In the current market, data is increasing at a potential rate. Thus creating a huge demand for processing a high volume of data in a quick time. Hadoop is that kind of technology processing large volumes of data. In this article we will discuss Hadoop for Data Science in the following order:
- What is Hadoop?
- Do we need Hadoop for Data Science?
- Use of Hadoop in Data Science
- Data Science Case Study
What is Hadoop?
Hadoop is an open-source software that refers to data sets or combinations of data sets whose size (volume), complexity (variability), and rate of growth (velocity) make them difficult to be gather, managed, processed or analyzed by traditional technologies and tools, such as relational databases and desktop statistics or visualization packages, within the time necessary to make them useful.
What are the Components of Hadoop?
Hadoop Distributed File System (HDFS): It distributes the data and store in the distributed file system called HDFS (Hadoop Distributed File System).Data is spread among machines in advance.No data transfer over the network is required for initial processing. Computation happens where the data is stored, wherever possible.
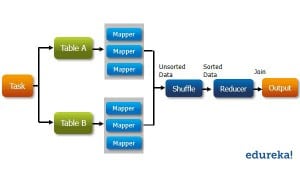
Map-Reduce (MapR): It is used for high-level data processing. It processes a large amount of data over the cluster of nodes.
Yet Another Resource Manager (Yarn): It is used for Resource Management and Job Scheduling, in the Hadoop Cluster. Yarn allows us to control and manage Resources effectively.
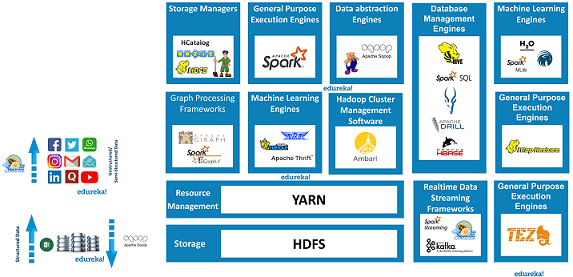
Do we need Hadoop for Data Science?
For this first, we need to understand is What is Data Science?
Data science is a multi-disciplinary field that uses scientific methods, processes, algorithms, and systems to extract knowledge and insights from structured and unstructured data. Data science is the concept combined of data mining and big data. “uses the most powerful hardware, and best programming systems, and the most efficient algorithms to solve problems”.

However, the main difference between data science and big data is that Data Science is a discipline that involves all the data operations. As a result, Big Data is a part of Data Science. Further to this, as a Data scientist, knowledge of Machine Learning (ML) is also required.
Hadoop is a big data platform that is used for data operations involving large scale data. In order to take your first step towards becoming a fully-fledged data scientist, one must have the knowledge of handling large volumes of data as well as unstructured data.
Therefore, learning Hadoop will provide you with the capability to handle diverse data operations which is the main task of a data scientist. Since, it includes a majority portion of Data Science, learning Hadoop as an initial tool to provide you all the necessary knowledge.
In the Hadoop ecosystem, writing ML code in Java over MapR becomes a difficult procedure. Doing ML operations like Classification, Regression, Clustering into a MapR framework becomes a tough task.
In order to make it easy for analyzing data, Apache released two components in Hadoop called Pig and Hive. With this ML operation on the data, the Apache software foundation released the Apache Mahout. Apache Mahout runs on the top of Hadoop that uses MapRe as its principle paradigm.
A Data Scientist needs to use all the data related operations. Hence, having expertise at Big Data and Hadoop will allow developing a good architecture analyzes a good amount of data. You can even check out the details of Big Data with the Azure Data Engineer Course.
Use of Hadoop in Data Science
1) Engaging of Data with Large dataset:
Earlier, data scientists are having a restriction to use datasets from their Local machine. Data Scientists are required to use a large volume of data. With the increase in data and a massive requirement for analyzing it, Big dat and Hadoop provides a common platform for exploring and analyzing the data. With Hadoop, one can write a MapR job, HIVE or a PIG script and launch it onto Hadoop over to full dataset and obtain results.
2) Processing Data:
Data Scientists are required to use the most of data preprocessing to be carried out with data acquisition, transformation, cleanup, and feature extraction. This is required to transform raw data into standardized feature vectors.
Hadoop makes large scale data-preprocessing simple for the data scientists. It provides tools like MapR, PIG, and Hive for efficiently handling large scale data.
3) Data Agility:
Unlike traditional database systems that needs to have a strict schema structure, Hadoop has a flexible schema for its users. This flexible schema eliminates the need for schema redesign whenever a new field is needed.
4) Dataset for Datamining:
It is proven that with larger datasets, ML algorithms can provide better results. Techniques like clustering, outlier detection, product recommenders provide a good statistical technique.
Traditionally, ML engineers had to deal with a limited amount of data, which ultimately resulted in the low performance of their models. However, with the help of the Hadoop ecosystem that provides linear scalable storage, you can store all the data in RAW format. You can even check out the details of Big Data with the Data Engineering Training in Atlanta.
Data Science Case Study
H&M is a major multinational cloth retail company. It has adopted Hadoop to have in-depth insight into customer behavior. It analyzed data from multiple sources thereby giving a comprehensive understanding of consumer behavior. H&M manages the efficient use of data to grasp customer insights.
It adopted a complete 360-degree view to have a comprehensive understanding of the customer purchase patterns and shopping across multiple channels. It makes the best use of Hadoop to not only store massive amounts of information but also analyzes it to develop in-depth insights about the customers.

During peak seasons like Black Friday, where stocks often get depleted, H&M is using big data analytics to track the purchasing patterns of the customers in order to prevent that from happening. It uses an effective data visualization tool to analyze data. Thus, creating conjunction of Hadoop and Predictive Analytics. Hence, we can realize that big data is one of the core components of data science and analytics.
Further to it, H&M has become one of the first industries to have a data-literate workforce. In one of the first initiatives, H&M is educating its employees about Machine Learning & Data Science for better results in its day-to-day business and thus grow their profits in the market. Which makes the future of Data science a unique career to opt for, and to contribute more to the Data Analytics and Big Data field. This is the best opportunity to kick off your career in the field of data science by taking the Data Scientist Course.
To conclude Hadoop for Data Science is a must. With this, we come to an end of this Hadoop for Data Science article. I hope all your doubts have now been cleared. Enroll for the Data Science Program by IIT Guwahati, a Post Graduate program by Edureka, to elevate your career.
The need for Data Science with Python programming professionals has increased dramatically, making this course ideal for people at all levels of expertise. The Python for Data Science course Online is ideal for professionals in analytics who are looking to work in conjunction with Python, Software, and IT professionals interested in the area of Analytics and anyone who has a passion for Data Science.
Got a question for us? Please mention it in the comments section of this “Hadoop for Data Science” article and we will get back to you.