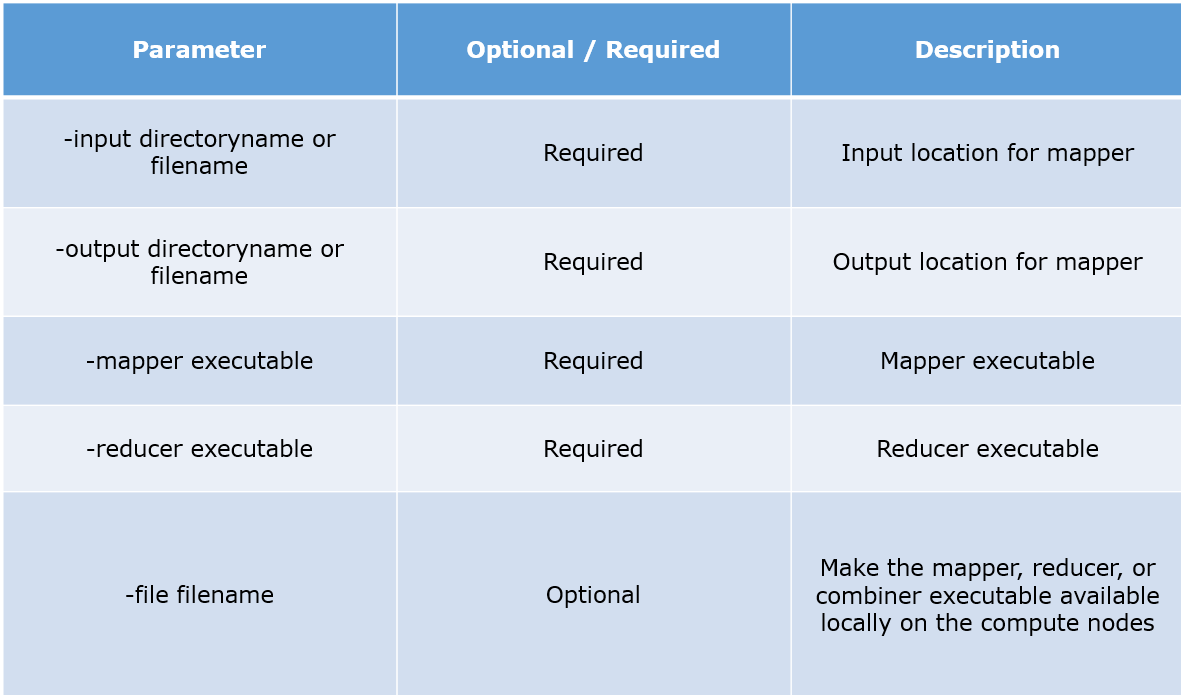
Hadoop Streaming is a utility that comes with the Hadoop distribution. It can be used to execute programs for big data analysis. Hadoop streaming can be performed using languages like Python, Java, PHP, Scala, Perl, UNIX, and many more. The utility allows us to create and run Map/Reduce jobs with any executable or script as the mapper and/or the reducer. For example:
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar
-input myInputDirs
-output myOutputDir
-mapper /bin/cat
-reducer /bin/wc
Parameters Description:
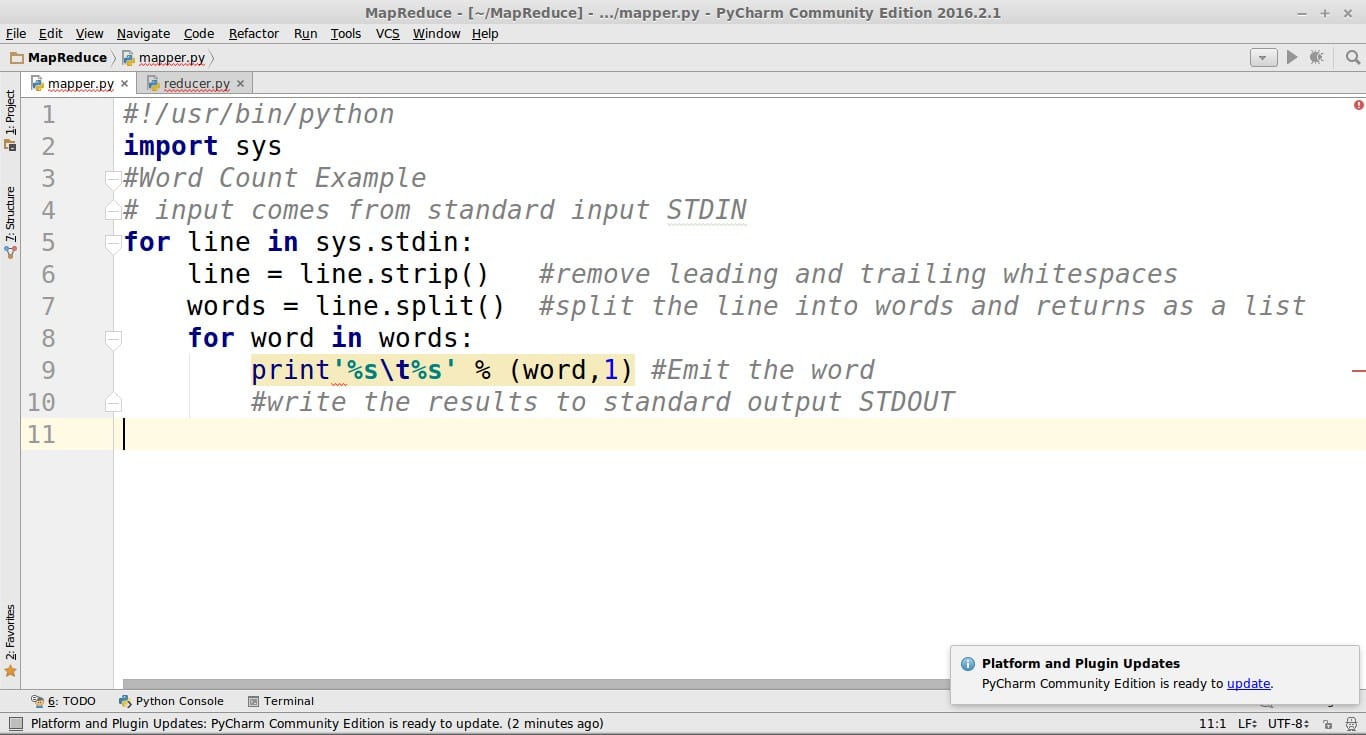
Python MapReduce Code:
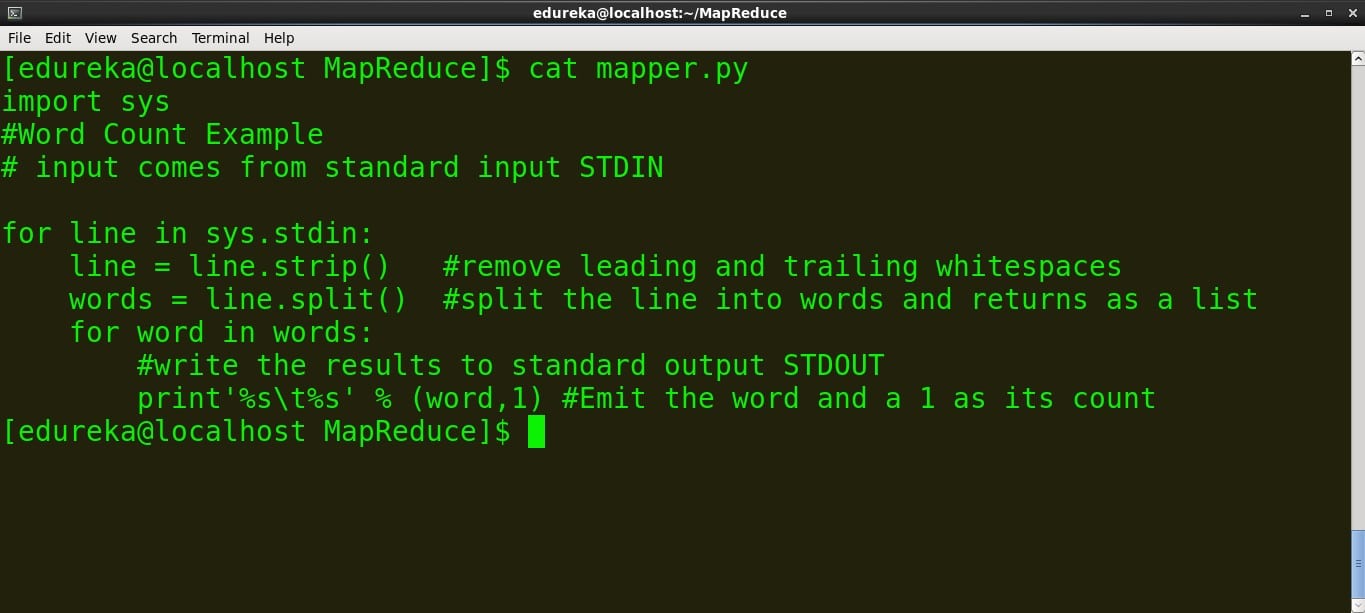
mapper.py #!/usr/bin/python import sys #Word Count Example # input comes from standard input STDIN for line in sys.stdin: line = line.strip() #remove leading and trailing whitespaces words = line.split() #split the line into words and returns as a list for word in words: #write the results to standard output STDOUT print'%s %s' % (word,1) #Emit the word
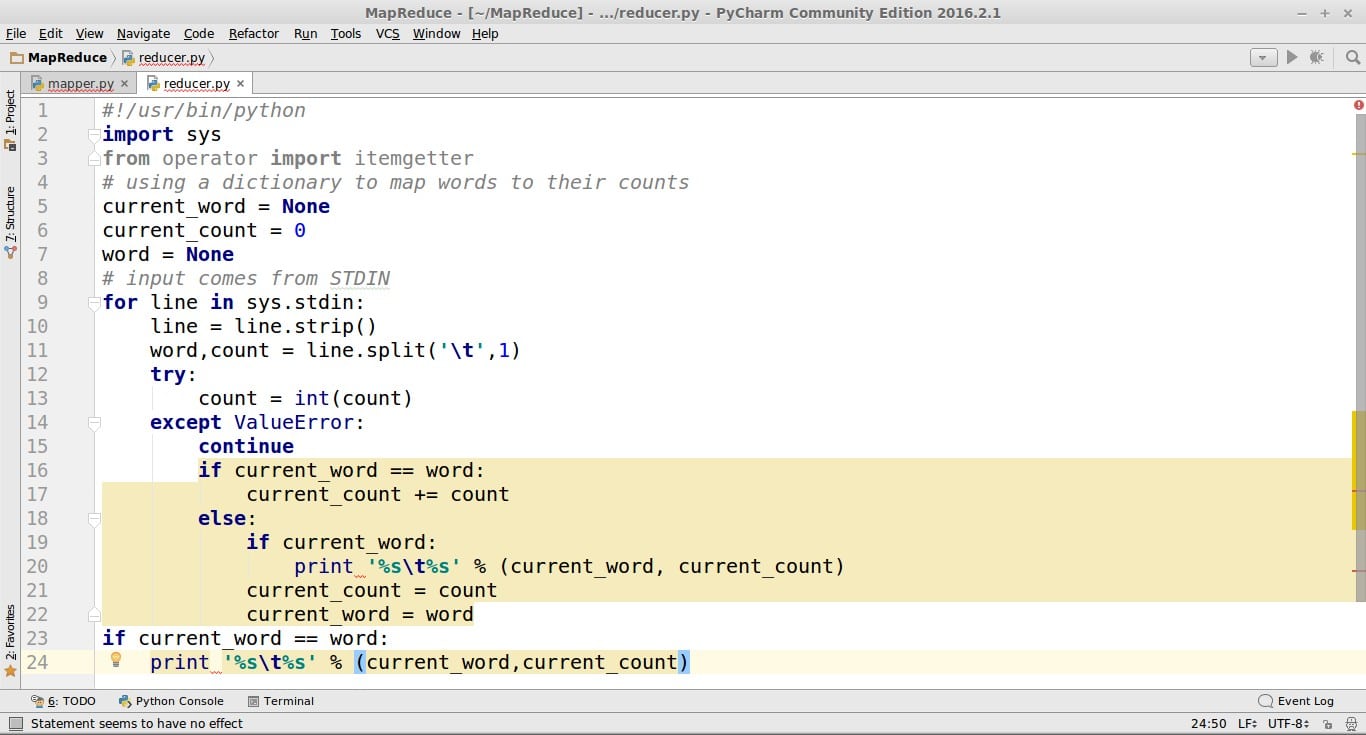
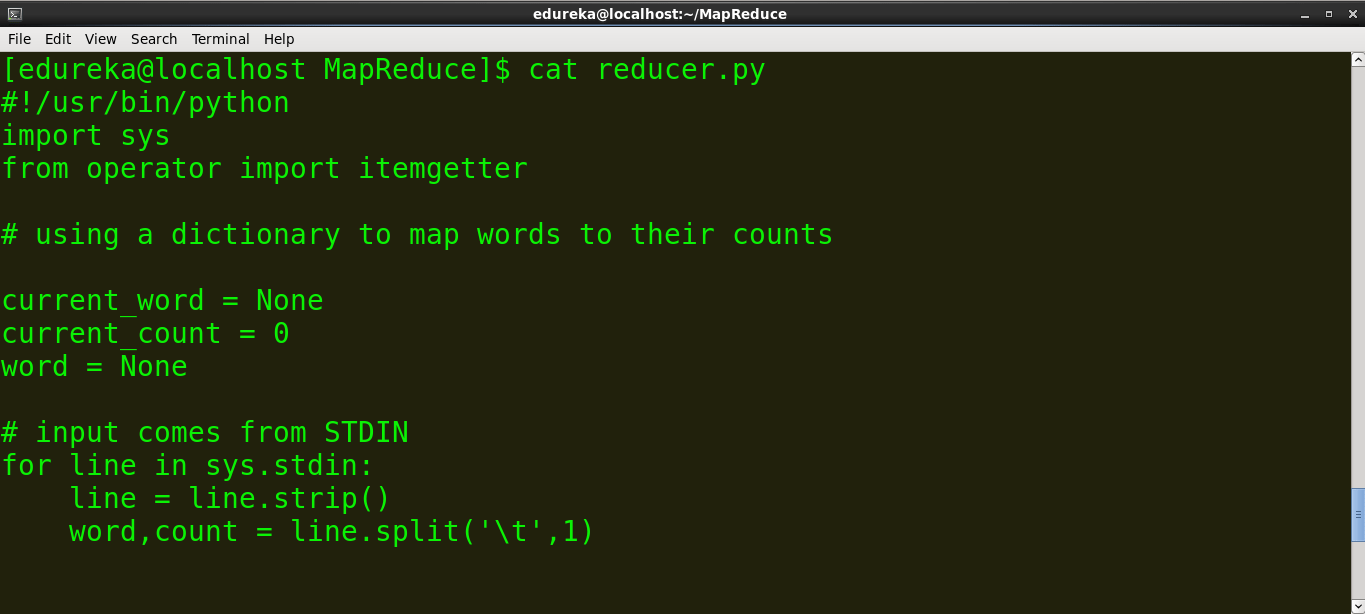
reducer.py
#!/usr/bin/python
import sys
from operator import itemgetter
# using a dictionary to map words to their counts
current_word = None
current_count = 0
word = None
# input comes from STDIN
for line in sys.stdin:
line = line.strip()
word,count = line.split(' ',1)
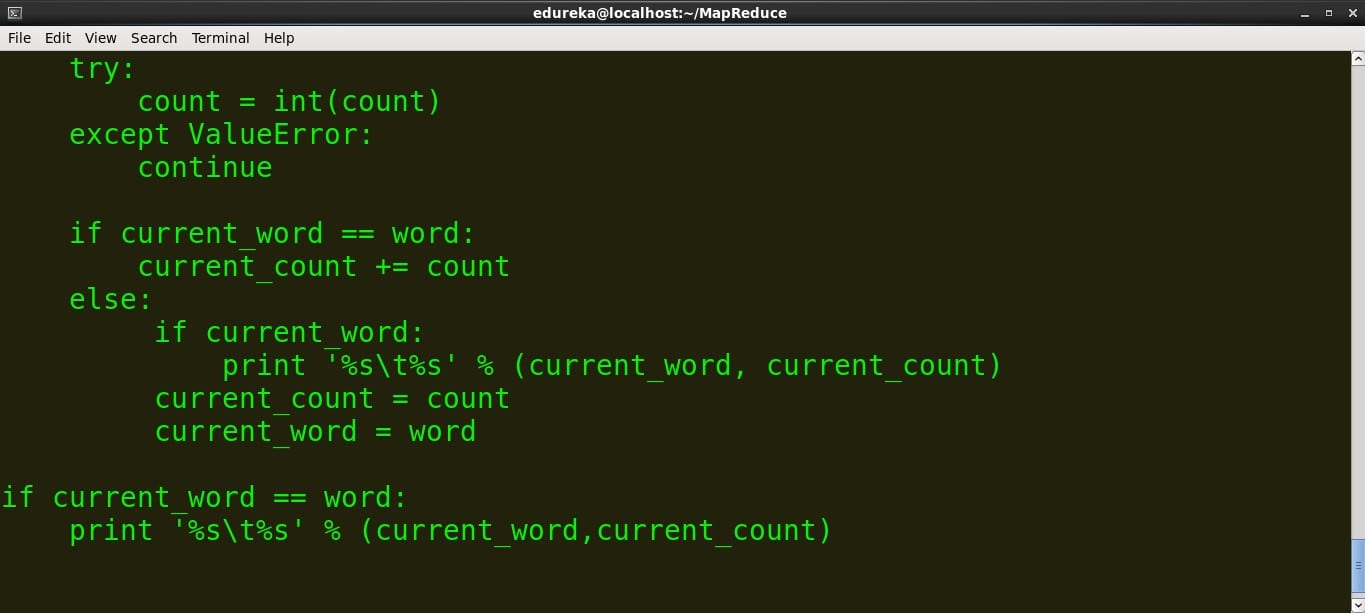
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
print '%s %s' % (current_word, current_count)
current_count = count
current_word = word
if current_word == word:
print '%s %s' % (current_word,current_count)
Run:
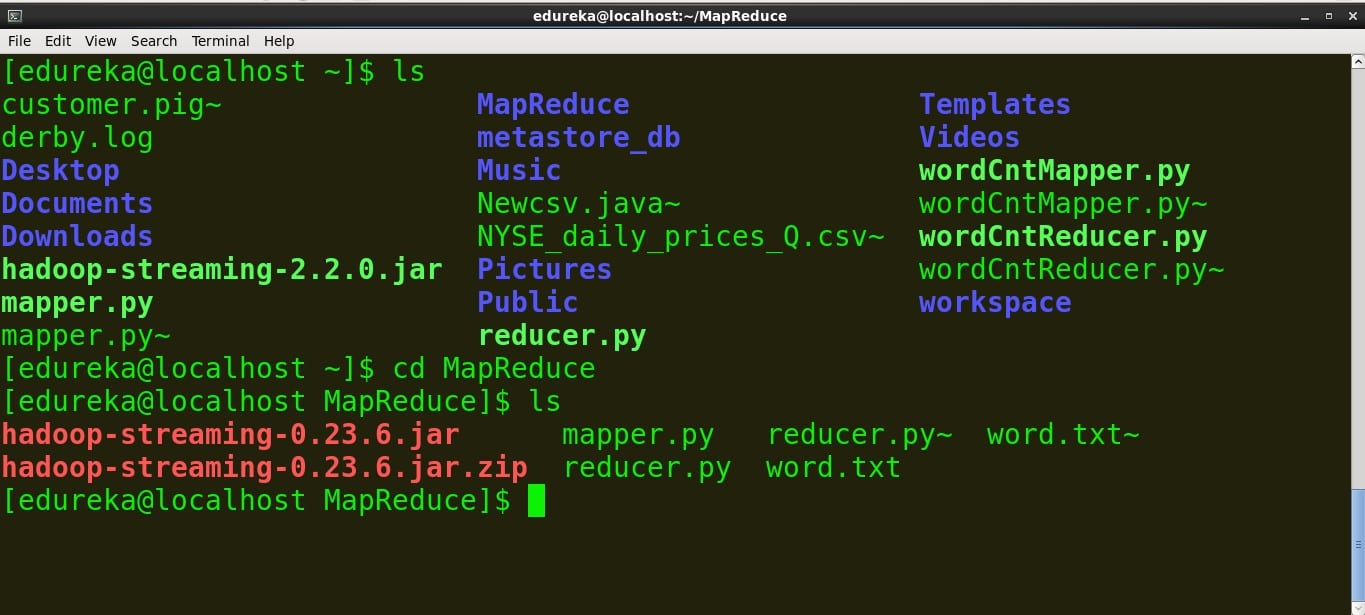
- Create a file with the following content and name it word.txt.
Cat mouse lion deer Tiger lion Elephant lion deer
- Copy the mapper.py and reducer.py scripts to the same folder where the above file exists.
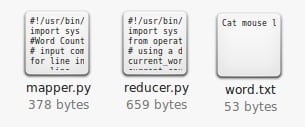
- Open terminal and Locate the directory of the file.Command:ls : to list all files in the directorycd : to change directory/folder
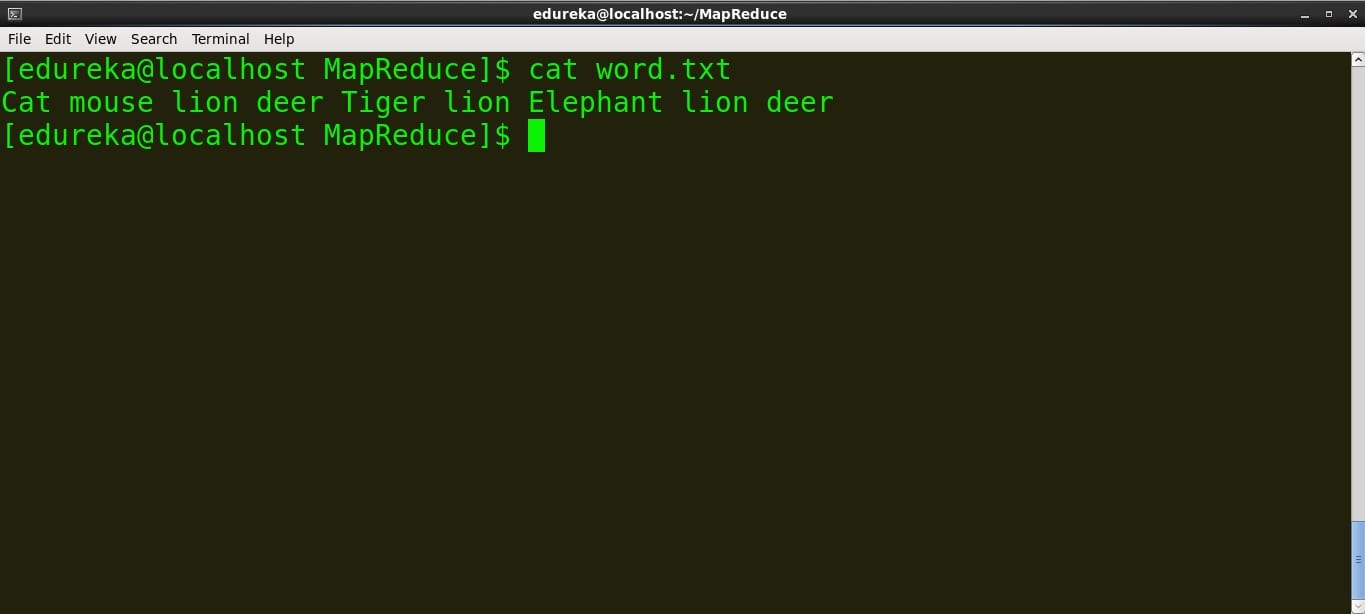
- See the content of the file.
Command: cat file_name
> content of mapper.py
command: cat mapper.py
>Content of reducer.py
command: cat reducer.py
We can run mapper and reducer on local files (ex: word.txt). In order to run the Map and reduce on the Hadoop Distributed File System (HDFS), we need the Hadoop Streaming jar. So before we run the scripts on HDFS, let’s run them locally to ensure that they are working fine.
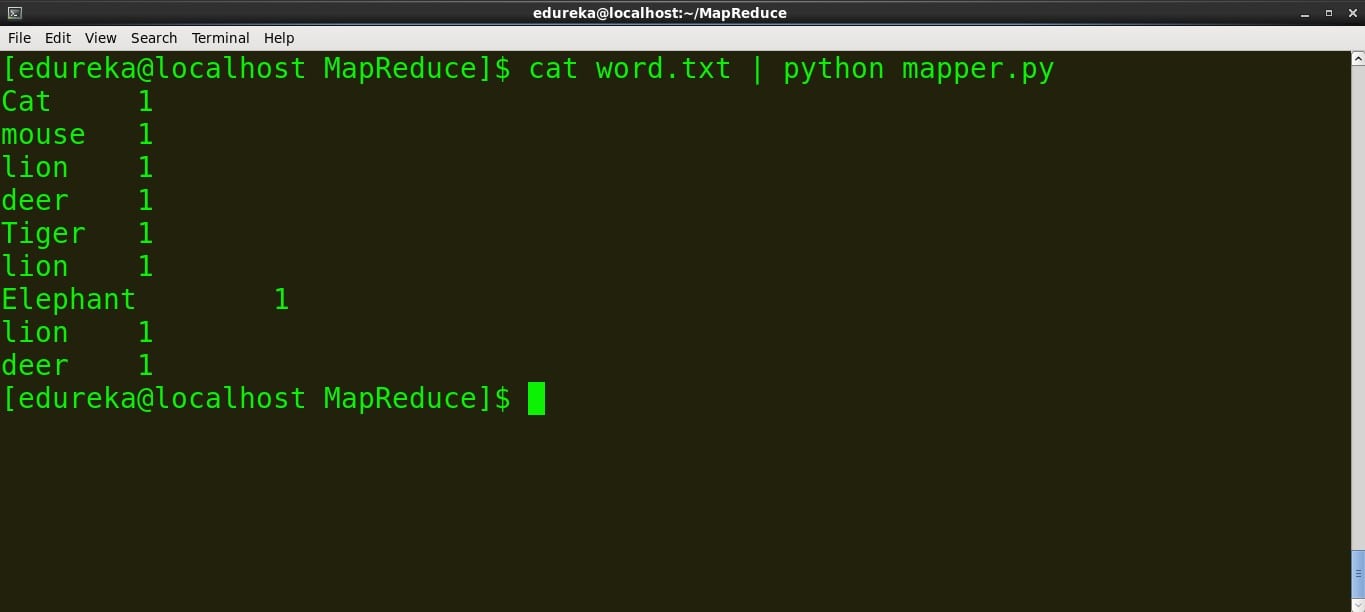
>Run the mapper
command: cat word.txt | python mapper.py
>Run reducer.py
command: cat word.txt | python mapper.py | sort -k1,1 | python reducer.py
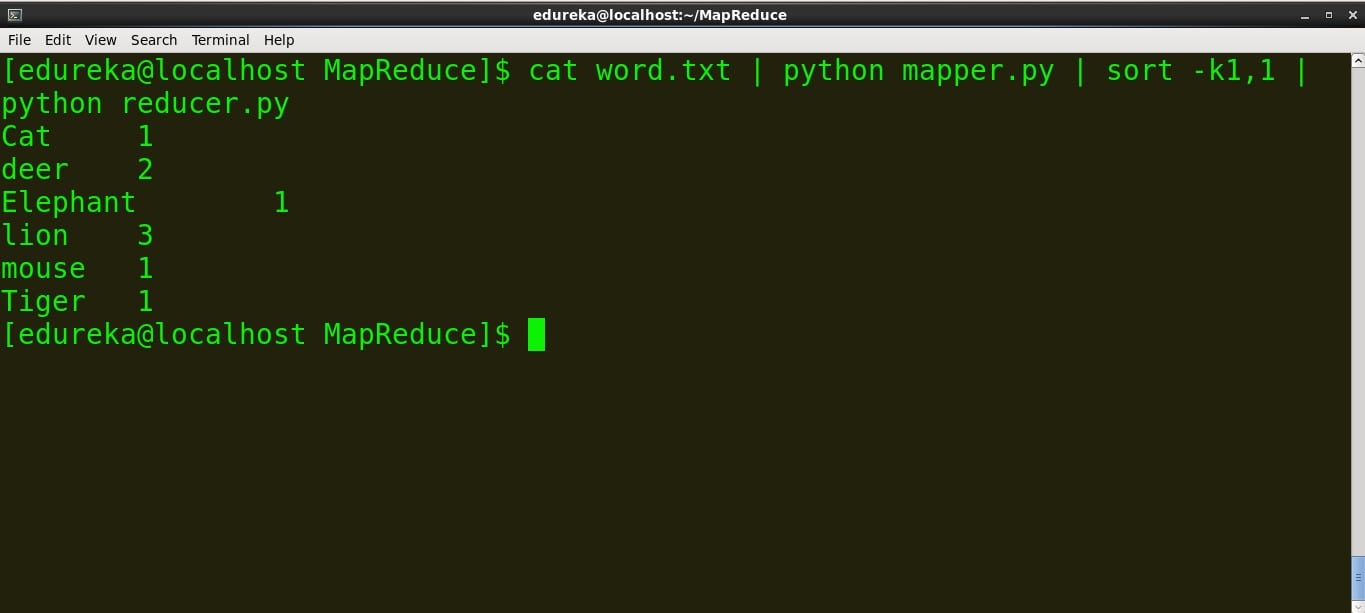
We can see that the mapper and reducer are working as expected so we won’t face any further issues.
Running the Python Code on Hadoop
Before we run the MapReduce task on Hadoop, copy local data (word.txt) to HDFS
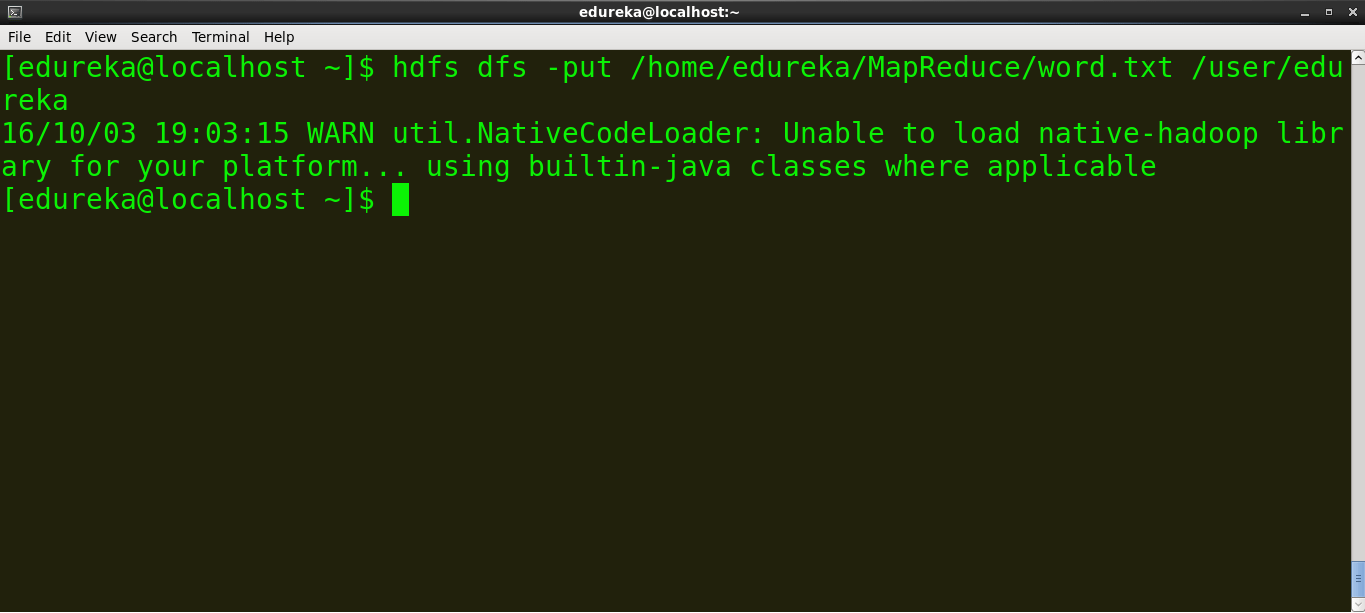
>example: hdfs dfs -put source_directory hadoop_destination_directory
command: hdfs dfs -put /home/edureka/MapReduce/word.txt /user/edureka
Copy the path of the jar file
The path of Hadoop Streaming jar based on the version of the jar is:
/usr/lib/hadoop-2.2.X/share/hadoop/tools/lib/hadoop-streaming-2.2.X.jar
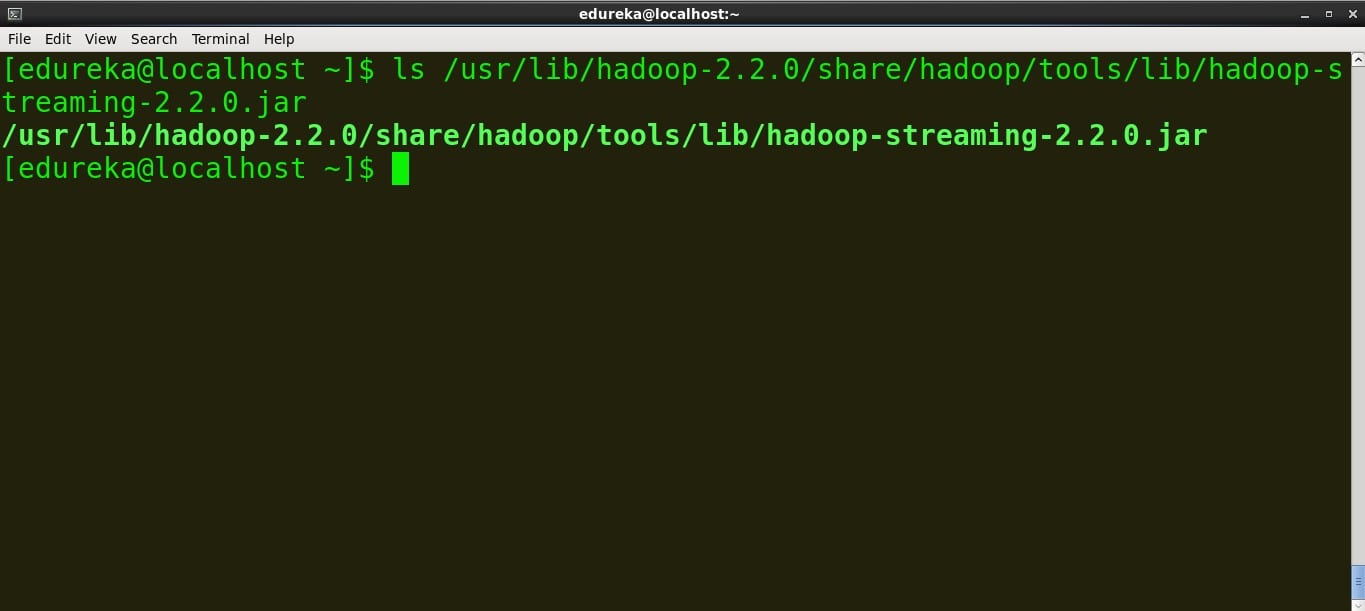
So locate the Hadoop Streaming jar on your terminal and copy the path.
command:
ls /usr/lib/hadoop-2.2.0/share/hadoop/tools/lib/hadoop-streaming-2.2.0.jar
Run the MapReduce job
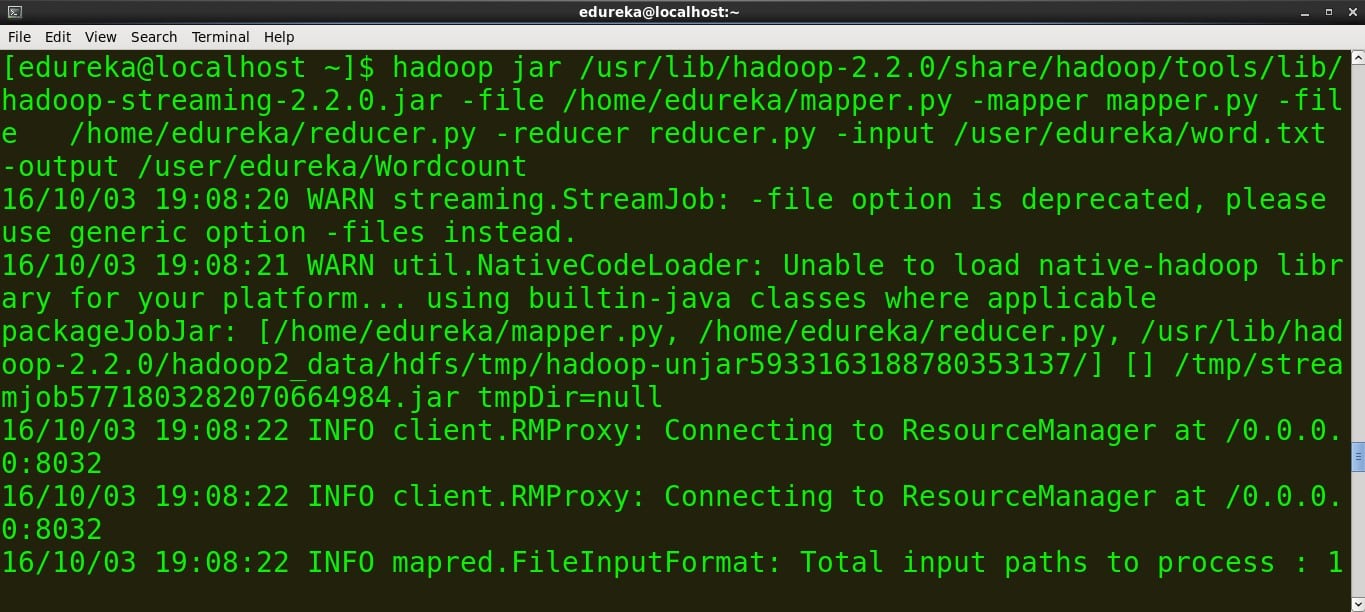
command:
hadoop jar /usr/lib/hadoop-2.2.0/share/hadoop/tools/lib/hadoop-streaming-2.2.0.jar -file /home/edureka/mapper.py -mapper mapper.py -file /home/edureka/reducer.py -reducer reducer.py -input /user/edureka/word -output /user/edureka/Wordcount
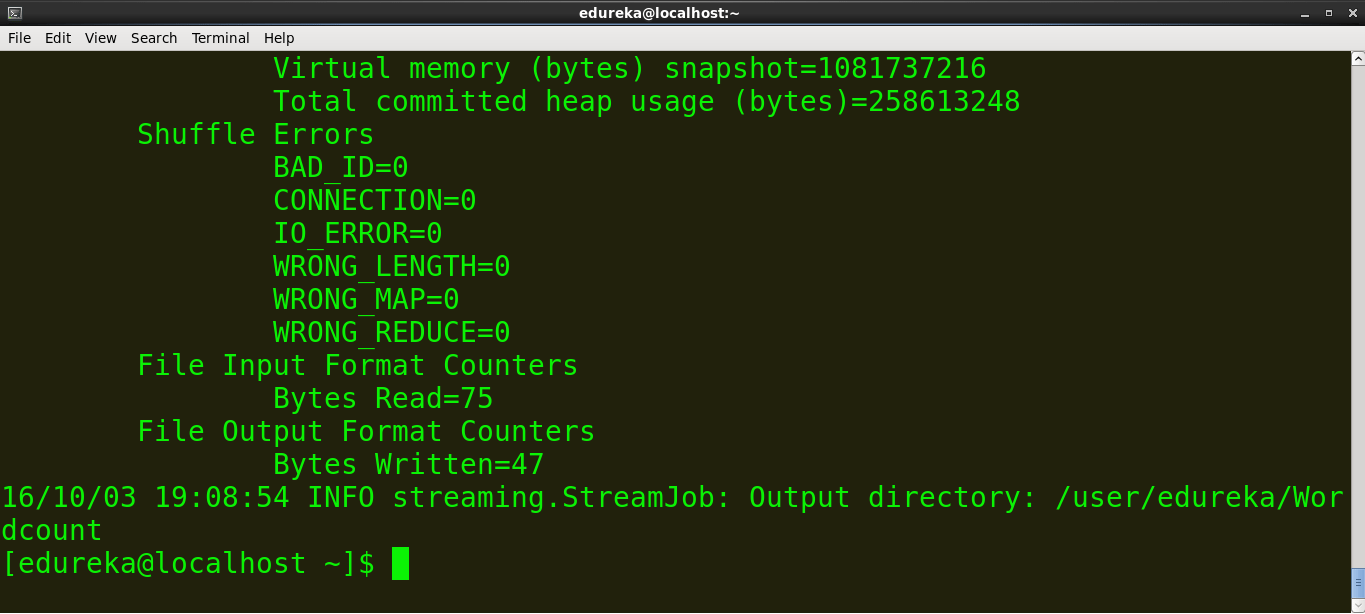
Hadoop provides a basic web interface for statistics and information. When Hadoop cluster is running open http://localhost:50070 in browser. Here is the screenshot of the Hadoop web interface.
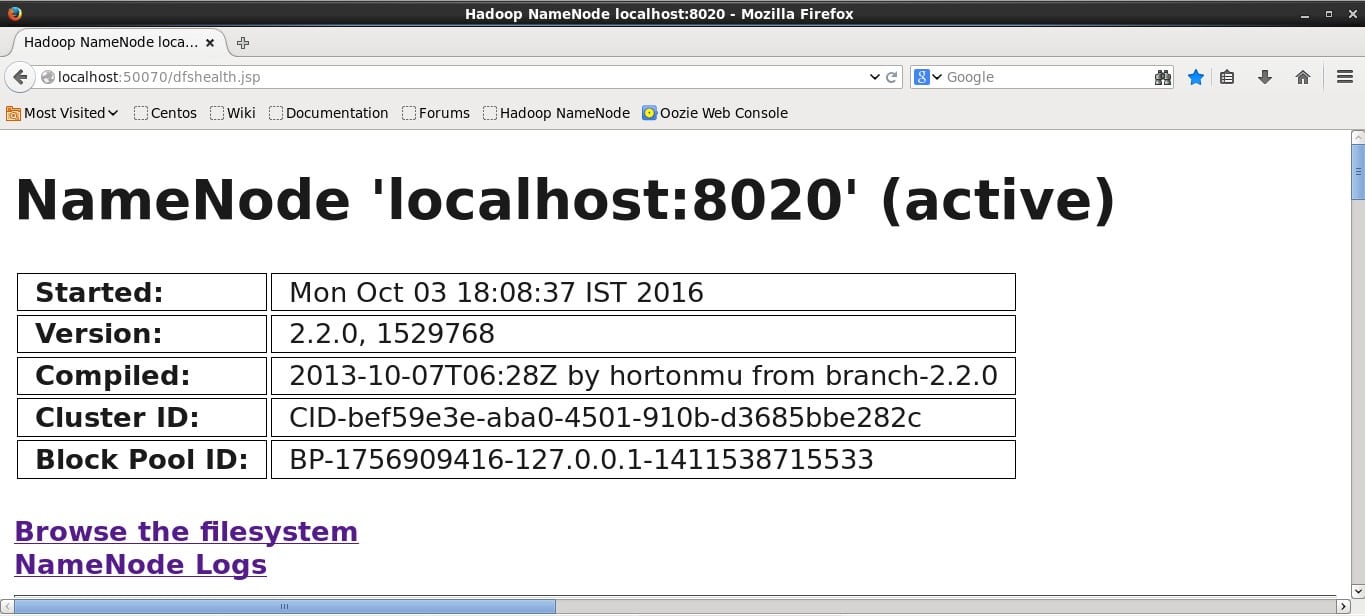
Now browse the filesystem and locate the wordcount file generated to see the output. Below is the screenshot.
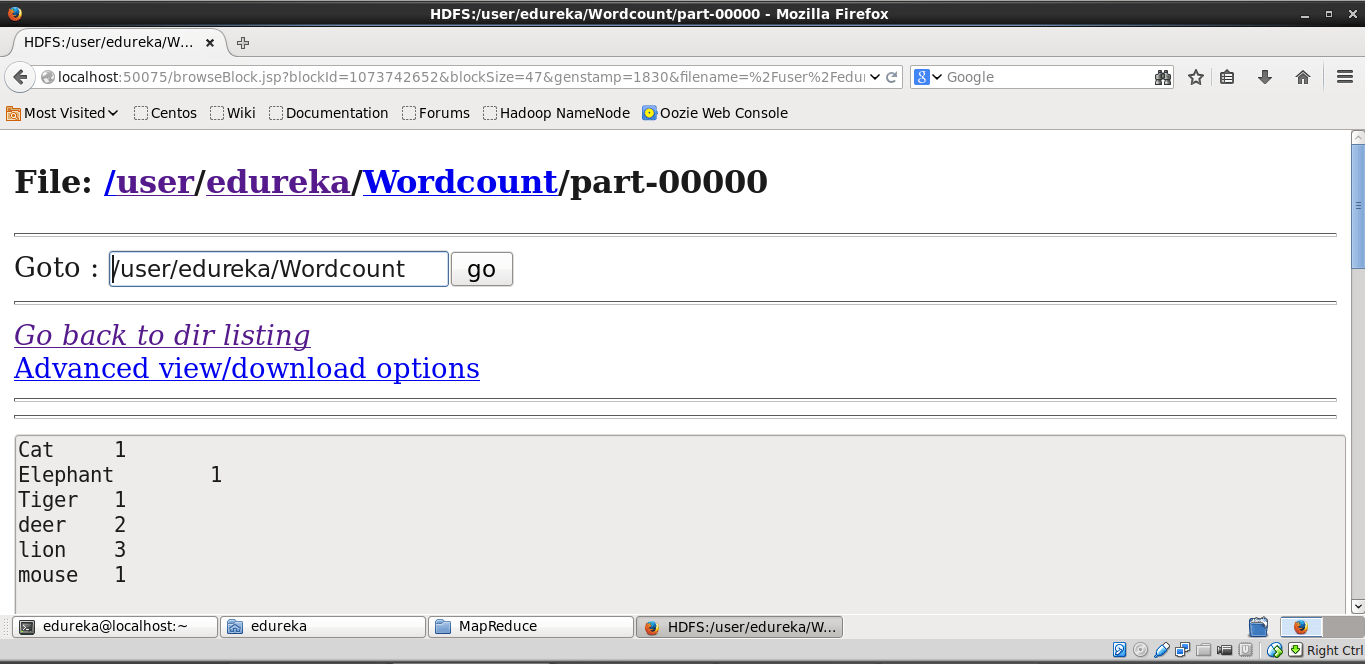
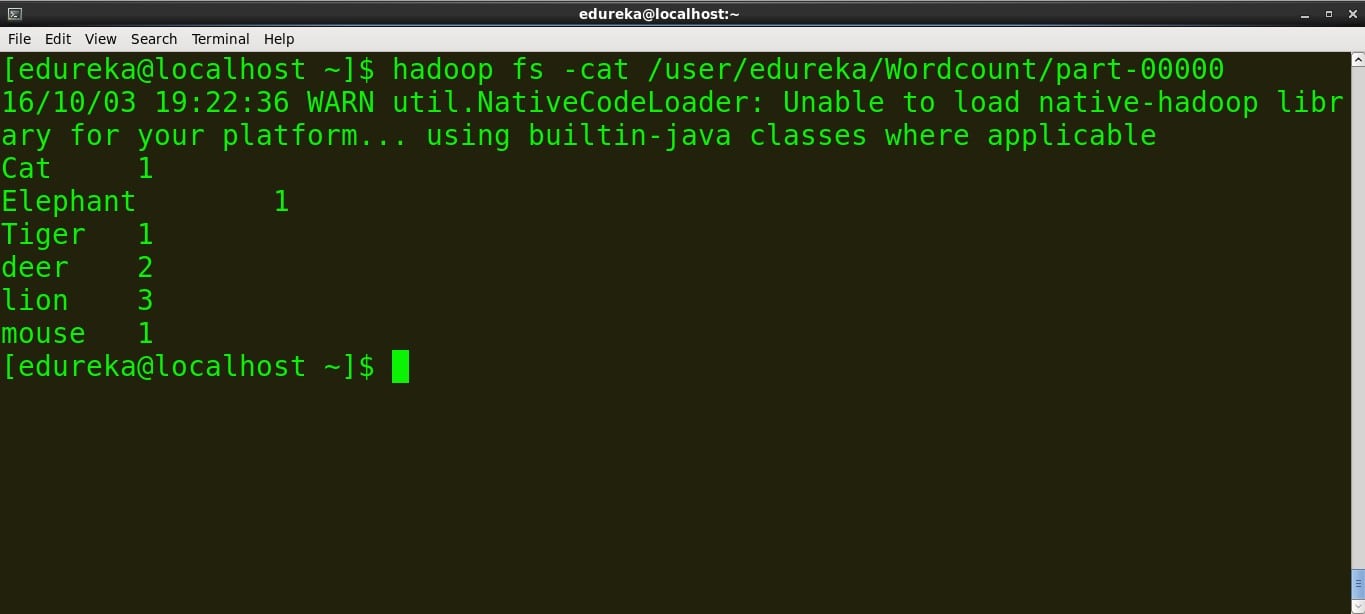
We can see the output on the terminal using this command
command: hadoop fs -cat /user/edureka/Wordcount/part-00000
You have now learnt how to execute a MapReduce program written in Python using Hadoop Streaming!
Edureka has a live and instructor-led course on Big Data & Hadoop, co-created by industry practitioners to get Big Data Certifications.The Edureka’s Big Data Masters Course helps learners become expert in HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume and Sqoop using real-time use cases on Retail, Social Media, Aviation, Tourism, Finance domain.
Got a question for us? Please mention it in the comments section and we will get back to you.





































Thanks for the detailed explanation. The part where we run the mapreduce job, hadoop streaming.jar file, there is an error pop up. https://uploads.disquscdn.com/images/40371036049c6f2099171b982c1cffc15e1661ca465dc2644d9349f731412f2b.png
Can someone help me with this.
TIA
how to subscribe blog .. for the daily update?
Nice Blog! I’m doing my college project on mapreduce wordcount… Could you please suggest me an idea where I can make the use of wordcount program? And where to get the large data from to perform the mapreduce wordcount.. I’m using cloudera on virtual box. Thank you very much!
Nice description of the topic !!!
Thanks for checking out the blog, Ajay! Do subscribe to our blog to stay updated on upcoming Hadoop posts. Cheers!
nice blog !!!
Thanks, Gopesh! Do subscribe to our blog to stay updated on upcoming Hadoop posts. Cheers!